
多专家模型 (MoE) 已迅速成为现代大规模 AI 系统的基础组件。它们之所以得到广泛采用,是因为它们能够显著提高模型容量,同时仅为每个 token 激活一个参数子集,从而在实际计算预算内提供无与伦比的性能扩展方法。随着模型规模的持续增长,优化这些模块对于更大限度地提高训练吞吐量至关重要。
为了突破这些界限,我们推出了适用于密集模型和 MoE 模型的先进融合 MLP 内核,这些内核使用 NVIDIA CuTe DSL 进行定制构建。通过解决固有内存和同步瓶颈,这些新的内核可在未融合的路径上实现 1.3 倍至 2 倍的惊人内核级加速,同时为全迭代 NVIDIA CUDA 计算图实现无同步 MoE 执行。
在 NVIDIA 全栈 DeepSeek-V3 预训练设置中,此优化可将端到端性能提升 8%。同样,对于 GPT-OSS 预训练设置,此优化可将端到端性能提升 93%。无论您是想缩短训练时间还是优化硬件利用率,这些内核现在都可以在 NVIDIA cuDNN 前端中使用,并且可以通过 NVIDIA Transformer 引擎和 NVIDIA Megatron-Core 无缝访问。
要了解如何做到这一点,我们需要系统地研究如何消除困扰现代 MoE 模块的三大瓶颈,以及如何通过硬件感知软件协同设计来重新设计堆栈,以保持 Tensor Core 的持续馈送。
克服 MoE 模块中的训练瓶颈
为了更大限度地提高 MoE 模型的吞吐量,我们首先必须准确规划计算周期的使用位置。在 MoE 模块中分析标准训练迭代的执行时间轴时,我们发现了三个系统级瓶颈:
- 激活瓶颈:激活函数通常会导致受内存限制的内核和大量张量读/ 写操作,导致 Tensor Core 在这些间隔期间未得到充分利用。
- CPU 边界/ 开销: 对于路由专家,每个专家的 token 在运行时计算,通常在 CPU 上计算。如果 CPU 无法跟上 GPU 的运行速度,则会公开 CPU 操作。这就需要构建不需要 CPU 同步或干预的内核。
- 量化成本: 与激活函数一样,从高精度到低精度对张量进行量化会导致内存受限的核函数保持 Tensor Core 空闲状态。
