
开源生成式 AI 模型的迅猛发展正在推动数据中心向物理世界中运行的机器迈进。开发者渴望在边缘部署这些模型,使物理 AI 智能体和自主机器人能够自动执行繁重的任务。
关键的挑战在于如何在内存受限的边缘设备上高效运行包含数十亿个参数的模型。在内存供应持续受限和成本上升的情况下,开发者正专注于用更少的资源取得更多的成果。
NVIDIA Jetson 平台支持热门开放模型,同时在边缘提供强大的运行时性能和内存优化。对于边缘开发者而言,显存占用决定了系统是否正常运行。与云环境不同,边缘设备在严格的内存限制下运行,CPU 和 GPU 共享资源受限。
内存使用效率低下可能会导致瓶颈、延迟峰值或系统故障。与此同时,现代边缘应用通常会运行多个流程 (例如检测、跟踪和分割) ,这使得高效的内存管理对于在功耗和散热受限的情况下实现稳定的实时性能至关重要。
优化显存占用具有明显优势。开发者可以通过减少开销和增加并发性来提高相同硬件的性能,同时支持更复杂的工作负载,如 LLM、多摄像头系统和传感器融合。它还通过适合较小的内存配置来降低系统成本,并通过最大限度地减少瓶颈和最大限度地提高 GPU 利用率来提高效率 (每瓦性能) 。
本博客将探讨各种优化策略,以帮助开发者在资源受限的边缘系统上更大限度地提高性能、效率和功能。
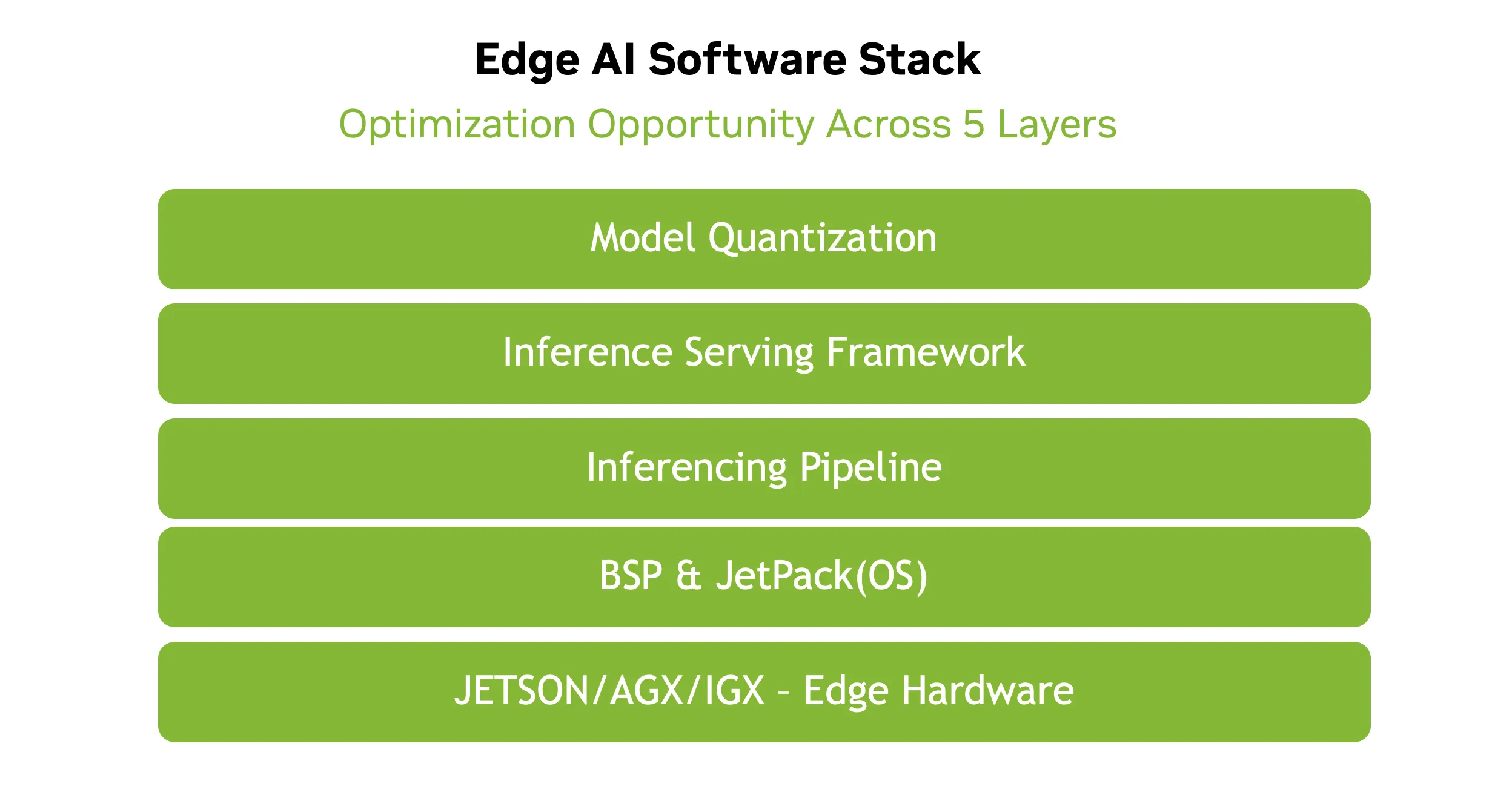
边缘 AI 软件堆栈
我们来深入了解边缘设备的运行时软件堆栈。本指南并非关于全内存优化的详尽指南,而是一个参考框架,可激发灵感并帮助开发者找到改进堆栈的新方法。节省的内存显示了 NVIDIA 团队取得的成就。经验丰富的用户可以提高效率,而其他人则可以从这些示例开始,更好地利用 NVIDIA Jetson 和 NVIDIA IGX 平台 上的资源。
本博客探讨了五个关键层,从 Jetson BSP 和 NVIDIA JetPack 的基础开始,一直到推理工作流、推理框架和量化技术。我们来逐步深入了解每一层。
基础层:板级支持包和软件堆栈
NVIDIA Jetson 板支持包 (BSP) 和 NVIDIA JetPack 层构成了软件堆栈的基础,可与硬件交互。它包括 Linux 内核、设备驱动程序、固件和 JetPack SDK,以及支持计算、多媒体和加速 I/ O 的组件。此层将硬件复杂性 ( GPU、CPU、内存和外设) 抽象化,为更高级别的服务和应用提供稳定、优化的基础。
在这一层,可以通过禁用未使用的服务并回收保留的剔除区域来节省内存。这些优化可减少应用工作负载的开销和可用 DRAM,而不会影响核心功能。以下各节将重点介绍实现这些优化的关键技术。
