
NVIDIA H100 TensorCore GPU 基于 NVIDIA Hopper 架构 和第四代 NVIDIA Tensor Cores ,最近推出了 提供前所未有的性能 和 全面的 AI 基准 ,如 MLPerf training 。
人工智能和机器学习基准测试中相当一部分操作是 通用矩阵乘法 ,也称为 matmul 函数。 GEMs 也存在于深度学习训练的前向和后向通道以及推理中。
GEMM 的突出性使得深度学习软件能够最大限度地利用用于矩阵乘法的硬件,同时支持几个关键的 AI 组件。这些成分包括具有偏置和流行激活功能的融合体及其衍生物。
本文探讨了 NVIDIA cuBLAS 库 在里面 CUDA 12.0 重点是最近推出的 FP8 format 、 NVIDIA Hopper 上的 GEM 性能 GPU ,以及新 64 位整数应用程序编程接口 ( API )和新融合等用户体验的改进。
在深入了解这些功能之前,简要概述了当前可用的 cuBLAS API 、如何更有效地应用每种 API ,以及 cuBLAS 与其他可用的 NVIDIA 矩阵乘法工具的关系。
确定要使用的 cuBLAS API
cuBLAS 库是在 NVIDIA CUDA 运行时之上的基本线性代数子程序( BLAS )的一种实现,旨在利用 NVIDIA GPU 进行各种矩阵乘法运算。本文主要讨论 cuBLAS 和 cuBLASLt API 的新功能。然而, cuBLAS 库还提供了针对多 GPU 分布式 GEMs 的 cuBLASXt API 。 cuBLASXt API 将于 2023 年在 Early Access 中提供,目标是 GEMs 及其设备内融合功能。
表 1 概述了每种 API 的设计用途以及用户可以在哪里获得最佳性能。
| API | API complexity | Called from | Fusion support | Matrix sizes for maximum performance |
| cuBLAS (since CUDA 6.0) |
Low | Host | None | Large (global memory) |
| cuBLASXt (since CUDA 6.0) | Low | Host | None | Very Large (multi-GPU, global memory) |
| cuBLASLt (since CUDA 10.1) |
Medium | Host | Fixed set | Medium (global memory) |
| cuBLASDx (targeting 2023 EA) | Medium/High | Device | User ops | Small (shared memory) |
cuBLAS API
cuBLAS API 在所有三个级别实现 NETLIB BLAS 规范,每个例程最多有四个版本:实数单精度、实数双精度、复数单精度和复数双精度,分别带有 S 、 D 、 C 和 Z 前缀。
对于 BLAS L3 GEMM ,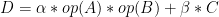

cuBLASLt API
cuBLASLt API 是一个比 cuBLAS 更灵活的解决方案,专门为人工智能和机器学习中的 GEMM 操作而设计。它通过以下选项的参数可编程性提供灵活性:
- 矩阵数据布局
- 输入类型
- 计算类型
- 结语
- 算法实现选择
- 启发式
一旦用户确定了预期 GEM 操作的一组选项,这些选项就可以重复用于不同的输入。简而言之,与 cuBLAS API 相比, cuBLASLt 可以支持复杂的情况,例如:
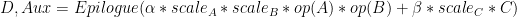
该案例有多个输出,是基于变压器的模型中遇到的一个突出的 GEMM .