我们使用使用 cuTE DSL 编写的自定义内核,在重新设计 MoE 模块时解决了这些挑战,并介绍了为无同步 MoE 编写的三个内核系列:
- GroupGemm 量化
- GroupGemm+ 激活+ 量化/ 转置
- GroupGemm+ dActivation+ 量化/ 转置
受支持的激活函数包括 SwiGLU、GeGLU、sReLU,以及添加夹紧和缩放的选项。
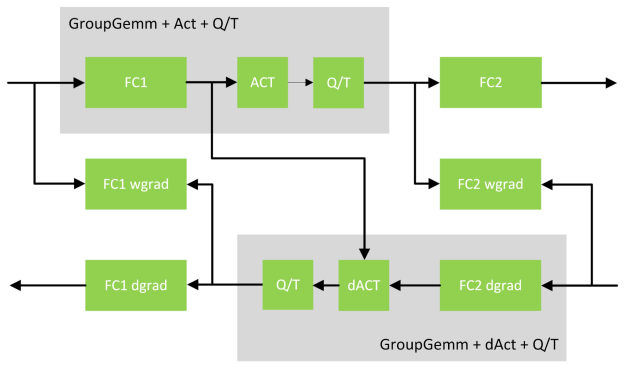
通过融合的 GEMM 结语优化 GLU 激活函数
门控线性函数最近变得非常流行,大多数现代模型都使用门控线性单元 (GLU) 激活函数的一些变体,例如 SwiGLU、GeGLU 等。这些激活函数将 FC1 层的输出分块,并将其组合起来以编写最终的 GLU 输出。我们实现了融合内核,该内核可在前向属性和后向属性中无缝合并 GEMM 与相应的 GLU 操作。
\(\text{SwiGLU}(x, W, V, b, c\beta)=\text{Swish}_{\beta}(xW + b) \otimes (xV + c)\)
在 GEMM 的后记中,GLU 激活函数并非易事,因为 GLU 需要访问两个不同的张量块:输入和门。通常,这两个数据块将由不同的线程块计算,为了组合这两个输出,内核需要将这两个输出写入全局内存。为了实现这种融合,我们将权重重新打包成输入和门的列。这可确保同一线程块能够同时访问输入张量的半平铺宽度和门张量的半平铺宽度。这使得输入和门可以在结语中合并,而无需访问全局内存。重新打包可以在训练开始之前进行,即在检查点加载期间进行。
同样,在反向属性中,epilog 会读取 GEMM 输出,计算 dSwiGlu,对其进行量化,然后将其写回全局内存。
值得注意的是,这些融合模式不仅消除了中间张量的读取和写入,还通过将任何剩余内存操作直接与 GEMM 本身重叠来更大限度地提高利用率。
除了 SwiGLU、GeGLU 和 sReLU 等核心激活函数之外,这些内核还原生处理融合的结语运算,包括特征缩放、张量制和偏差向量添加 。
消除主机设备同步和 CPU 启动用度