BSP 和 JetPack 层优化指南适用于 Jetson Orin NX 和 Jetson Orin Nano。
| 旋钮 | 可以回收的内存 | 说明 |
| 禁用图形桌面,包括显示和 UI 相关服务。 | 高达 865 MB | sudo systemctl set-default multi-user.target |
| 禁用网络、连接和不必要的日志服务。 | 高达 32 MB | sudo systemctl disable <service-name> |
NVIDIA Jetson Orin NX 上的开挖区域以及内核和用户空间优化是提高整体系统效率的关键领域。以下各节将探讨优化这些层的实用技术。
雕刻优化
NVIDIA Jetson Orin NX 和 NVIDIA Jetson Orin Nano 中的 Carveout 区域是在启动时预留的物理内存,用于特定硬件引擎、固件和实时子系统。Linux 或 NVIDIA CUDA 应用程序无法访问它们,而是由片上微控制器和加速器使用。它们充当专用内存池,以确保隔离、安全性和确定性行为。根据您的工作流和应用程序需求,可以禁用一些分流,以进一步优化内存使用量。
| Carveout | 何时禁用 | 如何禁用 | 回收的 dram 大小 |
| CARVEOUT_DCE_TSEC | 显示时 不需要 |
请参阅注释 1 然后重新刷写 |
1 MB |
| CARVEOUT_DCE | 32 MB | ||
| CARVEOUT_DISP_EARLY_BOOT_FB | 34 MB | ||
| CARVEOUT_TSEC_DCE | 1 MB | ||
| CARVEOUT_CAMERA_ 任务列表 | 当相机 不需要 |
请参阅注释 2 然后重新刷写 |
32 MB |
| CARVEOUT_RCE | 1 MB |
注 1:以下示例展示了用户在不需要显示时如何进行内存优化。在 Linux_for_Tegra/bootloader/generic/BCT/tegra234-mb1-bct-misc-p3767-0000.dts 的 /misc/carveout/ 节点内添加代码段
// Display-related carveouts aux_info@CARVEOUT_BPMP_DCE { pref_base = <0x0 0x0>; size = <0x0 0x0>; // 0MB alignment = <0x0 0x0>; // 0MB }; aux_info@CARVEOUT_DCE_TSEC { pref_base = <0x0 0x0>; size = <0x0 0x0>; // 0MB