
AI 不再只是生成文本或图像,而是要针对商业、金融、客户和医疗健康服务中的现实应用进行深度推理、详细解决问题并实现强大的适应性。
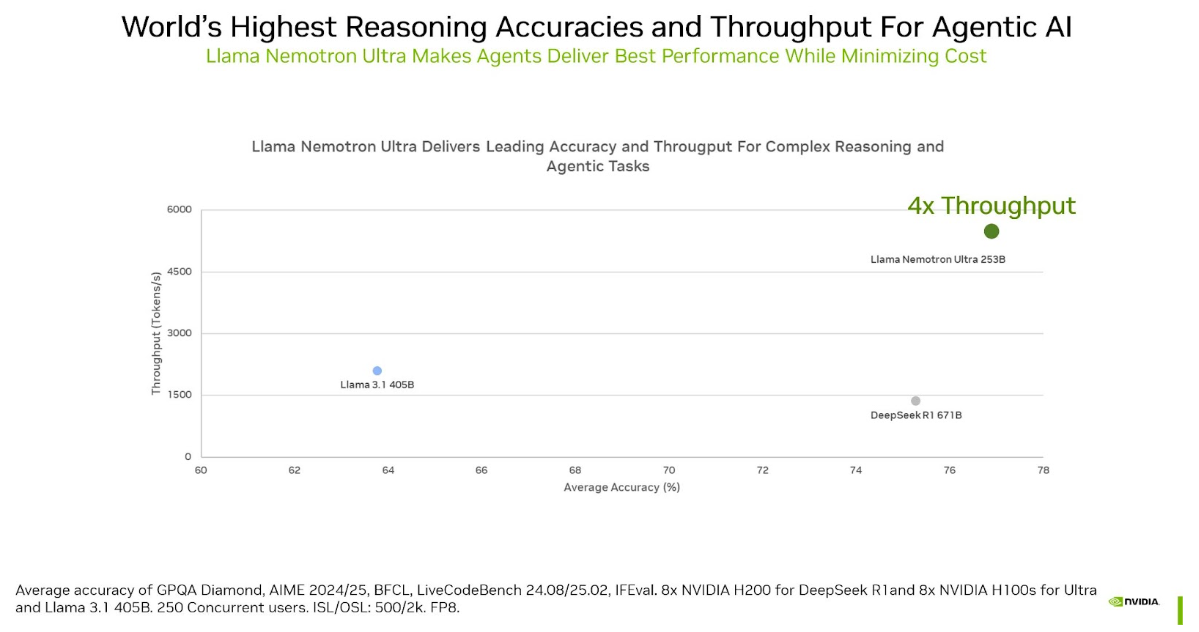
NVIDIA 最新推出的 Llama Nemotron Ultra 推理模型在智能和编码基准测试中提供了领先的开源模型准确性,同时提高了计算效率。您可以在 Hugging Face 上找到模型、权重和训练数据,以便将 AI 应用于从研究助理、编码助手到自动化工作流的各种工作中。
NVIDIA Llama Nemotron Ultra 在先进的科学编码和数学基准测试方面表现出色
Llama Nemotron Ultra 正在重新定义 AI 在科学推理、编码和数学基准测试中可以实现的目标。该模型针对复杂推理、人类匹配聊天、 检索增强生成 (RAG) 和工具使用进行了后训练,专为满足现实世界企业的需求 (从 copilot 和知识助手到自动化工作流程) 而构建,具有高影响力 AI 所需的深度和灵活性。
Llama Nemotron Ultra 基于 Meta Llama 3.1 构建,并使用商业和合成数据以及高级训练技术进行优化。它专为代理式工作流而设计,提供强大的推理能力和可访问的高性能 AI,同时降低成本。为支持更广泛地开发推理模型,NVIDIA 开源了两个用于后训练的高质量训练数据集。
这些资源为社区提供了构建高性能、高性价比模型的先机。NVIDIA 团队最近在竞争推理基准测试 @KaggleAI 数学奥运会 上获得了第一名,这证明了它们的有效性。然后,将数据、技术和见解应用于 Llama Nemotron Ultra。下一节将详细介绍这三个基准测试。
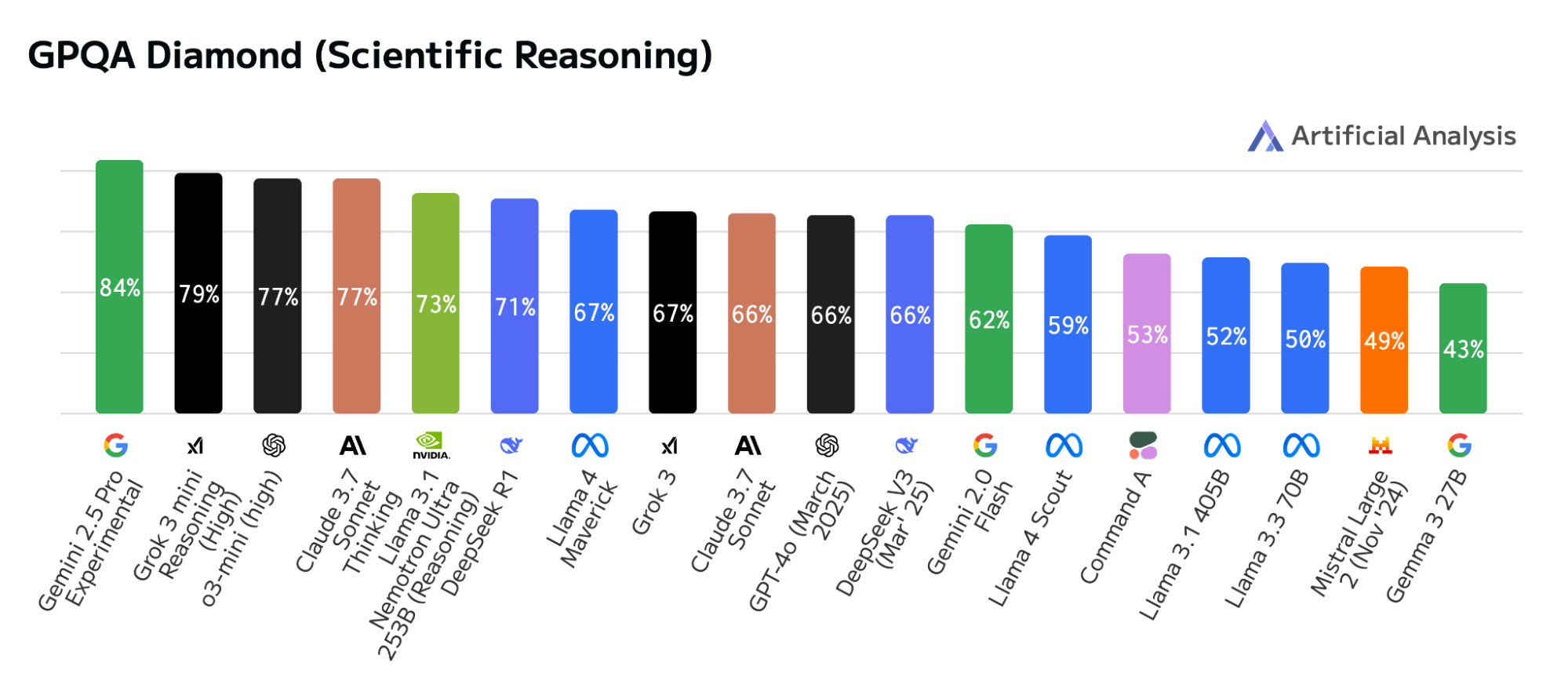
GPQA 钻石级基准测试
如图 1、2 和 3 所示,在科学推理基准测试中,Llama Nemotron Ultra 推理模型的性能优于其他开放模型。GPQA Diamond 基准测试包含生物学、物理学和化学领域中由博士级专家开发的 198 个精心制作的问题。