为了提供最近的示例, a 和 B 可以采用两种新的 FP8 格式中的任一种,并在 FP32 中进行乘法和累加。 Epilogue 可以包括 GELU 和偏倚,偏倚在 BF16 或 FP16 中。许多常见的尾声现在都融入了 matmul 。此外,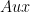
NVIDIA 切割机和 GEMS
作为最著名的开源 NVIDIA 库之一, NVIDIA CUTLASS 还为 NVIDIA GPU 上的 GEMM (和卷积)提供 CUDA C ++和 Python 抽象,并在设备、块、扭曲和线程级别提供原语。 CUTRASS 的一个优点是,用户可以专门为其所需范围编译 GEMs ,而无需像 cuBLAS 库那样加载更大的二进制文件。
当然,这会带来性能上的权衡,因为需要大量的努力来为每个单独的用例找到和实例化最佳内核。 cuBLAS 库通过广泛训练的启发式方法,在广泛的问题范围内提供最大的性能。
事实上,对于许多用例和数据类型, cuBLAS 可能包括从 CULASS 实例化的几个内核。通常, cuBLAS 使用各种内核源,以确保在应用程序之间更均匀地实现最大性能。
NVIDIA Hopper 上的 FP8 支持
首次在 CUDA 18.1 中引入, FP8 是 16 位浮点类型的自然发展,减少了 神经网络训练的记忆和计算要求 。此外,由于其对实数的非线性采样,与 int8 相比, FP8 在推理方面也具有优势。
