
训练语音 AI 模型以正确识别或合成临床术语异常困难。药物名称如 Acetaminophen、Amlodipine、Cefazolin 和 Biktarvy 不在日常词汇表中。手术名称、解剖学术语和特定专业的诊断以不同的形式引入了同样的问题。现成的语音系统听起来很流畅,但仍然会漏掉对临床工作流程最重要的词语。
合成数据生成 (SDG) 有助于缩小这一差距,但前提是合成语音在语音上准确无误。如果文本转语音 (TTS) 系统对药物或手术名称发音有误,则会生成训练或评估数据,以教授错误的发音。它不会修复原始问题,而是会增加故障检测的难度。在正确实施后,SDG 使团队能够在几个小时内完成领域基准测试,而无需收集真实的临床音频,也无需等待注释流程或 IRB 批准。
本文介绍了临床自动语音识别 (ASR)工作流,用于生成发音感知的合成音频、审查临床术语和评估识别质量。 NVIDIA 智能体技能为工作流提供指导,而 NVIDIA NeMo Data Designer和 NVIDIA Nemotron Speech則提供数据生成和语音服务。
为什么临床 ASR 需要可重复的反馈回路?
临床语音 AI 正在成为听写、环境文档、呼叫中心工作流、患者接收和就诊后随访的一部分。这些系统有望理解通用语音中罕见但对任务至关重要的术语:药物名称、手术名称、解剖学、诊断、设备、症状和专业缩写。
现实世界的临床音频也难以收集和共享。它可能价格昂贵、注释缓慢、受隐私要求限制,并且在专业和罕见术语之间的分布不均。根据 HIPAA,真实的患者记录是受保护的健康信息,这意味着它们无法在团队之间自由共享、检查版本控制或在自动化测试流程中使用,否则会产生重大的合规性开销。根据设计,合成音频不包含 PHI,因此它是团队可以版本化、共享和测试的唯一临床语音数据形式。公共数据集可能不包括部署所依赖的确切术语。
实际挑战不仅在于生成更多数据。开发者需要一种可重复的方式来定义目标临床概况、创建基准、审查发音风险、衡量 ASR 行为、改进模型,并决定下一个周期是否应扩展术语、改进发音、添加噪声或微调。
AI 智能体技能对临床语音 AI 有何帮助?
智能体技能引导开发者完成临床 ASR 评估的重复步骤:定义配置文件、构建以术语为中心的基准测试、查看发音、生成合成音频、测量 ASR 行为以及选择下一次迭代。
在本文中,飞轮是完整的改进循环:构建基准测试,评估 ASR 行为,使用结果决定要更改的内容,并在更改后重新评估。工作流是该循环的一个环节,例如生成句子、添加发音标记、合成音频和编写清单。
工作流始于对话,而非静态配置文件。您可以在任何智能体工具 (例如,Cloude Code 或 Codex) 中运行构建技能,并描述他们想要进行压力测试的临床工作流程。然后,数字健康临床 ASR 构建智能体技能会询问专业领域、目标设置、已知故障条款和所需上下文,然后生成初始测试基准配置。
该技能一次问一个问题,依次是:
- 什么专业或工作流程
- 观察到了哪些 ASR 故障模式
- 每天会遇到哪些症状,哪些症状比较困难
常用术语成为基准,而困难术语成为推动基准设计的信号。
Developer:/flywheel-buildAgent:What clinical specialty or workflow is this for?Examples: orthopedic practice, oncology dictation, ICU handoff, ambulatory cardiology.Developer:Orthopedic practice. Focus on post-op instructions and PACU handoff.The ASR system often misses medication names and procedure names.Agent:I'll start a benchmark profile with drug, procedure, anatomy, and condition terms, then run pronunciation QA before generating the full audio set. |
