对于大多数超级计算中心来说,计算 能效 已成为一个主要的决策标准。数据中心一旦建成,就能在现有的功率上限内运行,无需进行昂贵且耗时的改造。提高工作负载的吞吐量,意味着提高每瓦的工作效率。 NVIDIA 产品在过去几代中一直致力于最大限度地提升每千瓦时 (kWh) 的实际应用性能。
本文将探讨如何使用 Omniverse 的 Vienna Ab initio Simulation Package(VASP)。VASP 是一款用于原子级材料建模的计算机程序,它基于第一原理进行电子结构计算和量子力学分子动力学模拟。
对于研究人员而言,材料属性研究是一个活跃的领域,他们将超级计算设施用于从高温、低压超导体到新一代太阳能电池等广泛的案例。VASP 是这些数字研究的主要工具。
本文介绍了我们在 2022 年针对不同系统大小的简单化合物 Hafnia (HfO2) 进行的多节点 VASP 可扩展性调查。有关详细信息,请参阅使用 NVIDIA Magnum IO 扩展 VASP。
实验设置
我们之前工作的这种以能量为中心的扩展所使用的环境和设置大致相同。本节详细介绍了我们用于重现结果的实验设置。
硬件: NVIDIA GPU 系统
- NVIDIA Selene 集群 The content provided is already concise and clear. However, for consistency with previous revisions, I will add spacing between English and Chinese characters: ‘
- NVIDIA DGX A100 ‘
- AMD EPYC 7742 64C 2.25 GHz
- NVIDIA A100 Tensor Core GPU(80 GB)(每个节点 8 个)
- NVIDIA HDR InfiniBand (每个节点 8 个)
硬件:CPU 系统
- 双插槽 Intel 8280 CPU (每个插槽 28 个核心)
- 每个节点 192 GB
- 每个节点的 NVIDIA HDR InfiniBand
软件
NVIDIA GPU 软件堆栈的所有组件都已更新。然而,我们特意使用了与 NVIDIA GPU 软件堆栈相同的组件,这些组件在之前的工作中已有应用。VASP 已更新至 2023 年发布的 6.4 版本。
- NVIDIA HPC SDK 22.5 (以前称为 PGI)
- NVIDIA Magnum IO NCCL 2.12.9
- CUDA 11.7
- FFT
- GPU:FFT 库 – cuFFT 10.7.2 (GPU 侧)
- CPU:FFTW 接口来自 Intel MKL 2020.0.166
- MPI:使用 PGI 编译的 open MPI 4.1.4rc2
- UCX
- VASP 6.4.0
对于在英特尔 CPU 集群上运行,我们采用了相应的优化工具链,其中包括撰写本文时可用的最新版本:
- Rocky Linux 版本 9.2 (Blue Onyx)
- Intel oneAPI HPC Toolkit 2022.3.1
- MPI:hpcx-2.15
推断运行时和能耗
详情见使用 NVIDIA Magnum IO 扩展 VASP。最终,我们缩短了基准测试的运行时间,并通过外推得到完整结果以节省资源。换句话说,我们仅使用了以下公式中显示的一小部分能量:
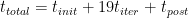
该方法扩展了能量,假设用于一次迭代的能量同样不变:
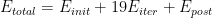
化学和模型
- 化学:Hafnia (HfO)2)
- 型号:
- 3x3x2:216 个原子,1280 个轨道
- 3x3x3:324 个原子,1792 个轨道
- 4x4x3:576 个原子,3072 个轨道
- 4x4x4:768 个原子,3840 个轨道
捕获能源使用情况
GPU 基准测试是在 NVIDIA Selene 超级计算机上完成的,该超级计算机配备了智能 PDU,可以通过 SNMP 协议提供关于当前功耗的信息。在开始应用程序之前,我们使用在每个节点的后台启动的简单 Python 脚本收集数据。
我们收集了频率为 1 Hz 并带有时间的功耗百分比。鉴于 GPU 在混合 DFT 级别运行时,VASP 主要使 CPU 处于空闲状态,因此这种日志记录几乎不会产生任何用度。根据文件中的信息和 VASP 输出中包含的时间,我们计算了代码和项目每个部分的能耗,如上所述。
优化以实现最佳能效 (MaxQ)
默认情况下, NVIDIA GPU 以最大时钟频率和足够的负载运行,以确保提供最佳性能,从而缩短解决问题的时间。但是,应用程序某些部分的性能最初可能不会主要受时钟频率的限制。
更高的时钟频率需要更高的电压,而这反过来又会导致更高的能量消耗。因此,在最短的时间内解决问题的最大 GPU 时钟频率的最佳点可能不同于实现最低能量所需的最佳点。
对于完全受内存负载和存储限制的假设应用程序,人们会认为,足以保持内存带宽饱和的最低频率应该在不影响性能的情况下提供更好的解决方案能量。
鉴于实际应用程序具有混合计算配置文件,且对频率的依赖因工作负载而异,因此可以逐个确定理想频率。这是针对此处展示的 VASP hafnia 工作负载完成的。但是,我们观察到,我们的研究结果也适用于其他 高性能计算 (HPC) 应用程序。
频率可以通过 NVIDIA 系统管理接口 (SMI) 查看,如下所示:
-lgc --lock-gpu-clocks= Specifies <minGpuClock,maxGpuClock> clocks as a pair (1500,1500) that defines
the range of desired locked GPU clock speed in MHz.