FP8 由两种编码 E4M3 和 E5M2 组成,其中名称明确表示指数( E )和尾数( M )位数,符号位隐含。在 CUDA C ++中,这些编码公开为 __nv_fp8_e4m3 和 __nv_fp8_e5m2 类型。 NVIDIA Hopper Tensor Core 支持 FP16 和 FP32 累积的 FP8 矩阵产品。
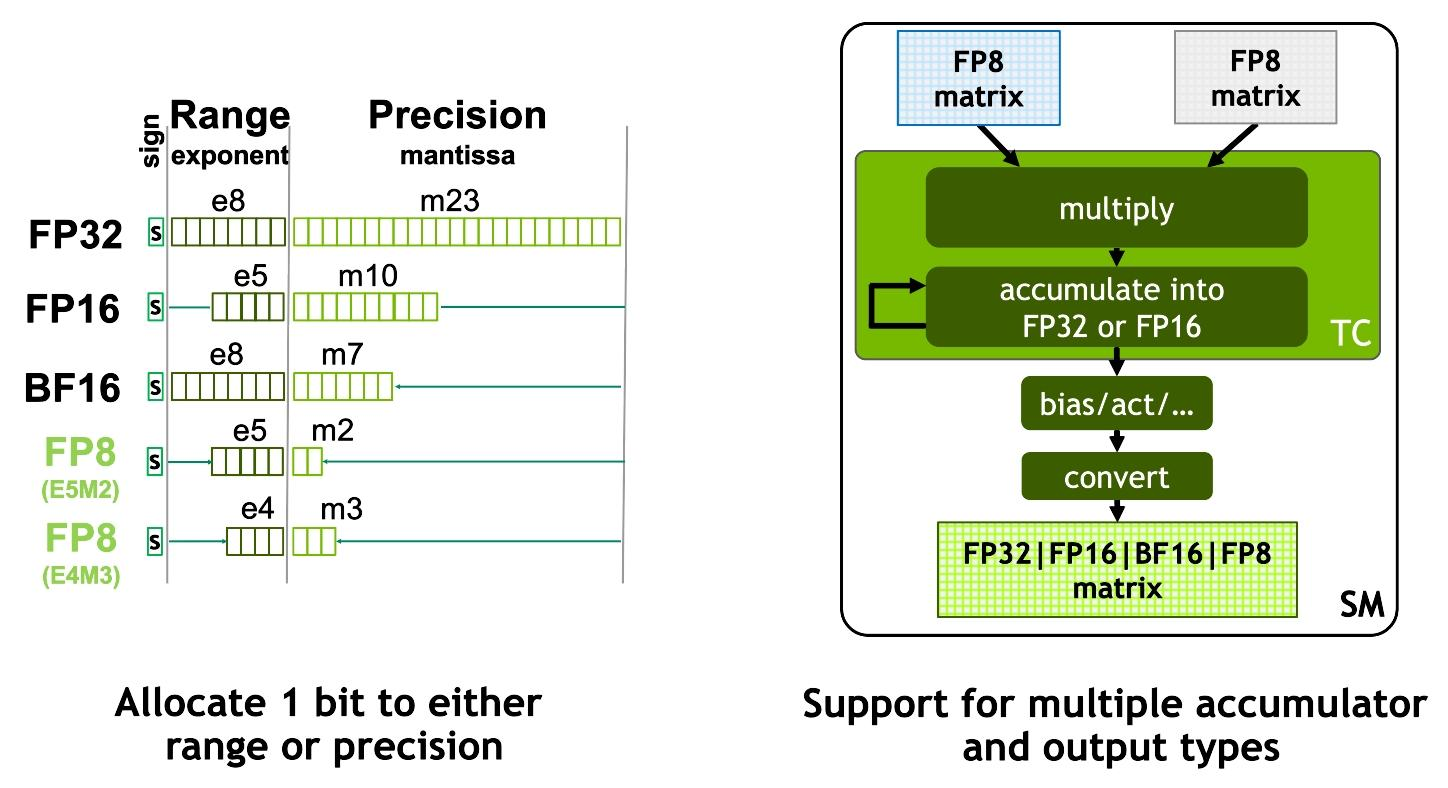
在 CUDA 12.0 (以及 CUDA 11.8 )中, cuBLAS 提供了多种 matmul 操作,支持具有 FP32 累积的 both encodings 。(有关完整列表,请参见 cuBLAS 文档 .) FP8 matmul 操作还支持附加的融合操作,这些操作对于使用 FP8 进行训练和推理非常重要,包括:
- 除了传统的 alpha 和 beta 外, A 、 B 、 C 和 D 矩阵的每矩阵比例因子
- 输出矩阵的绝对最大值计算
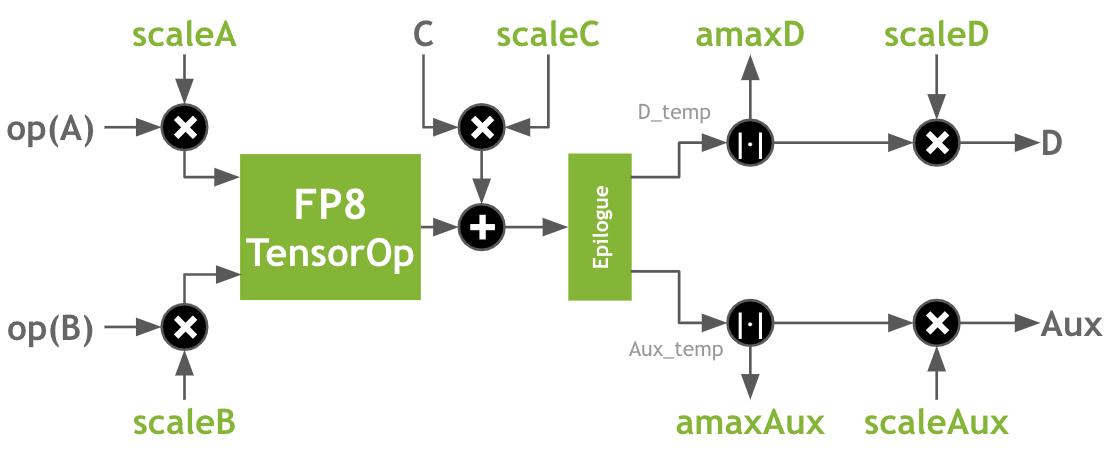
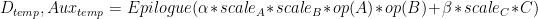
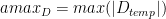
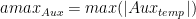
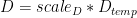



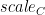

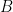
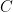