这些研究生水平的问题需要多步骤推理和深度理解,而不仅仅是死记硬背或表面层面的推理。虽然拥有博士学位的人类在这一具有挑战性的子集上的准确率平均约为 65%,但 Llama Nemotron Ultra 设定了新的标准 — 达到 76%,并成为科学推理领域领先的开放模型。这一结果可以在 Artificial Analysis 和 Vellum 排行榜上找到。


LiveCodeBench 基准测试
如图 4、5 和 6 所示,Llama Nemotron Ultra 除了在高级科学基准测试中表现优异外,还在 LiveCodeBench(一个用于评估现实世界编码能力的稳健基准测试)上取得了出色的性能。LiveCodeBench 专注于更广泛的编码任务,例如代码生成、调试、自我修复、测试输出预测和执行。
LiveCodeBench 中的每个问题都有日期,以确保公平的分发外评估。通过强调真正的问题解决能力而不是代码输出,它测试了真正的泛化。此结果可以在“ Artificial Analysis ”和“ GitHub – LiveCodeBench ”排行榜上找到。


AIME 基准测试
Llama Nemotron Ultra 还超越了 AIME 基准测试中的其他开放模型,后者通常用作评估数学推理能力的基准测试。 查看 LLM 排行榜 。

开放数据集和工具
Llama Nemotron 最关键的贡献之一是其开放式设计理念。NVIDIA 发布了该模型本身以及两个商业上可行的核心数据集,这有助于塑造其推理技能,这些技能目前在 Hugging Face Datasets 中处于领先地位。
OpenCodeReasoning 数据集 :包含超过 73.5 万个 Python 样本,这些样本来自 28,000 个不同的问题,来自热门的竞争编程平台。此数据集专为监督式微调 (Supervised Fine-Tuning, SFT) 而设计,使企业开发者能够在其模型中使用蒸馏高级推理功能。通过利用 OpenCodeReasoning,企业组织可以提高 AI 系统的问题解决能力,从而实现更稳健、更智能的编码解决方案。
Llama-Nemotron-Post-Training 数据集 :使用公开可用的开放模型合成生成,包括 Llama、Nemotron 系列、Qwen 系列和 DeepSeek-R1 模型。该数据集旨在提高模型在关键推理任务中的性能,是提高数学、编码、一般推理和指令遵循能力的理想选择。它提供了宝贵的资源来微调模型,以更好地理解和响应复杂的多步骤指令,帮助开发者构建更强大、更一致的 AI 系统。