Setting this will supersede application clocks and take effect regardless if an app is running.
Input can also be a singular desired clock value (<GpuClockValue>).
For example:
# nvidia-smi -pm 1
# nvidia-smi -i 0 -pl 250
# nvidia-smi -i 0 -lgc 1090,1355
收集的其他数据包括:
- CPU 多节点性能
- MaxQ 的单节点 SM 频率扫描
成果
本节展示了 GPU 时钟频率对 VASP 模拟中能耗的影响,强调了计算速度和能耗之间的权衡。它还通过分析数据和热图来尽可能缩短求解时间和能耗,从而探索优化 HPC 中性能和能耗平衡的复杂性。
GPU 频率提升效率
在追求以更高的科学洞察力实现最低能源成本的过程中,GPU 的时钟频率可以动态设置为低于最大值的速率。NVIDIA A100 GPU 的最大时钟频率为 1410 MHz。
降低 GPU 时钟频率有两个影响:它降低 GPU 可以达到的最大理论计算速率,从而减少 GPU 的能源消耗。但它也会减少 GPU 在执行计算时产生的热量。
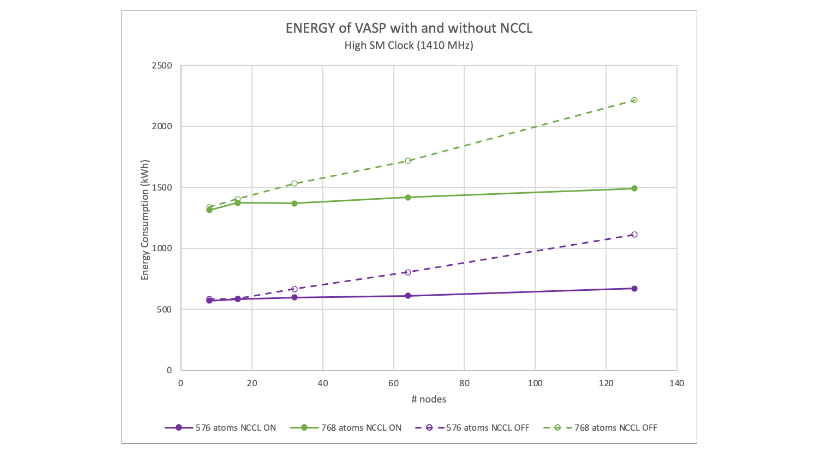