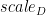
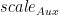
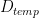

请注意,所有比例因子都是乘法应用的。这意味着有时需要根据应用的上下文使用缩放因子或其倒数。缩放因子和矩阵之间的乘法的特定顺序无法保证。
cuBLAS 12.0 performance on NVIDIA H100 GPU
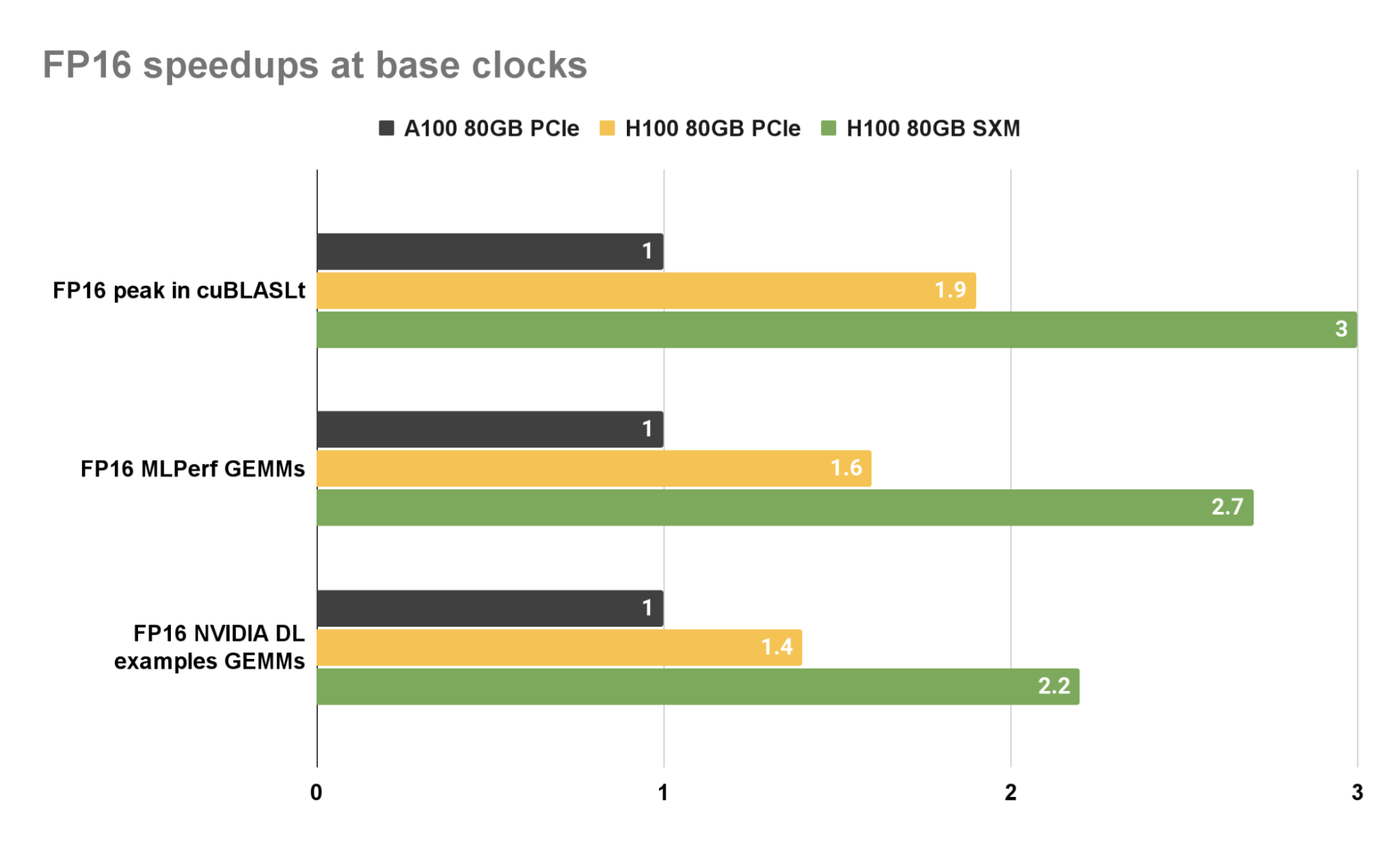
我们比较了 H100 PCIe 和 SXM (预览版)与 A100 ( PCIe )上 FP16 、 BF16 和 FP8 GEMM 在三种情况下的基本时钟性能: cuBLAS 库对于大矩阵大小的峰值性能,以及 MLPerf 和 NVIDIA 深度学习示例 中存在的 GEMM 。
大型 GEMM 表现出较大的算术强度,因此受到计算限制。当标准化为 A100 时,加速因子接近于 GPU 对之间基础数据类型的峰值性能比率。对于计算绑定的 FP16 GEMM , cuBLAS 库在 H100 SXM 上实现了相对于 A100 的三倍加速。
另一方面, MLPerf 和 NVIDIA DL 示例由跨越一系列算术强度的 GEMM 组成。有些距离计算范围较远,因此表现出比大型 GEMs 更小的加速。对于 MLPerf 和 NVIDIA DL 示例中的 GEMs , cuBLAS 库在 H100 SXM 上分别实现了 2.7 倍和 2.2 倍的加速。
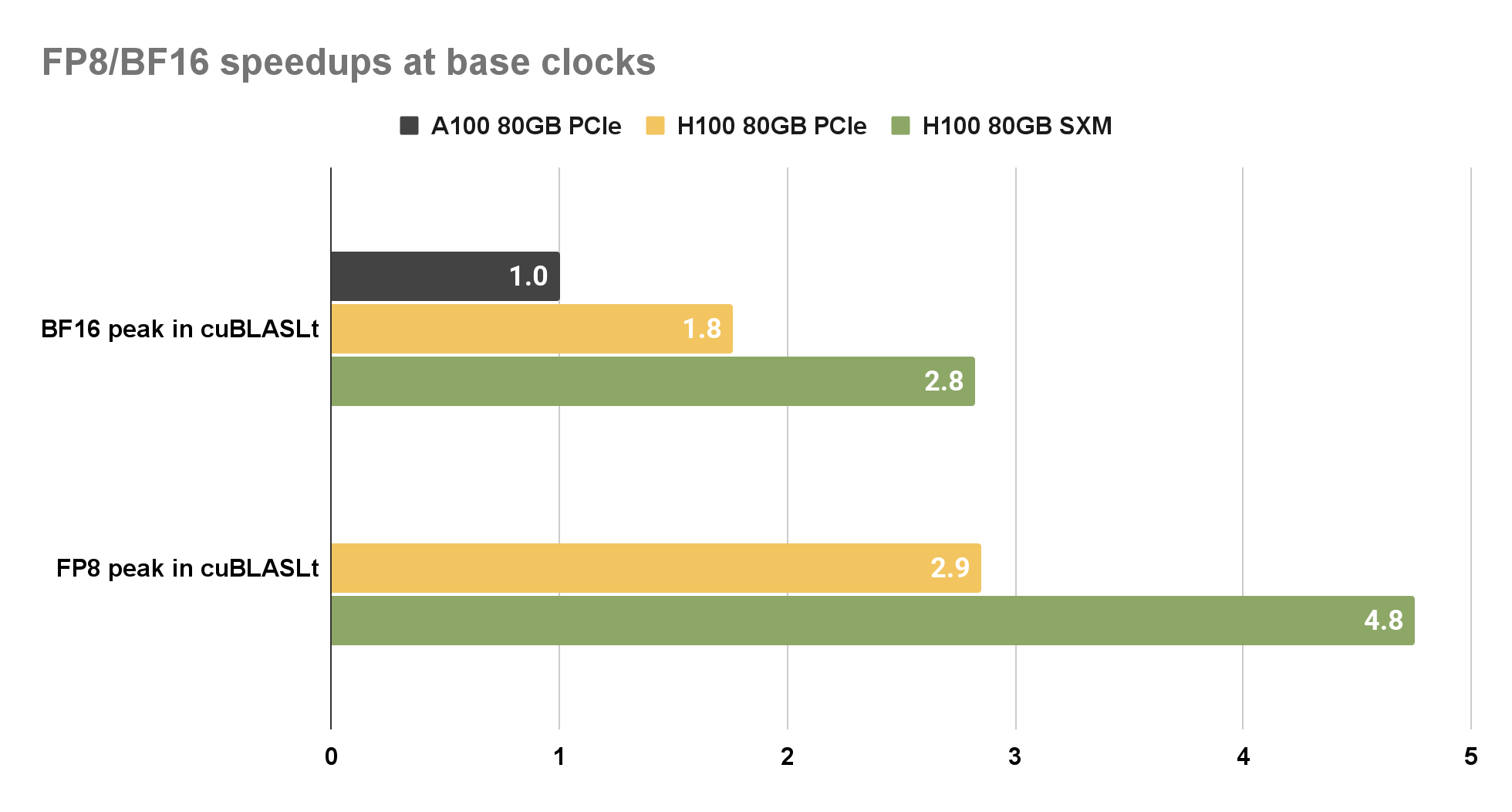