通过在 Hugging Face 上免费提供这些数据集,NVIDIA 旨在普及推理模型的训练。初创公司、研究实验室和企业现在可以从 NVIDIA 内部团队使用的相同资源中受益,从而加速 代理式 AI 的更广泛采用,即可以在复杂的工作流程中自主推理、规划和行动的 AI。
企业就绪型功能:速度、准确率和灵活性
Llama Nemotron Ultra 是一种商用模型,可用于各种代理式 AI 用例,包括编码助手、客户服务聊天机器人、自主研究智能体和面向任务的助手。它在科学推理和编码基准测试方面的强大性能使其成为需要准确性、适应性和多步骤问题解决能力的现实应用的强大基础。
Llama Nemotron Ultra 提供出色的模型准确性,同时在开放推理模型类别中提供领先的吞吐量。其效率 (吞吐量) 直接转化为成本节约。通过使用 Neural Architecture Search (NAS) 方法,我们可在保持模型性能的同时大幅减少模型的内存占用,从而在数据中心环境中运行模型所需的工作负载和 GPU 数量更少。
在此过程之后,模型经历了全面的后训练流程,包括监督式微调和强化学习 (RL) ,以增强模型的能力,使其在推理和非推理任务方面表现出色。该模型支持推理`On` 和`Off` 功能,允许企业仅在需要时激活推理,并减少更简单的非代理任务的开销。
开始使用
NVIDIA 已将 Llama Nemotron Ultra 封装为 NVIDIA NIM 推理微服务,并针对高吞吐量和低延迟进行了优化。NVIDIA NIM 利用行业标准 API,在本地或云端提供无缝、可扩展的 AI 推理。
- 直接在浏览器中试用 Llama Nemotron Ultra NIM
- 从 Hugging Face 下载 Llama Nemotron Ultra 模型
- 要为您的用例训练自定义推理模型,请下载 OpenCodeReasoning Dataset 和 Llama-Nemotron-Post-Training Dataset 并自定义