alignment = <0x0 0x0>; // 0MB }; aux_info@CARVEOUT_DCE { pref_base = <0x0 0x0>; size = <0x0 0x0>; // 0MB alignment = <0x0 0x0>; // 0MB }; aux_info@CARVEOUT_DISP_EARLY_BOOT_FB { pref_base = <0x0 0x0>; size = <0x0 0x0>; // 0MB alignment = <0x0 0x0>; // 0MB }; aux_info@CARVEOUT_TSEC_DCE { pref_base = <0x0 0x0>; size = <0x0 0x0>; // 0MB alignment = <0x0 0x0>; // 0MB }; |
将 Linux_for_Tegra/bootloader/tegra234-mb2-bct-common.dtsi 中 /mb2-misc/auxp_controls@3/ 节点的内容更新为:
/* Control fields for DCE cluster. */ auxp_controls@3 { enable_init = <0>; enable_fw_load = <0>; enable_unhalt = <0>; reset_vector = <0x40000000>;}; |
删除 Linux_for_Tegra/bootloader/tegra234-mb2-bct-common.dtsi 的整个 /mb2-misc/auxp_ast_config@6 和 /mb2-misc/auxp_ast_config@7 节点
使用 dtc 工具将内核 dtb 反编译为 dts,将 /display@13800000 节点的状态标记为 disabled,然后将 dts 重新编译为内核 dtb:
display@13800000 { status = "disabled"; }; |
注 2: 以下示例展示了用户如何在不需要摄像头时优化内存。在 Linux_for_Tegra/bootloader/generic/BCT/tegra234-mb1-bct-misc-p3767-0000.dts 的 /misc/carveout/ 节点内添加代码段:
aux_info@CARVEOUT_CAMERA_TASKLIST { pref_base = <0x0 0x0>; size = <0x0 0x0>; // 0MB alignment = <0x0 0x0>; // 0MB }; aux_info@CARVEOUT_RCE { pref_base = <0x0 0x0>; size = <0x0 0x0>; // 0MB alignment = <0x0 0x0>; // 0MB }; |