为了比较 H100 上的 FP8 和 BF16 性能,我们选择 A100 上的 BF16 作为基线。之所以选择此选项,是因为 FP8 支持仅在 NVIDIA Hopper 架构上可用。与 A100 PCIe 上的 BF16 相比, cuBLAS 库在 H100 SXM 上为 BF16 和 FP8 提供了近 2.8 倍的加速。
NVIDIA Hopper 架构工作空间要求
H100 原生内核增加了对工作空间大小的需求。因此,强烈建议为 cuBLASLt 调用或使用 cublasSetWorkspace 时提供至少 32 MiB ( 33554432 B )的工作空间。
cuBLAS 用户体验的改进
- cuBLAS 12.0 启用了新的 FP8 和 FP16 / BF16 融合外延。在 NVIDIA Hopper 上, FP8 融合现在提供偏置( BF16 和 FP16 )、 ReLU 和 GELU ,以及辅助输出缓冲器和辅助输出缓冲器。新的 FP16 融合器还可用于 NVIDIA Hopper 的偏置、 ReLU 和 GELU 、 dBias 和 dReLU 。对于 NVIDIA Ampere 架构,单核、更快的 BF16 融合(带有偏置和 GELU )以及 dBias 和 dGELU 现在已经公开。
- Heuristics cache 允许将 matmul 问题映射到先前通过启发式选择的内核。这有助于减少重复 matmul 问题的主机端开销。
- cuBLAS 12.0 扩展了 cuBLAS API ,以支持 64 位整数问题大小、前导维数和向量增量。这些新函数与 32 位整数对应函数具有相同的 API ,不同之处在于它们的名称中有