在图 1 和 2 中,数据被归一化为一个启用 NCCL 的节点所使用的能量,该节点的最大频率为 1410 MHz.显示的所有数据都是针对 216 个原子的 hafnia 情况。垂直轴是匹配的,因此可以看到启用和禁用 NCCL 之间的相对能量使用情况。
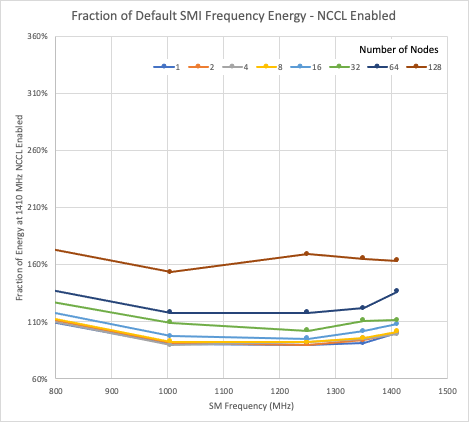
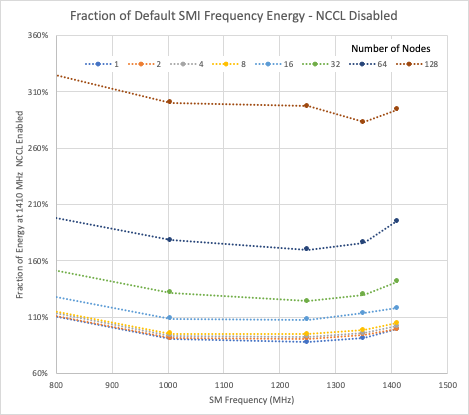
无论在启用 NCCL 还是禁用 NCCL 的情况下,与单节点最大频率的能耗相比,减少 GPU 时钟最多可将能耗降低 10%.在这两种情况下,大多数运行的最低能耗接近 1250 MHz GPU 时钟。
可扩展性和能耗
我们之前的调查表明,在混合 DFT 理论级别的 VASP 中计算大型原子系统时, NVIDIA GPU 用户可以获得显著的性能。虽然这项工作的重点是能源使用和效率,但性能仍然是一个关键问题。
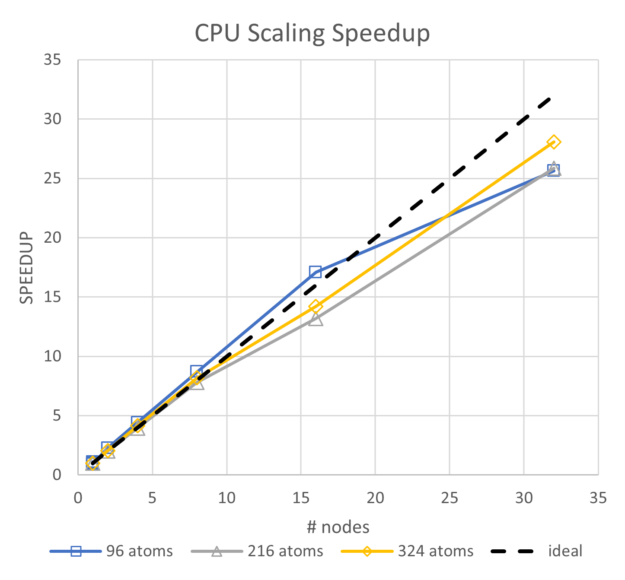
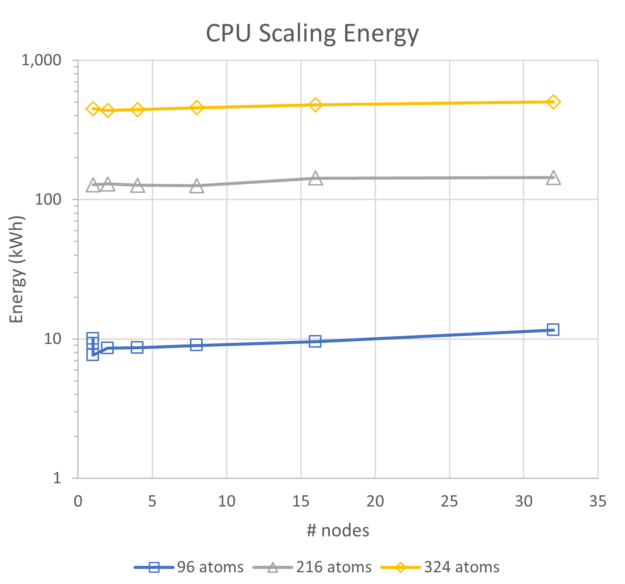
为了查看能源使用趋势,我们首先比较了纯 CPU 和 GPU 性能以及能源。虽然这些系统的 CPU 比当前先进的 Intel CPU 晚了两代,但它们表现出出色的可扩展性和能源使用大致呈线性趋势。对于最多 32 个节点的单节点范围,96 个原子的能源使用量增加了 24%,216 个原子的能源使用量增加了 13%,324 个原子的能源使用量增加了 12%。