将 Linux_for_Tegra/bootloader/tegra234-mb2-bct-common.dtsi 的/mb2-misc/auxp_controls = 2/node 的内容更新为:
/* Control fields for RCE cluster. */ auxp_controls@2 { enable_init = <0>; enable_fw_load = <0>; enable_unhalt = <0>; }; |
内核端优化
Jetson Orin、Orin NX 和 Orin Nano 平台使用 NVIDIA 特定的输入/ 输出内存管理单元 (IOMMU) 来处理外设的直接内存访问 (DMA) 地址转换,使设备能够访问系统内存,而不管物理地址如何。
Linux 软件 I/ O 翻译旁路缓冲区 (SWIOTLB) 是一种变通方案,适用于没有硬件 IOMMU 或外围设备限制为 32 位 DMA 的系统。由于 Orin 包含一个强大的硬件 IOMMU,可重新映射 DMA 地址,因此 SWIOTLB 通常是冗余的。
SWIOTLB 调优
对于需要 SWIOTLB 的特定用例或非标准外设,或者当内核日志表明存在 DMA 问题时,可以使用启动参数调整保留大小。
swiotlb= 参数定义 I/ O TLB 板的数量 (每个 2 KB) :
总大小 (字节) swiotlb_value = 2048
示例 ( 4 MB 缓冲区) :
- 4 MB 2 KB 2048 块板
- 内核命令:
swiotlb=2048
用户空间侧优化
在 Jetson 上,应用程序总内存包括:
- 进程和系统服务使用的 CPU 内存。
- CUDA、多媒体缓冲区和加速器使用的硬件 (NvMap) 显存。
两者共享相同的物理内存池,优化二者会相互受益。
减少 CPU 显存占用
首先,识别 CPU 内存消耗最多的进程。GUI 或音频组件等后台服务可能会占用大量内存,在生产环境中可能没有必要。
- 测量 CPU 显存占用率
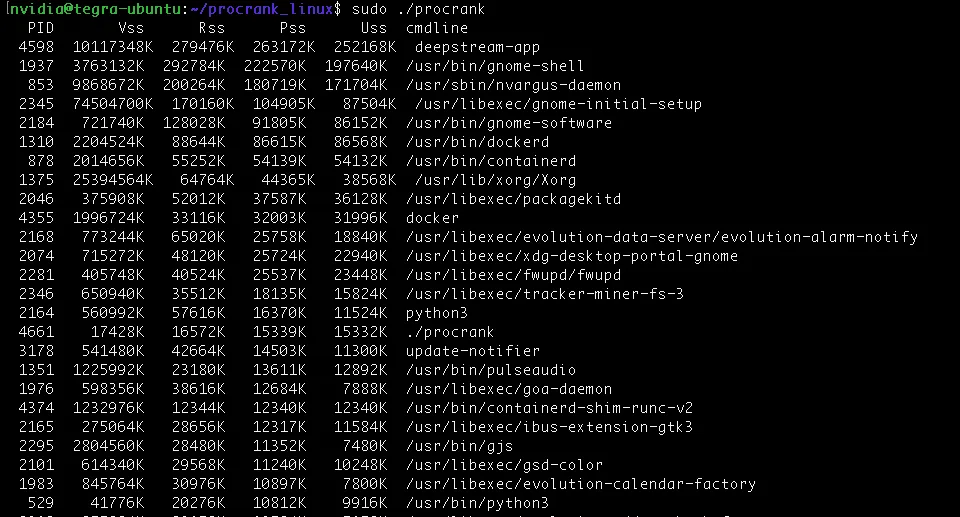
使用procrank分析显存占用率:
$ git clone https://github.com/csimmonds/procrank_linux.git$ cd procrank_linux/$ make$ sudo ./procrank |
输出按 PSS (比例集大小) 排序,反映实际物理内存使用量。