_64后缀,并将相应的参数声明为int64_t。
例如,对于经典的 32 位整数函数:
cublasStatus_t cublasIsamax( cublasHandle_t handle, int n, const float *x, int incx, int *result);64 位整数对应项是:
cublasStatus_t cublasIsamax_64( cublasHandle_t handle, int64_t n, const float *x, int64_t incx, int64_t *result);性能是 cuBLAS 的主要关注点,因此当传递给 64 位整数 API 的参数符合 32 位范围时,库将使用与用户调用 32 位整数 API 相同的内核。要尝试新的 API ,迁移应该像向 cuBLAS 函数添加_64后缀一样简单,这要归功于 C / C ++将int32_t值自动转换为int64_t。
cuBLAS 12.0 和 NVIDIA Hopper GPU
本文介绍了 CUDA API 的财产以及 cuBLAS 12.0 中 cuBLAS 库提供的新特性。特别是,它讨论了 FP8 的功能和融合的尾声,并重点介绍了 NVIDIA Hopper GPU 上的库的性能改进,以及与 AI 框架相关的示例。最后,它详细介绍了对用户体验的改进,如 cuBLAS API 中对int64维度的支持、未来的硬件回退以及主机端开销的进一步减少。
要了解有关 cuBLAS 更新的更多信息,请参阅 cuBLAS 文档 .