这种以剖面为导向的启动方式可在骨科手术、心脏病学、肿瘤学、行为健康或词汇表不同的任何其他领域配置相同的飞轮。智能体的工作是使工作流程保持正确轨道:收集临床资料、提出或提取术语、先生成一个小的 QA 集、将 IPA 漏报的问题提交审查,然后构建完整的基准。
| 类别 | 术语示例 |
| 药物 | Cefazolin、Ketorolac、Ropivacaine、Enoxaparin、Tranexamic 酸 |
| 程序 | 全关节置换术、半关节置换术、ORIF、关节镜检查 |
| 解剖学 | Acetabulum、骨高原、股颈、骨 |
| 条件 | 血关节病、骨髓炎、隔室综合征、股撞击 |
如何根据临床种子术语生成支持 TTS 的合成音频
从配置文件特定术语列表开始,工作流使用 NeMo Data Designer 将种子术语扩展为更丰富的数据集。NeMo Data Designer 从头开始或根据种子数据生成高质量的合成数据。开发者定义输出列及其之间的依赖关系。
NeMo Data Designer 可在处理批处理、并行执行、验证以及预览或完整运行执行时解决依赖项。在此飞轮中,输出列会生成完整的合成语音记录:唯一的样本 ID、包含目标术语的临床句子、发音源、带有音素标记的语音合成标记语言 (SSML) 句子 (如果可用) ,以及合成音频的目标路径。
在此工作流中,五列可将临床术语转换为带音素标注的 TTS 就绪型句子 (图 1) 。
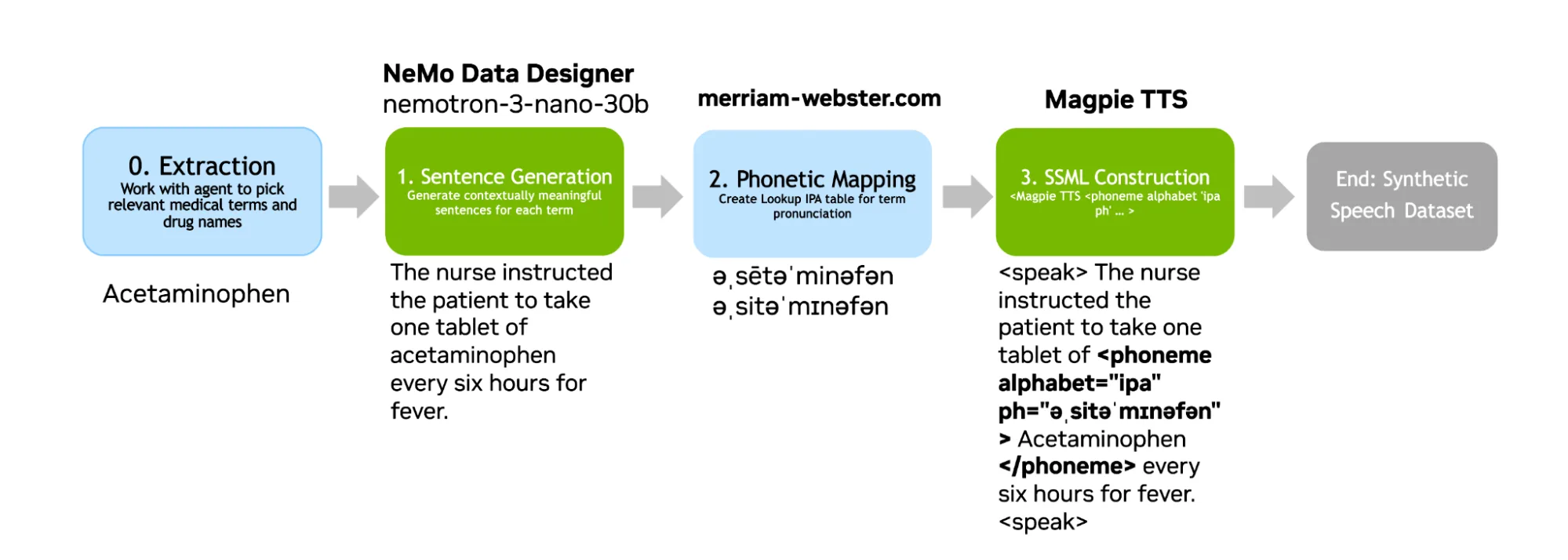
| 列 | 目的 | 技能运用 |
| sample_id | 生成样本的唯一 ID | 保持音频文件、文稿和指标行对齐 |
| sentence | 包含确切目标术语的临床句子 | 成为 ASR 参考转录 |
| ipa_pronunciation | 经过审查或根据字典衍生的候选发音 | 推动音素注入,并标记审核差距 |
| ssml_sentence | 使用 SSML 封装且带有音素标记 (如果可用) 的句子 | 成为 TTS 输入 |
| audio_filepath | 合成音频文件的目标路径 | 成为 manifest 音频路径 |
生成的句子提示应保留确切的目标词。如果模型替代品牌名称、通用同义词、缩写或拼写变体,基准测试将不再测试预期实体。代理技能可以检查该条件,并重新生成或拒绝不包含确切术语的行。
| 药物 | 句子 | ipa_ 发音 | ssml_sentence | audio_filepath |
| Acetaminophen | The nurse administered Acetaminophen to the patient after surgery to manage mild pain. | əˌsiːtəˈmɪnəfɛn | <speak>The nurse administered <phoneme alphabet=”ipa” ph=”əˌsiːtəˈmɪnəfɛn”>Acetaminophen</phoneme> to the patient after surgery to manage mild pain.</speak> | data/audio/audio_Acetaminophen_3c7a1f02.wav |