- 根据发现进行优化并 确定流程
gnome-shell或Xorg(GUI)pulseaudio- 未使用的 python3 进程
这些在生产环境中通常是不必要的,并且可以禁用以回收内存。在无外设部署中,禁用 GUI 服务可以释放大量系统内存。
- 分析和衡量硬件内存使用率
除了 CPU 内存之外,GPU 和多媒体分配也会影响可用内存。
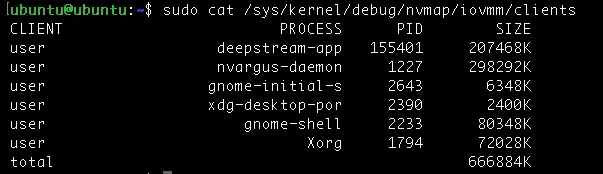
$ sudo cat /sys/kernel/debug/nvmap/iovmm/clients |
* 这显示了使用 NvMap (例如 CUDA、视频工作流) 的进程的内存使用情况。
- 优化硬件内存
识别使用大型 GPU 或缓冲区分配的进程。与 CPU 优化一样,GUI 工作流 (gnome-shell,Xorg) 等服务可能会消耗不必要的硬件内存。减少这些分配可释放更多内存用于 AI 工作负载。
推理工作流
此层通过预处理、推理和后处理来管理端到端数据流,以生成可操作的输出。框架如 NVIDIA DeepStream 为视频和传感器输入等流式传输数据提供 GPU 加速的高性能工作流。它们在简化的工作流程中处理解码、批处理、推理、跟踪和分析,从而实现可扩展的处理。此层可抽象化复杂性,优化数据传输和计算利用率,从而打造高效的生产就绪型 AI 应用。
了解如何通过配置和实现选项优化推理工作流,以减少内存占用并提高性能。虽然通过 DeepStream 展示了这些原则,但这些原则广泛适用于各种框架和应用。
| 旋钮 | 可以回收的内存 |
| 容器与裸金属 | 高达 70 MB |
| 从 Python 切换到 C++ | 高达 84 MB |
| 调整工作流配置: 禁用 Tiler/ OSDUse FakeSink | 高达 258 MB |
| 总计 | 412 MB |
** 在 DeepStream 式推理工作流中,禁用 Tiler/ OSD 并使用 FakeSink 可以消除可视化所需的显示阶段,但在无外设部署或生产部署中却不必要。这样可以节省内存、减少 GPU 负载并提高吞吐量。
推理框架
适用于 LLM 的推理服务框架层专注于在生产环境中高效部署和扩展大语言模型,其中 vLLM、SGLang 和 Llama.cpp 等框架在该领域处于领先地位。这些框架通过持续批处理、KV 缓存管理和高效内存利用率等技术优化推理,以更大限度地提高吞吐量并降低延迟。
- vLLM 凭借其分页注意力机制在高吞吐量服务方面表现出色。
- SGLang 支持灵活且可编程的推理工作流程。
