
大语言模型(LLM)的上下文窗口正在迅速扩展,近期的模型已支持128K、256K甚至更长的词元序列。然而,使用扩展的上下文长度来训练这些模型会带来巨大的计算和通信挑战。随着上下文长度的增加,注意力机制的内存占用和通信开销呈二次方增长,导致传统并行策略难以有效应对这些瓶颈。
本文展示了将 NVSHMEM 通信库集成到加速线性代数(XLA)编译器中,可有效优化上下文并行。该集成使得在 JAX 框架中,能够高效训练序列长度高达 256K 词元的 Llama 3 8B 模型。实验结果表明,在长上下文训练任务中,NVSHMEM 相较于 NVIDIA NCCL 性能提升达 36%,尤其在跨多个节点结合张量并行时表现更为显著。
长上下文训练挑战
要了解 NVSHMEM 为何能显著加快长上下文训练速度,有必要首先了解上下文并行的工作原理及其创建的独特通信模式。本节将解释为什么环形注意力的细粒度、延迟敏感型通信使其成为理想的优化候选项。
上下文并行和环注意力
上下文并行(CP)是一种专为处理 Transformer 模型中长序列而设计的并行策略。与按批次划分的数据并行或按模型划分的张量并行不同,上下文并行将序列维度拆分到多个设备上。
环形注意力是一种使用基于环的通信模式的上下文并行的内存高效实现。在注意力计算期间,每个设备:
- 处理序列的局部部分
- 在环形拓扑中与相邻设备交换键值 (KV) 张量
- 当 KV 块在圆环周围循环时,以增量方式计算注意力得分
这种方法可减少峰值显存使用量,同时保持与标准注意力的数学等价性,从而能够使用超出 GPU 显存容量的序列进行训练。
环形注意力中的通信模式
环形注意力涉及频繁的精细通信操作:
- 点对点传输: 将 KV 张量发送到圆环中的下一个设备
- 重叠的计算通信:在获取下一个 KV 块时计算当前 KV 块的注意力
- 低延迟要求:KV 传输处于关键路径上,必须先完成,然后才能继续注意力
这些特征使环注意力成为 NVSHMEM 等低延迟通信库的理想候选对象。
使用 NVSHMEM 进行 GPU 优化的通信
NVSHMEM 是一个在 NVIDIA GPU 上实现 OpenSHMEM 并行编程模型的通信库。它具备多项区别于传统通信库的关键特性,包括对称内存(SM)、流感知通信、复制引擎卸载等,具体如下。
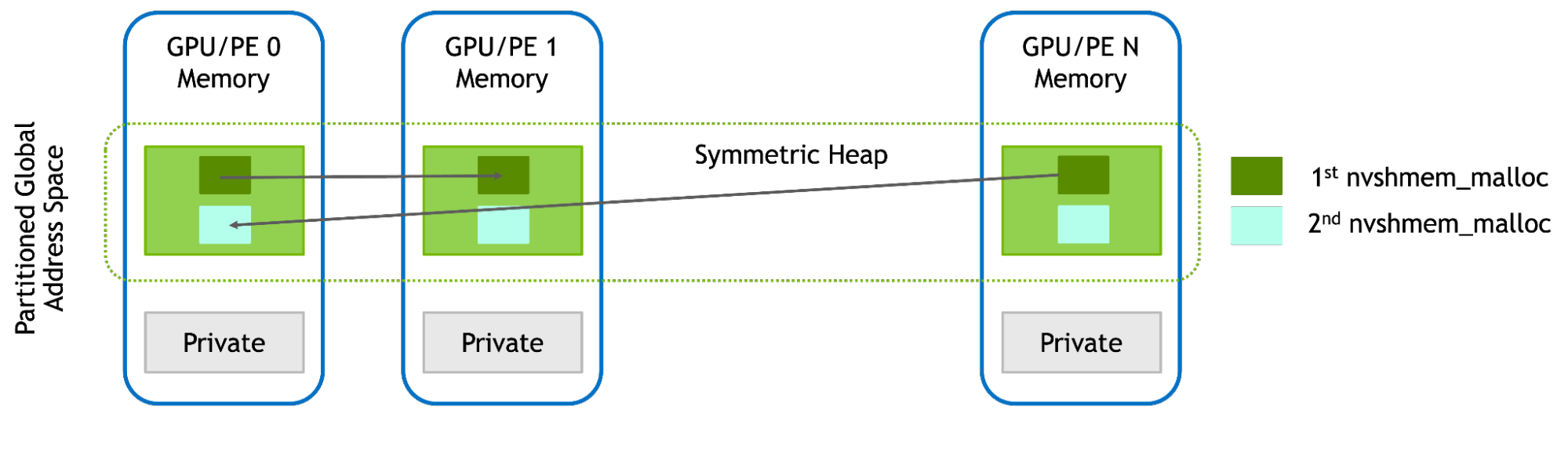
对称内存
NVSHMEM 提供驻留在 GPU 显存中的分区全局地址空间 (PGAS) 。应用使用 nvshmem_malloc 分配此对称堆的缓冲区,这些指针可直接用于通信操作。例如:
int32_t *src_d = (int32_t *)nvshmem_malloc(1024 * sizeof(int));int32_t *dest_d = (int32_t *)nvshmem_malloc(1024 * sizeof(int));ret = nvshmemx_sum_reduce_on_stream(NVSHMEM_TEAM_WORLD, dest_d, src_d, 1024, 0); |
流感知通信
NVSHMEM 提供点对点 (P2P) 流 API (例如 put_nbi_on_stream 和 signal_on_stream) ,可在连接 P2P 的 GPU 上高效移动数据并提供低延迟同步。
与传统由主机发起的通信相比,这些 API 的主要优势之一在于能够利用 GPU 硬件的复制引擎(CE)和 流式内存操作 功能,以零占用 SM 的方式执行这些操作。部分底层 CUDA 接口包括:
- GPU 到 GPU 的直接传输: 与
cudaMemcpyAsync类似,但通过优化的数据路径降低延迟 - 细粒度同步: 使用
cuStreamWriteValue32和cuStreamWaitValue32基元在不涉及 CPU 的情况下在设备之间实现高效信令
除了 P2P 流 API 之外,NVSHMEM 还提供常用于 AllReduce 等 AI 工作负载的常用集合操作(例如 reduce_on_stream)。这些集合操作利用 NVIDIA NVLINK Switch 的 SHARP、网络归约和组播加速功能,实现了延迟优化的单步和吞吐量优化的双步 AllReduce 算法。底层 CUDA 接口包含 多内存 ISA,可将归约和广播等基本操作卸载到交换机,从而进一步减少 SM 占用,带来额外优势。
当在同一 CUDA 流上发生时间重叠时,大多数或所有 GPU SM 均可用于计算操作,因此这两种功能都可以展示有用的计算通信操作管线。
CUDA 计算图互操作性
NVSHMEM 运算可捕获到 CUDA 计算图中,从而实现:
- 多次迭代期间摊销的内核启动用度
- 通过 CUDA 运行时优化执行调度
- 与其他截取图形的运算无缝合成
这种可组合性对于依赖 CUDA 计算图进行性能优化的生产训练框架至关重要。
集成 NVSHMEM 和 XLA
本节介绍如何将 NVSHMEM 集成到 XLA 编译器基础设施中,涵盖运行时标志、自动后端选择启发式算法和编译流程。
通过调试选项进行运行时控制
XLA 提供用于动态控制的运行时标志:
XLA_FLAGS="--xla_gpu_experimental_enable_nvshmem=true" |
此标志在 xla/debug_options_flags.cc 中定义,允许用户在不重新编译的情况下启用或禁用 NVSHMEM (默认值 = false) 。“experimental” (实验性) 前缀表示 API 可能会随着特征的成熟而发展。
自动后端选择
编译流程中的 CollectiveBackendAssigner 通道根据工作负载特性确定要使用的通信后端。这就是这个系统的智能所在。
选择启发式算法
编译器会分析每个集合运算,并根据以下三个关键标准来决定是否使用 NVSHMEM:
- 单个设备: 当每个进程只有一个设备可见 (无网络开销) 时,使用 NVSHMEM
- 单分区: 当集合操作中所有参与的设备都由同一进程管理时,使用 NVSHMEM
- NVLink 域: 使用 NVSHMEM 通过 NVIDIA NVLink 结构进行节点内通信
此外,消息大小启发式算法适用:
- AllReduce 操作: 仅当消息大小等于指定值(通常为 16 MB)时使用 NVSHMEM;对于更大的消息,则回退到针对带宽优化的 NCCL。
- CollectivePermute 操作: 无论消息大小 (未应用值) ,始终使用 NVSHMEM。
- 理论依据: AllReduce 可受益于适用于大消息的 NCCL 环或树形算法,而 CollectivePermute 的点对点特性使 NVSHMEM 成为适用于各种规模、低延迟场景的理想选择。
JAX 框架集成
此架构的优势在于它完全透明 Python 框架。JAX 开发者编写标准集合运算:
import jaximport jax.numpy as jnp@jax.jitdef collective_permute_example(x): # Shift data from each device to the next device in a ring axis_name = 'devices' perm = [(i, (i + 1) % jax.device_count()) for i in range(jax.device_count())] return jax.lax.ppermute(x, axis_name, perm=perm)# The compiler automatically selects NVSHMEM when appropriateresult = collective_permute_example(data) |
XLA 编译器会分析此 ppermute (集合 permute) 运算,并自动执行以下步骤:
- 应用启发式算法:单设备、单分区或 NVLink 域中
- 识别 CollectivePermute 操作 (不适用消息大小值)
- 选择 NVSHMEM 以实现最佳点对点通信
- 生成在运行时调用 NVSHMEM 主机 API 的数据块
- NVSHMEM 主机 API 将 CUDA 流上的操作列在队列中。例如:
nvshmemx_float_sum_reduce_on_stream、nvshmemx_float_put_nbi_on_stream
这种端到端集成意味着高级 JAX 代码自动受益于 NVSHMEM 性能,而无需进行任何用户级更改或标注。
实验性方法
为了评估 NVSHMEM 的性能优势,该团队在 Llama 3 8B 上进行了一系列序列长度 ( 64K 到 256K 词元) 和并行配置的实验。本节将详细介绍模型设置、硬件配置,以及用于将 NVSHMEM 与 NCCL 基准进行比较的指标。
模型配置
该团队使用以下配置在 Llama 3 8B 模型上评估了 NVSHMEM 加速的上下文并行性。
- 型号: Llama 3 8B
- 精度:BF16
- 上下文并行策略: 环形注意力
- 框架: MaxText (基于 JAX 的训练框架)
- 硬件: NVIDIA GB200 NVL72
- Docker 镜像: 可通过 NVIDIA/JAX-Toolbox
- JAX 版本: JAX 0.6.2 及更高版本
并行配置
针对不同的序列长度测试了并行策略的各种组合 (表 1) 。
| 序列长度 | 节点 | GPU | 上下文并行 | 张量并行 | 完全分片数据并行 | CP 拆分后每个 GPU 的序列长度 |
| 64K | 1-4 个 | 4 至 16 天 | 4 至 16 天 | 1 | 1-2 个 | 4K-16K |
| 128K | 2-8 名 | 8-32 | 8-32 | 1 | 1-2 个 | 4K-16K |
| 25.6 万 | 8 至 16 天 | 32-64 周岁 | 16 至 32 岁 | 2 | 1-2 个 | 8K-16K |
长序列 (256K) 除了采用上下文并行之外,还采用了张量并行 (TP = 2) ,以在 GPU 显存限制条件下拟合模型。
通信后端比较
每个配置都使用两个通信后端进行评估:
- NCCL (基准)
- 支持 NVSHMEM 的实现
测量:
- 每台设备的 TFLOP/s: GPU 计算吞吐量
- 步长 (秒):每次训练迭代的时间
- 加速: NVSHMEM 相对于 NCCL 的性能提升
所有指标均在 3-20 次迭代中取平均值 (跳过前两次热身迭代) ,并根据秩 0 日志计算得出平均值,以确保一致性。
性能结果
如表 2 所示,NVSHMEM 性能优势随着序列长度的增加而显著提升:
- 64K 序列: 加速 0.3-3.9% (略有改善)
- 128K 个序列:加速 0.7-2.4% (持续改进)
- 25.6 万个序列: 加速 30.4-36.3% (显著改善)
这种缩放行为与环注意力通信模式一致:更长的序列需要围绕环进行更多 KV 张量交换,从而增强了 NVSHMEM 低延迟通信的优势。
跨节点扩展时,节点间通信延迟变得更加关键。NVSHMEM 无阻塞主机 API 和经过优化的数据路径可在 8-16 个节点部署中提供一致的优势。
| 序列长度 | 节点 | CP | TP | GPU | 序列/ GPU | 默认 TFLOP/s | NVSHMEM TFLOP/ s | 加速 |
| 64K | 1 | 4 | 1 | 4 | 16K | 605.64 | 607.36 | 小于 0.3 |
| 64K | 2 | 8 | 1 | 8 | 8K | 549.92 | 557.17 | 增加 1.3% |
| 64K | 4 | 16 | 1 | 16 | 4K | 482.19 | 501.06 | 增加 3.9% |
| 128K | 2 | 8 | 1 | 8 | 16K | 512.22 | 515.87 | + 0.7% |
| 128K | 4 | 16 | 1 | 16 | 8K | 473.58 | 472.46 | -0.2% |
| 128K | 8 | 32 | 1 | 32 | 4K | ¥ 460.99 | 431.13 | 增加 2.4% |
| 25.6 万 | 8 | 16 | 2 | 32 | 16K | 366.94 | 500.22 | 增加 36.3% |
| 25.6 万 | 16 | 32 | 2 | 64 | 8K | 346.33 | 451.70 | 增加 30.4% |
实际影响
基于这些结果,NVSHMEM 在以下方面具有明显优势:
- 长上下文训练: 序列 = 128K 词元,其中通信成为瓶颈
- 多节点部署: 超越单节点 NVLink 域
- 环形注意力和类似模式: 具有细粒度延迟敏感型通信的工作负载
- 混合并行: 结合 CP、TP 和 FSDP 的配置
XLA 集成使 JAX 能够访问 NVSHMEM。无需更改用户代码,只需使用支持 NVSHMEM 的 XLA 构建并设置适当的环境标志即可。
开始长上下文模型训练
使用长上下文窗口训练 LLM 需要能够处理细粒度、延迟敏感型数据交换的高效通信策略。将 NVSHMEM 集成到 XLA 后,可通过环形注意力实现上下文并行的透明加速,在 Llama 3 8B 上为 256K 词元序列提供高达 36% 的速度提升。
要点:
- NVSHMEM 无阻塞主机 API 和低延迟数据路径非常适合环形注意力通信模式
- XLA 编译器集成使高级框架能够访问 NVSHMEM,而无需更改代码
- 性能优势随序列长度扩展,序列显著改进 = 256K 词元
- 多节点部署的收益最大,这使得 NVSHMEM 对于生产长上下文训练至关重要
随着上下文窗口的持续增长,优化低延迟通信的解决方案 (如 NVSHMEM) 对于使长上下文训练切实可行且经济高效至关重要。我们鼓励社区在 JAX 框架中试用支持 NVSHMEM 的 XLA 构建,并分享他们在长上下文工作负载方面的经验。
首先,请查看 GitHub 上的 MaxText 框架, NVIDIA/JAX-Toolbox 和 openxla/xla。
致谢
我们要向 NVSHMEM 贡献者 Seth Howell 和 Akhil Langer 表示感谢。