SSML 音素标签注入
SSML 是一种基于 XML 的标记语言,可为 TTS 引擎提供有关如何合成语音的说明。它对于控制发音、节奏、音量和重点等方面至关重要。SSML 步骤将生成的句子包装在 <speak> 元素中,并在目标词条的每次出现周围注入 <phoneme alphabet="ipa"> 标记。该实现使用不区分大小写的正则表达式,以便保留句子中的原始大小写,同时保持稳健的匹配。
<speak>A forty-five year old patient was prescribed<phoneme alphabet="ipa" ph="əˌsiːtəˈmɪnəfɛn">Acetaminophen </phoneme>once daily to manage mild pain.</speak> |
人工审核 IPA 发音差距
字典查找涵盖许多临床术语,但并非全部。较新的药物名称、商号、罕见的程序术语和特定专业的短语可能丢失,或者可能返回需要检查的发音。飞轮通过明确的手动审查路径来处理这些空隙。
当可信字典的发音不可用时,由 LLM 支持的智能体工具可以提出候选 IPA 字符串。重要的界限是,LLM 的提案不会被视为正确的事实。该候选项必须通过验证和人工审核。
手动发音循环如下:
- 标记 IPA 缺失或置信度低的行
- 使用智能体工具提供一个或多个 IPA 候选项
- 根据 TTS 音素清单验证候选项
- 在上下文中合成该术语的简短问答片段
- 审核以接受、编辑或拒绝应聘者
- 将已接受的发音写入已审核的优设文件
- 重新生成受影响的 SSML 和音频
此过程会将发音差距转化为一个小的审查队列,而不是隐藏的基准质量问题。例如,在骨科实践参考会议中,需要对 Femoroacetabular Impingement、Hemiarthroplasty、Ketorolac、Pertrochanteric 和 Ropivacaine 等术语进行回顾或覆盖。经过审核后,完整的基准测试生成了 67 个音频样本,其中没有任何行,依赖于未经审核的原生 TTS 发音。
只有当智能体真正停止并在正确的时间等待人类时,循环才会起作用。技能本身会强制暂停。技能中的指令是为智能体而不是开发者编写的,它们以通俗易懂的语言告诉智能体,在用户听完视频片段之前,智能体无法继续学习。
如何合成音频并生成清单
在每行具有 SSML 句子和目标音频路径后,工作流将为每个生成的样本合成一个音频文件。 NVIDIA Magpie TTS Multilingual 非常适合这个阶段,因为它支持带有 IPA 和 ARPAbet 的 SSML 音素标签。这使得合成器能够使用已审查的音素序列渲染临床术语,而不是仅依赖其自己的音素到音素预测。
最终输出是兼容 NeMo 的 JSONL 清单文件。每行都将音频文件与其转录内容和元数据关联起来:
{ "audio_filepath": "data/audio/audio_Acetaminophen_3c7a1f02.wav", "text": "The nurse administered Acetaminophen to the patient after surgery to manage mild pain.", "duration": 3.914, "term": "Acetaminophen", "entity_category": "drug", "ipa_source": "reviewed"} |
该清单是 SDG、ASR 评估和模型适应之间的传递点。它也是基准测试中保留按实体类别、发音来源、上下文类型、语音或声音条件对结果进行切片所需的元数据的地方。
具备 ASR 技术的临床级优质飞轮有什么价值?