- Llama.cpp 和 NVIDIA TensorRT Edge-LLM 经过优化,可在资源受限的环境中高效执行。
这些框架提供了在边缘本地部署时可靠地提供 LLM 所需的基础架构。
模型量化
模型量化是一项关键技术,可使用较低精度的数据类型表示权重和激活函数,从而减少内存占用并加速 AI 模型的推理。
量化应根据目标用例的明确准确性和性能要求进行驱动。在选择量化方案之前,请定义:
- 可接受的最低模型质量或任务准确性。
- 目标吞吐量和延迟。
- 部署限制,尤其是可用的 GPU 显存。
锁定这些要求后,推荐的方法是逐步评估较低精度的量化选项。从最高准确度的基准开始,然后向下移动至支持的量化格式,直到模型不再满足所需的质量值。选定的量化点应是仍能满足用例准确性要求的最低精度,因为这通常可提供最佳的内存节省量和效率。
如果低位量化带来了不可接受的性能下降,请使用量化感知蒸馏 (QAD) 等恢复技术来恢复丢失的准确性。这些方法通常可以恢复足够的模型质量,在满足部署要求的同时实现更积极的量化。
选择量化级别后,优化目标部署的运行时内存。对 vLLM 配置参数 (尤其是 GPU 显存利用率) 进行扫描,找到维持目标性能所需的最小显存占用。这可确保针对吞吐量和延迟目标进行规模合适的高效部署。
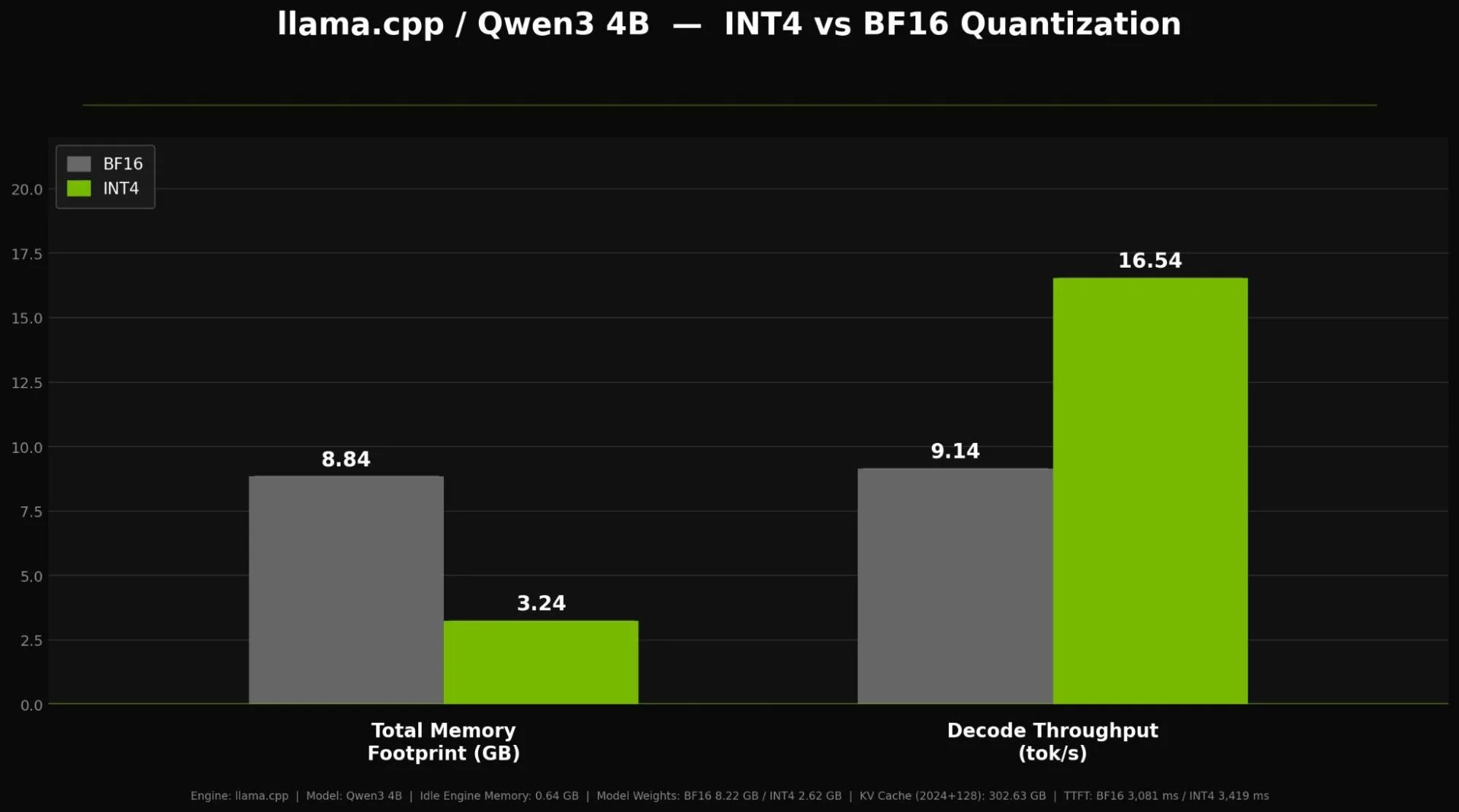
FP16 和 FP8 等格式平衡了准确性和性能,FP8 越来越多地用于提高吞吐量。W4A16 等更激进的方案可减少内存和带宽需求,同时保持可接受的准确性。 NVIDIA NVFP4 通过硬件友好型 4 位计算进一步提高了效率。这些方法共同为大型模型和资源受限的系统实现了更快、更经济高效的推理。支持因 Jetson 平台而异,详情请参阅 NVIDIA Jetson 产品目录。
| 旋钮 | 可以回收的内存 | 注意事项 |
| Qwen3 8B 上从 FP16 到 W4A16 的模型量化 | ~ 10 GB | Qwen3 8B |
| Qwen3 4B 上从 BF16 到 INT4 的模型量化 | 约 5.6 GB | Qwen3 4B |
根据所包含和优化的五层软件堆栈组件,可在保持高精度和功能同等的同时节省高达 10 – 12 GB 的内存。
使用专用加速器解析边缘推理
Jetson 平台包含多个非 GPU 加速器,可通过卸载 CPU 和 GPU 中的专用工作负载来提高效率。其中包括用于摄像头处理的图像信号处理器 (ISP) 、用于视频编码/ 解码的 NVENC/ NVDEC,以及用于视觉任务的 NVIDIA 可编程视觉加速器 (PVA) 。