传统上,核函数执行的工作量由启动时的块数量定义,这需要在主机上提供形状信息。例如,多流分组 GEMM 会在单独的流上启动 \(G\) 不同的 GEMM,其中 \(G\) 是组的数量。由于每个组的 token 数量是在运行时确定的,因此 CPU 必须在单独的流上启动这些动态大小的 GEMM,以更大限度地提高资源利用率。
这主要会导致两个问题:首先,要启动的内核数量会随着本地专家的数量而增加;其次,在启动内核之前,必须设置同步点才能在主机上检索形状信息。为应对这些挑战,CuTe DSL GroupGEMM 内核会在 GPU 显存中追踪每个组的 token。这消除了迭代期间对 CPU 的依赖,并在整个迭代中启用 CUDA 计算图,从而有效地消除了 CPU 瓶颈。
融合 MXFP8 和 NVFP4 量化,减少显存占用
用于预训练的低精度方案 (例如 MXFP8 和 NVFP4) 越来越受欢迎,这些精度可在大幅加速的同时将对准确性的影响降至最低。在这些低精度配方中,激活函数之后是量化和转置,用于窄精度 GEMM 运算。
对于 MXFP8,量化内核会读取激活函数 (BF16) 的输出,并为反向道具写入 MXFP8 输出和转置版本的输出。我们新设计的内核将此量化步骤融入 GEMM 内核本身,从而消除了 BF16 张量的额外读写。同样,对于 NVFP4,内核会为前向道具生成 BF16 输出和每张量最大值 (数组最大值) ,而对于后向道具,内核会计算输出转置 Hadamard 旋转的最大值。这消除了对每个张量最大值计算的额外内存传递需求。
从内核级提升到预训练加速
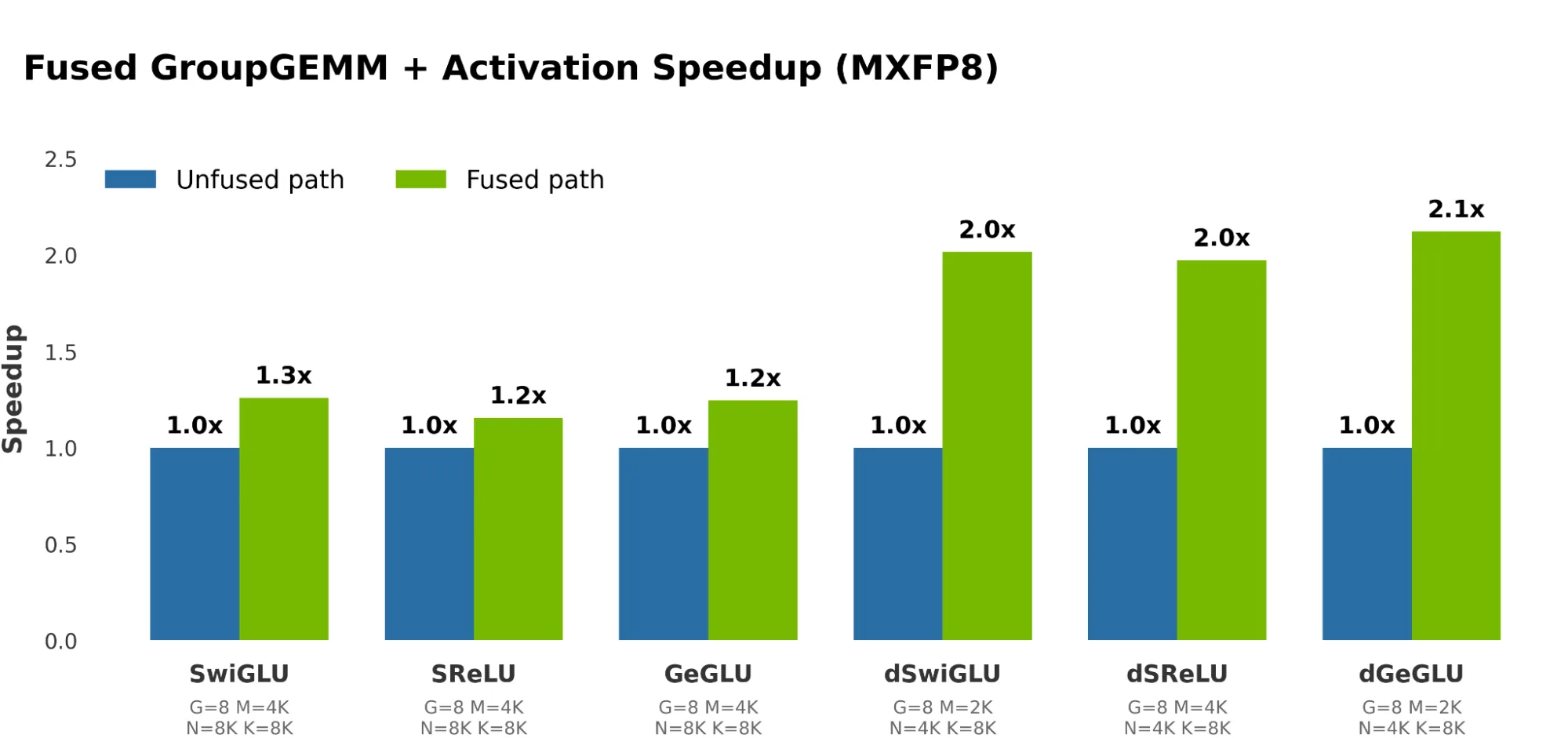
在单元级微基准测试中,这些融合的内核可实现显著加速,与传统的非融合执行路径相比,前向传递和反向传递分别可分别提升1.3倍和2.1倍。
为了将这些加速转化为端到端训练吞吐量提升,它们还支持以下功能:
- 动态调度,支持与其他内核进行高效重叠,例如通过专家并行、数据并行等进行通信。
- 可配置集群边距,通过将内核限制为更少的 SM,使用户能够保留 SM 资源的可配置边距,从而为其他内核在 GPU 上同时启动和执行留出空间。