虽然生成语音控制的音频本身很有用,但更大的价值在于 AI 智能体 通过改进循环与开发者合作。用户首先需要了解临床状况。构建技能会创建一个基准测试。评估技能会报告 ASR 系统难以处理的问题。适应技能有助于决定是否微调、扩展术语列表、提高发音覆盖率或添加更困难的声音条件。然后,重新评估步骤会检查更改是否有用。
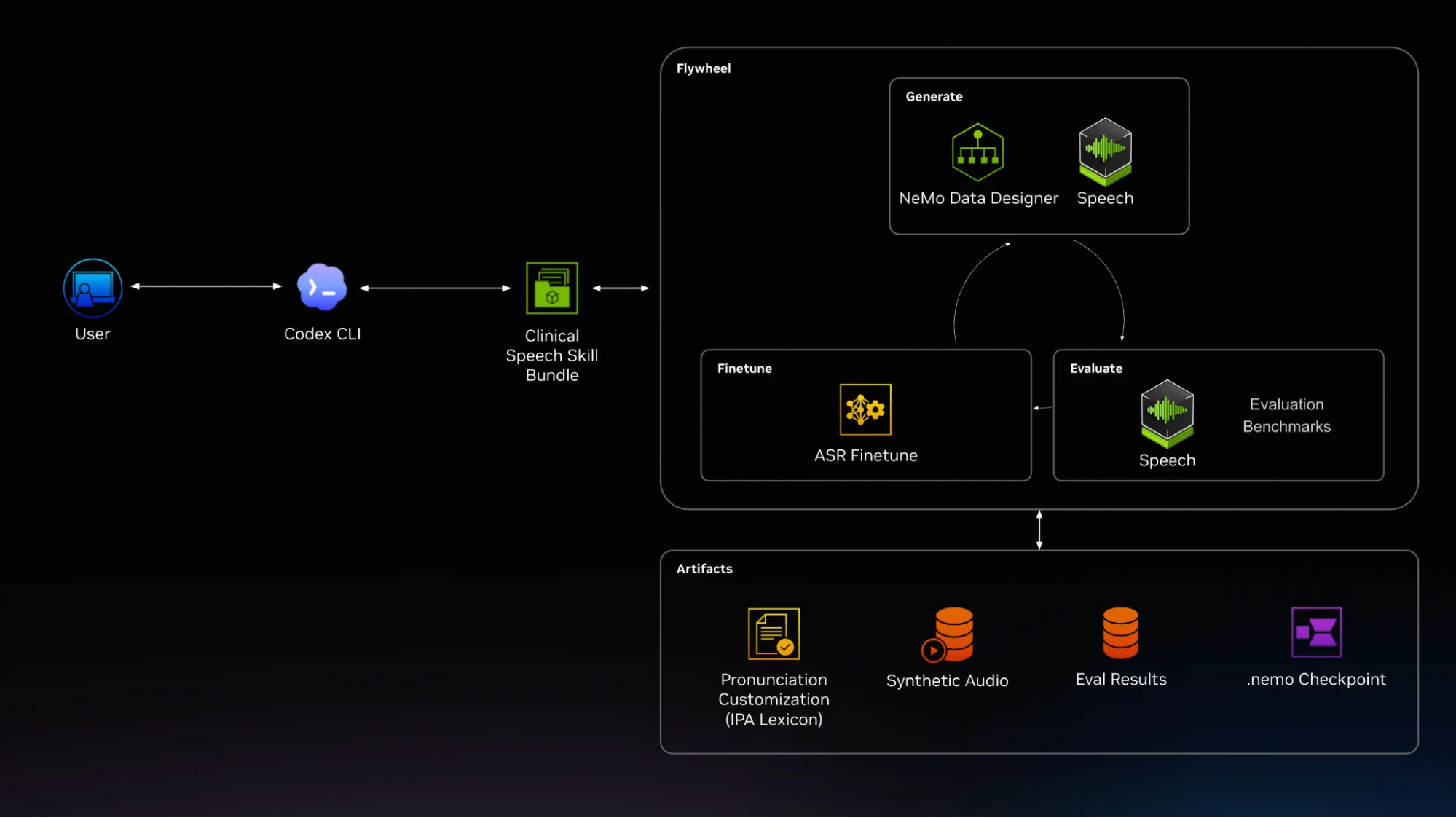
评估技能包括一条值得研究的反直觉路线规则。如果 Merriam-Webster 改进了音频评分,但 Magpie 后备音频评分较差,则该技能会引导用户返回构建,而不是微调。这种模式是发音覆盖差距,而不是模型差距。通过对 TTS 发音差距进行微调,模型可以错误地识别模型自身的错误。ASR 转录本身由 NVIDIA Nemotron Speech 提供服务。
| 阶段 | 开发者意图 | 技能行为 |
| 设置 | 准备环境并检查访问权限 | 验证依赖项、凭据和烟雾测试 |
| 构建 | 创建配置文件特定的基准测试 | 收集专业上下文、提出术语、运行发音问答并生成清单 |
| 评估 | 在基准测试中测量 ASR 行为 | 运行转录并报告聚合和实体级指标 |
| 适应 | 根据故障模式提高 ASR 质量 | Gates 在两个值 (优先级类别 KER > 0.3 和 manifest = 100 行) 之后进行微调,否则会路由返回构建以增长 manifest。使用现有的 NeMo 框架 对运行进行微调 |
| 重新评估 | 检查更改是否有助于 | 比较当前运行和先前运行,并推荐下一个周期 |
如何对 ASR 性能进行基准测试
飞轮仍然报告熟悉的 ASR 指标,但技能会将其作为决策信号。如果发音问答不完整,下一步可能是复习,而不是模型训练。如果实体错误集中在一个类别中,下一步可能是更具针对性的数据。如果所审查的术语始终存在错误,则调整可能是合理的。
| 指标 | 测量对象 | 技能运用 |
| WER | 整个句子的错误率 | 一般 ASR 质量信号 |
| CER | 字符错误率 | 用于长期临床诊断的接近缺失信号 |
| KER | 目标临床实体的关键字错误率 | 是否识别出工作流程关键术语的主要信号 |