从 Jetson Orin NX 到 Jetson Thor 的 PVA,非常适合始终开启、低功耗的视觉工作负载,例如监控模式、移动检测、目标跟踪和特征提取,在这些工作负载中,持续使用 GPU 会降低效率。通过卸载这些任务,PVA 可降低延迟并释放 GPU 资源,以处理更复杂的推理或并行工作负载,从而提高边缘部署的整体性能和能效。
NVIDIA cuPVA SDK 目前处于抢先体验阶段。如果您有兴趣探索其功能,请联系我们以获取更多信息。
多层间的可能节省:
| 图层 | 潜在节省 |
| BSP 和操作系统服务 | ~ 1025 MB |
| 工作流优化 | ~ 412 MB |
| 推理框架和模型量化 | 约 5 至 10 GB |
如果说有一个关键要点,那就是使用正确的量化精度。
NVFP4、INT4 和 W4A16 等格式可显著减少内存和存储需求,同时为许多 LLM 工作负载保持较高的准确性。
实际用例:Reachy Mini Jetson Mini Assistant
为了展示这些内存优化的影响,请考虑使用 Reachy Mini Jetson Assistant,这是一款在 Jetson Orin Nano 上运行的本地对话式 AI 机器人,具有 8 GB 统一内存,不依赖云。
该助手同时运行多模态 AI 工作流,包括:量化为 4 位 (Q4_K_M GGUF) 并通过 Llama.cpp 提供的视觉语言模型 (Cosmos-Reason2-2B) ,用于实现视觉理解;用于语音识别的 faster-whisper (small.en) ;用于文本转语音的 Kokoro TTS,以及 Reachy Mini SDK 机器人和实时 Web 控制面板。
借助堆栈范围的优化 (禁用显示管理器,无外设运行,通过 Llama.cpp 而不是更重的 Python 框架提供 VLM,使用 4 位量化 Cosmos Reason2 2B,并选择优化的运行时 (适用于 STT 的 CTranslate2、适用于 TTS 和 VAD 的 ONNX Runtime) ,完整的工作流可在单个 Orin Nano 8 GB 系统上运行。
更广泛地说,将 4 位量化与高效的推理运行时 (如 Llama.cpp 和 TensorRT-Edge-LLM ) 相结合,可在此内存预算内访问各种模型,其中 LLM 参数高达 100 亿个,VLM 参数高达 40 亿个。如需测试模型的完整列表,请访问 Jetson AI 实验室模型页面 和 NVIDIA 开发者论坛 。
开始使用
- 详细了解新一代 Orin NX Edge AI 平台。
- 安装 JetPack 和 DeepStream。
- 在 NVIDIA Jetson 论坛上分享您的故事以及这篇博文如何为您提供帮助。