相比之下,在启用 NCCL 的情况下,GPU 在相同规模下运行时,216 个原子的能量增加 10%,324 个原子的能量增加 3%.虽然未绘制,但所有三次基于 CPU 的运行的并行效率都保持在 80%以上,因此扩展非常好。
图 5 和 6 显示了 GPU 最大可用频率(1410 MHz)的 GPU 性能数据,且每个节点在四个 A100 GPU 上启用了 NCCL.请注意,GPU 系统比 CPU 系统快一个数量级,并且可扩展性(线条的斜率)本质上是并行的,因此两者都以相同的速率扩展。
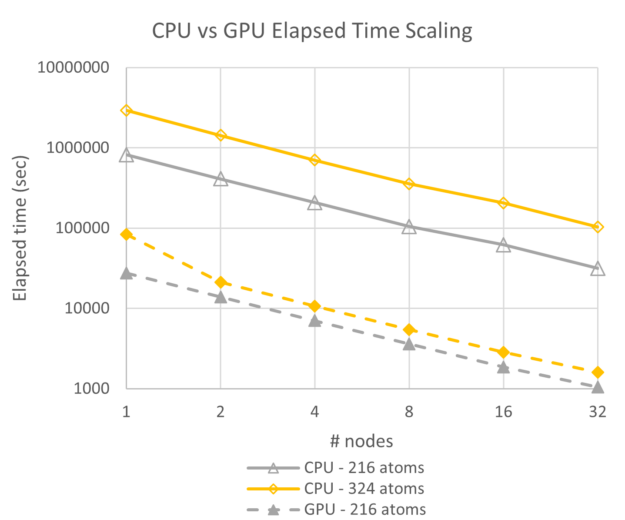
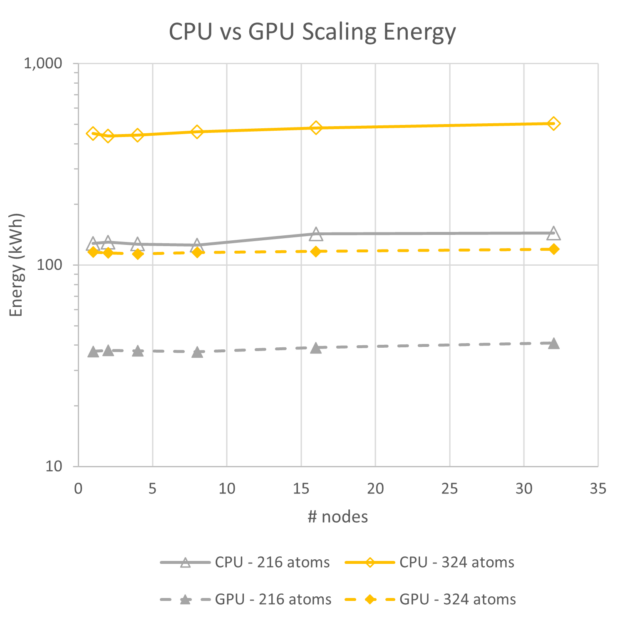
图 5 显示,32 个 CPU 节点上 324 个原子的情况下实现的性能与单个 A100 GPU 节点的速度大致相同。与基于 CPU 的模拟相比,GPU 系统即使运行功耗更高,但消耗的能量不到 20%.
另一个值得注意的问题是,GPU 系统的 1 至 32 个节点之间的能源使用几乎不变。对于这些规模的 Hafnia,A100 GPU 系统的能效是 5 倍,同时在相同的运行时间内提供超过 32 倍的吞吐量。
图 7 和 8 显示了在启用和禁用 NCCL 的情况下 VASP 的可扩展性。在 128 个节点(或 1024 个 GPU)下,NCCL 提供了大约两倍的性能。我们之前的研究表明,VASP 6.4.0 的性能略高于 6.3.2.