| SER | 句子错误率 | 显示句子中是否出现任何错误 |
在骨科实践模拟中,实体层面的指标明确了下一步:药物名称是最弱的类别,后续周期侧重于发音审查、额外的药物名称覆盖范围和模型适应性。结果并不是生产基准测试,而是展示了飞轮如何将临床 ASR 故障模式转化为具体的改进路径。
技能原生临床 ASR 质量飞轮的价值是什么?
合成音频不能取代真实的临床音频。这是一种创建目标压力测试的可控方式,特别是对于罕见术语,但生产验证仍然需要来自预期设置的真实音频。发音控制仍然需要人工审核。字典查找适用于许多医学术语,但并非每个术语都出现在可信字典中。自动发音建议可以加快审查速度,但如果不进行音频检查,则不应将其视为真实情况。
当前的基准测试很小。骨科实践模拟在少量生成样本上演示了飞轮。更有力的声明需要不公开的术语、更多的上下文、更多的演讲者、声音干扰、重复运行和真实的音频。清晰的音频性能还不够。临床环境包括警报器、重叠扬声器、口罩、远程医疗麦克风、房间混响、救护车噪音和听写伪影。下一个版本的基准测试应包括声学应力分布。
开始使用临床 ASR 智能体技能
临床 ASR 改进需要的不仅仅是一次性数据集或总分。您需要一个工作流程来帮助您定义临床概况、生成发音感知的合成音频、根据重要术语衡量 ASR 质量、适当调整模型,并重新评估结果。
本文中介绍的飞轮从简单的对话开始,到可重复的 ASR 飞轮结束。NVIDIA NeMo Data Designer 负责处理文本丰富层。Magpie TTS 多语种合成受发音控制的音频。兼容 NeMo 的清单连接了生成、评估、适应和报告。AI 智能体技能通过指导术语管理、IPA 评审、基准生成、评分和下一步决策,使流程可重复。
骨科实践模拟展示了工作流程模式:配置配置文件特定的术语列表,生成经过审核的合成音频,检查实体级错误,并决定下一步行动。更大的贡献是可重复的循环:配置文件驱动的基准测试、发音感知 TTS、明确的审查门和实体级评估。
准备好开始了吗?探索 NVIDIA 智能体技能,将临床 ASR 智能体工作流用作指南,以构建配置文件驱动的基准、查看发音、生成合成临床音频,并使用实体级指标评估 ASR 输出。