除了每个内核的加速之外,由于这些无同步的内核支持端到端 CUDA 计算图并与通信内核进行高效重叠,因此在整个应用程序级别上的加速要大得多。在内部测试中,我们发现通过这些优化,Deepseekv3 上的端到端加速提升高达 8%,GPT-OSS 预训练上的端到端加速提升高达 93%。
我们会不断添加新的内核,并为这些内核提供新功能支持。
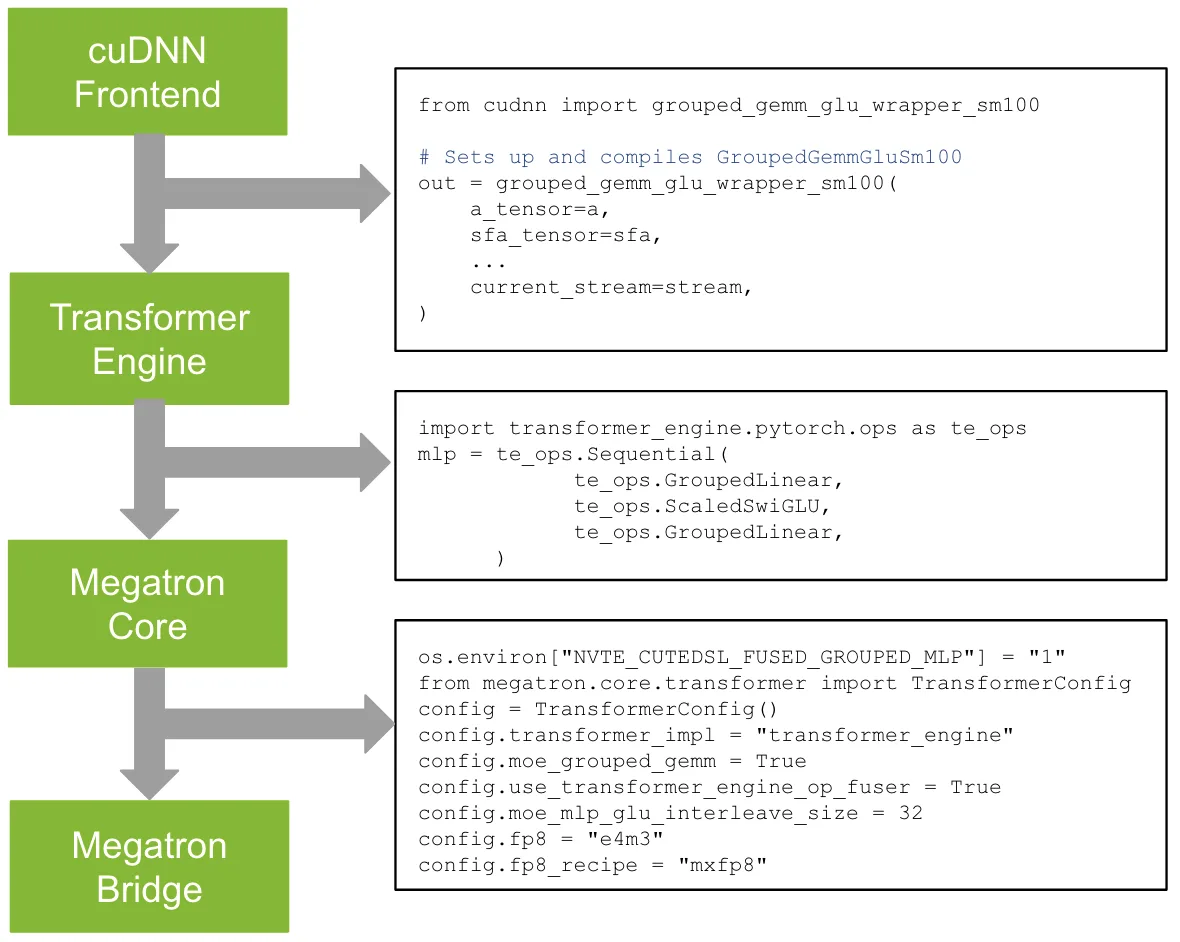
如何使用融合了 CuTe DSL 的内核来发挥您的优势
这些内核可用于不同的抽象级别。
- cuDNN 前端 (v1.23.0+): 内核位于 cuDNN 前端 库中。用户可以在其软件堆栈中安装库,并直接从那里调用这些内核。CudNN-Frontend 还为这些内核提供了一个封装器,用于在首次调用时编译内核,然后在后续调用中重复使用缓存对象。用户可以选择直接调用内核或通过包装器 API 访问内核。我们还积极致力于将 AOT (提前) 编译支持引入这些内核的库,以便将内核编译为 cubin 并缓存在磁盘中。
- Transformer 引擎 (v2.15+) : 用户还可以通过 Transformer 引擎使用这些内核。Transformer 引擎通过
transformer_engine.pytorch.ops结构公开这些操作。这些操作可以使用transformer_engine.pytorch.ops.Sequential块进行组合,该块的内部模式与操作相匹配,以便从 cuDNN 前端库中调用融合后的内核。 - Megatron Core (26.04-alpha.rc2+): :用户还可以通过 Megatron Core 使用这些内核,只需使用一组正确的旋钮即可调用这些特征。
下一步是什么?
我们正在积极开发多项新功能,例如支持更多融合模式,以及支持 JAX 等更多框架。
目前正在进行多种内核优化,例如激活重新计算、用于选择最佳内核进行编译的启发式方法、用于降低编译成本的提前编译 (AOT) 、减少 CPU 开销等。
如果您有想要的激活函数,我们鼓励用户调整 CuDNN 内核,并通过 PR 本身做出贡献。或者,请添加问题,以便我们在 cuDNN 前端中跟踪该功能。非常欢迎社区反馈!
开始使用
请按照 GitHub 上的步骤操作,了解如何运行这些内核。