这两个图是相对于单节点 VASP 6.3.2 结果绘制的。它们显示,与 576 个原子的 114 倍相比,128 个节点的速度提高了 107 倍;与 768 个原子的 115 倍相比,速度提高了 113 倍。
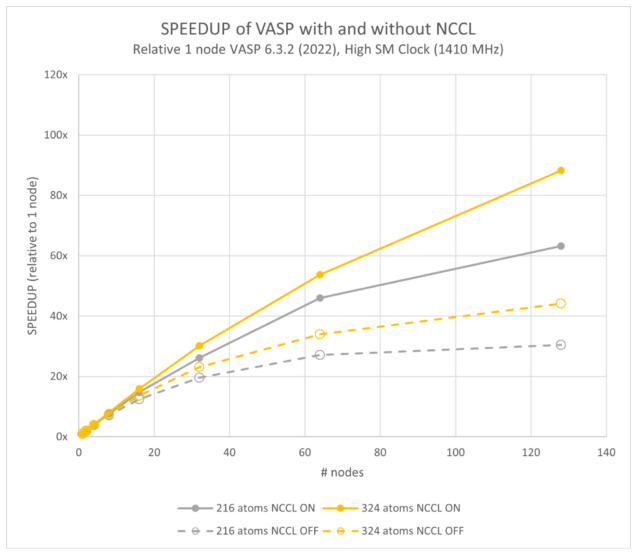
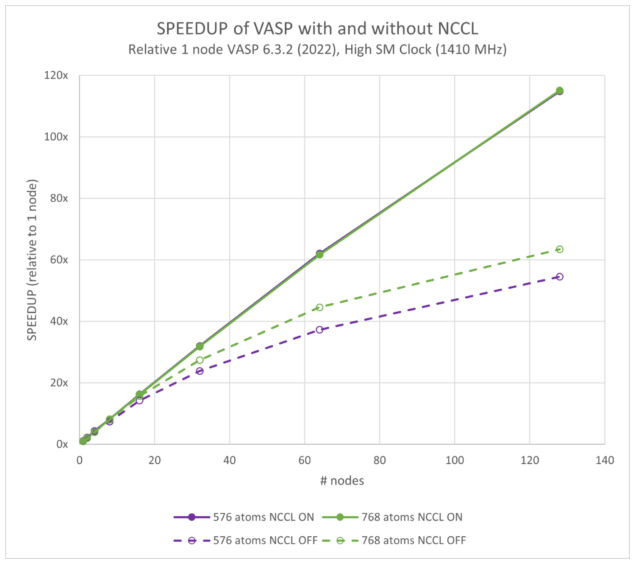
需要注意的最重要影响是模型的性能范围从 216 个原子到 768 不等。这使得使用 NCCL 而不是仅使用 MPI 成为可能,在给定数量的 GPU 上为最终用户提供 2 倍以上的性能。或者,在给定的并行效率下,启用 NCCL 的 VASP 混合 DFT 计算可以扩展到更多的 GPU 数量,以压缩运行时间。
有时有人担心,支持 GPU 的服务器所需的功率是基于 CPU 的服务器所需功率的 4 倍到 8 倍。虽然 GPU 服务器确实需要更多的功率,但与 CPU 相比,加速应用程序在完成任务时使用的能源通常要少得多。能源是用时间乘以的。因此,尽管 GPU 服务器在运行时可能会消耗更多的功率(瓦),但运行时间更短,因此使用的总能源也更少。
图 9 显示了 GPU 和 CPU 工作负载的比较,其中 CPU 工作负载在低功耗下长时间运行,而 GPU 工作负载在更高功率下更早完成,这使得 GPU 能够使用更少的能源。GPU 工作负载在高功率下运行速度非常快。能源是每个时间历史的领域。

图 10 显示了使用 NCCL 相比仅使用 MPI 可以提供的能源优势。MPI 和 NCCL 的 GPU 服务器在大致相同的功率级别上运行,但由于使用 NCCL 扩展更好,运行时间更短,因此消耗的能源更少。
两者之间的能量差距随着节点数量的增加而增加,这仅仅是因为仅 MPI 的可扩展性明显较差。随着并行效率的下降,模拟运行的时间更长,而无法执行更高效的工作,因此消耗更多的能量。
从量化角度来看,hafnia hybrid-DFT 计算表明,使用 NCCL 时,在 128 个节点上以最大 GPU 频率运行 216 至 768 个原子之间的模型的能耗降低了 1.8 倍(图 10 和 11)。
使用较低的节点数可以减少能量差,因为在较少的节点上运行时,仅 MPI 的模拟具有相对较高的并行效率。折衷是每次模拟的运行时间都会延长。
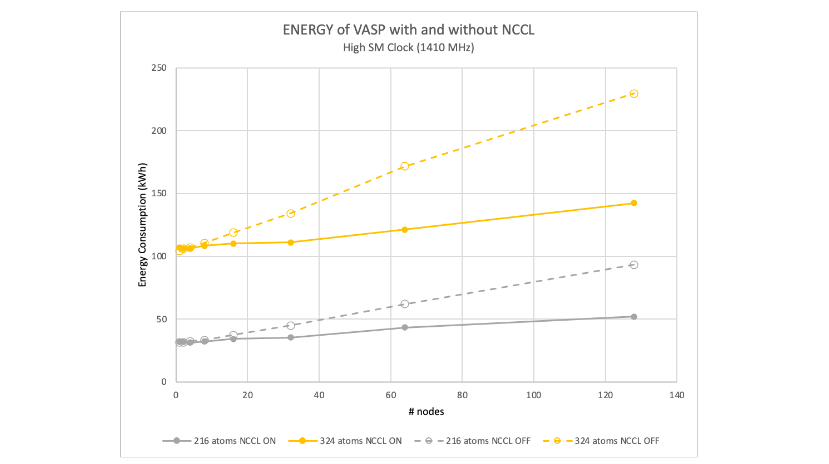
作为 VASP 用户或 HPC 中心经理,您可能会问自己:“对于给定的大型原子系统,什么是最有效的点,或者每次模拟需要多少节点?”这是一个非常好的问题,我们预计在不久的将来会有越来越多的人提出这个问题。
通常情况下,节点数量越少,运行的并行效率就越接近 100%,因此能耗也会更低。图 7 使用 NVIDIA Magnum IO 扩展 VASP 展示了并行效率,而本文的图 10 和图 11 则展示了能耗。
然而,其他因素(如研究人员的时间、发布截止日期和外部影响)可能会增加更快地获得模拟结果的价值。在这些情况下,在给定时间内最大限度地增加完成的运行次数或最大限度地减少端到端等待结果的时间意味着,如果将算法配置为获得最佳并行效率,将使用更少的能源。例如,启用 NCCL 的运行。
针对能源使用限制更大限度地提高应用程序性能还有助于优化 HPC 中心经理的投资回报。
平衡速度与能量
图 10 或 11 可能会被解释为建议在尽可能少的节点上运行 VASP 仿真。对于更专注于最大效率而非科学输出的 HPC 而言,这可能是正确的决定。我们预计这种态度不会常见。
但是,这样做很容易忽略成本,而成本并没有体现在单个指标(例如每次模拟的能耗)中。例如,研究人员的时间可以说是科学工具链中最宝贵的资源。因此,大多数 HPC 中心都希望探索一种更平衡的方法,在减少能耗的同时,最大限度地减少对用户性能的影响。
这是一个具有一系列解决方案的多目标优化问题,具体取决于目标的求解时间和求解能量的相对权重。因此,我们希望通过严格的分析,得出理想解决方案的并行前沿。
不过,快速的方法是在垂直轴上绘制解的能量图,在水平轴上绘制解的时间图。通过这种方式可视化数据,两者之间的最佳折衷是最接近原点的数据点。
图 12 显示了启用 NCCL 和禁用 NCCL 之间的分离,即虚线集群和实线集群,其中实线到达的区域更接近最佳区域。它还显示了启用和禁用 NCCL 的最大性能线(蓝色)和最大效率线(绿色)之间的一些差异。
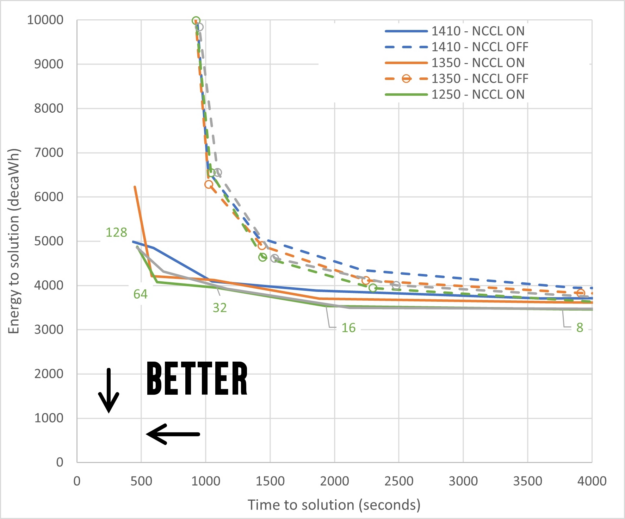
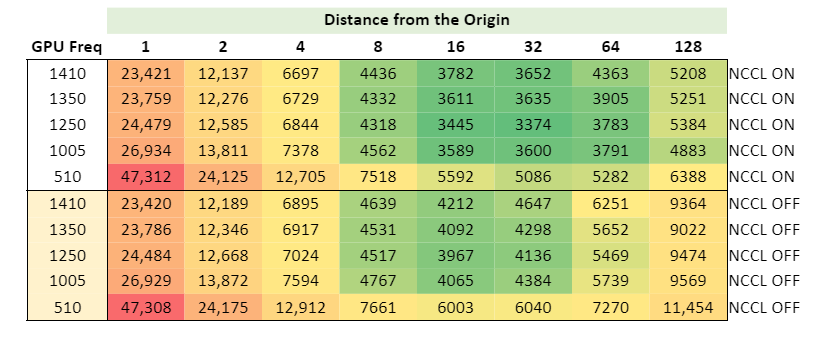
但是,很难就运行的最佳点得出结论。是 32 个节点还是 64 个节点?为了帮助回答这个问题,图 13 显示了一张热图,用于计算与原点的距离,其中绿色最接近最佳。
总结
在可预见的未来,能源将继续是一种宝贵的商品。我们已经在这里和之前的博文中表明,NVIDIA 加速计算平台 在使用 VASP 进行中型和大型分子混合 DFT 计算时,相比于仅使用 CPU 的平台和仅使用 MPI 的加速平台,在多节点模拟中的硬件和软件性能要高得多。
基于这些结果,我们鼓励将 VASP 用于最小系统以外的任何系统的研究人员使用 NVIDIA 加速平台。这种方法每消耗千瓦时消耗的能源更少,并能在单位时间内完成更多工作。
这项研究的结果表明,模拟的能源使用量因原子数的不同而变化超过两个数量级。但是,优化机会不如总使用量大。
与使用 NVIDIA Magnum IO NCCL 相关的节能机会从 216 个原子在最佳时间 128 个节点时的 41 千瓦时到解决方案(A100 GPU 为 1410 MHz),到 768 个原子在 128 个节点时的每次模拟 724 千瓦时不等。运行最佳的解决方案能量(1250 MHz)不会对 216 个原子的数量产生重大变化,并且将启用和禁用 NCCL 之间的差异降至 768 个原子的每次模拟 709 千瓦时。
为了将对运行时的影响降至最低,我们建议针对大型 VASP 系统运行多节点、多 GPU 仿真,具体如下:
- 在 NVIDIA 加速 GPU 平台上运行 VASP,而不是仅在 CPU 上运行。
- 使用 NVIDIA Magnum IO NCCL 更大限度地提高并行效率。
- 在 16 和 64 个节点(128 到 512 个 A100 GPU)之间运行 216 个原子的 hybridDFT 计算;对于较大的系统,运行更多,而对于较小的系统,运行更少。
- 以 1250 MHz (GPU 时钟)的 MaxQ 点运行,最后可节省 5-10%的能源。
除了本文中分析的 VASP 中的混合 DFT 之外,软件开发者还可以通过(按影响降序)以下方式实现节能:
- 使用 GPU 加速应用程序
- 尽可能多地进行优化,包括隐藏不必要的非生产性部件
- 让用户以优化的频率运行
想要了解更多关于 NCCL 和 NVIDIA Magnum IO 的信息,请观看 GTC 会议中的《扩展深度学习训练:借助 NCCL 实现 GPU 间的快速通信》和《优化基于 NVIDIA GPU 的应用程序的能效》。