
图形是许多现代数据和分析功能的基础,可在不同的数据资产中查找人、地点、事物、事件和位置之间的关系。根据一项研究,到 2025 年,图形技术将被用于 80% 的数据和分析创新,这将有助于促进跨组织的快速决策。
在处理包含数百万个节点的图形时,CPU 上的 Louvain 等算法的执行时间可能长达几个小时。这种长时间的处理时间不仅会影响开发者的工作效率,而且会导致总体性能结果欠佳。
利用 GPU 的并行处理能力可以显著缩短图形训练时间。基准测试结果表明,GPU 加速在将基于 CPU 的计算速度提高 100 倍以上方面具有巨大潜力。
这种显著的速度提升展示了将 GPU 集成到 图形分析 (graph analytics) 可以实现 100 倍的性能提升。
了解组件
这种颠覆性架构的核心是以下三个关键组件,每个组件都发挥着关键作用。
使用 cuGraph 实现 GPU 加速
cuGraph 是 NVIDIA GPU 加速的图形分析库,它在加速图形计算方面发挥着重要作用。传统的基于 CPU 的图形处理通常会成为瓶颈,尤其是在处理大规模图形时。cuGraph 利用了 NVIDIA A100 GPUs 的高性能计算 (HPC) 设计,能够以无与伦比的速度处理复杂的图形算法。
PageRank、Louvain 和 Betweenness Centrality 等图形算法本质上是可并行的,因此非常适合 GPU 加速。NVIDIA A100 GPU 中的数千个核心支持同时处理数据,与基于 CPU 的方法相比,大幅缩短了计算时间。
TigerGraph 图形数据库功能
cuGraph 利用 GPU 优化图形分析,而 TigerGraph 图形数据库则通过高效存储和查询互联数据来补充 GPU 加速。TigerGraph 的分布式架构、其 Turing 完备的 GSQL 语言以及对图形数据的原生支持,使其能够以非凡的灵活性处理复杂的关系,以及实时查询和更新。
TigerGraph 的数据结构称为 Graph 模型,可提供高度可扩展的图形数据表示。它可优化数据局部性和遍历,减少图形处理过程中的 I/O 瓶颈。TigerGraph 与 cuGraph 的无缝集成可确保数据在图形数据库和 GPU 加速分析之间轻松流动,从而更大限度地提高性能。
使用高级功能增强 GSQL
为了完成这一融合,ZettaBolt 设计了自定义用户定义函数 (UDF),充当 TigerGraph 和 cuGraph 之间的桥梁。UDF 使您能够编写自己的 C++代码,并将其无缝集成到 TigerGraph 生态系统中。
它们可在 Thrift RPC 层上实现 GSQL 和 cuGraph Python 服务之间的通信。这可在图形数据库和 GPU 加速分析之间实现数据和计算的流畅流动,从而为图形算法优化带来新的可能性。
传统和加速的 PageRank 计算
本节将探讨如何将这种强大的 GPU-CPU 融合与实际示例结合使用。它介绍了运行 PageRank 计算的两种不同方法:传统的基于 CPU 的方法tg_分页排名和加速的加速 PageRank它利用了 GPU-CPU 融合架构。
传统方法:tg_pagerank
这种传统方法采用 tg_ 分页排名查询以计算 PageRank 分数。它依赖于基于 CPU 的处理,适用于无法使用或不需要 GPU 加速的场景。想要了解更多详情,请访问 tigergraph/gsql-graph-algorithms GitHub。
Query tg_pagerank(
v_type, # Vertex type representing persons in the graph
e_type", # Edge type representing friendships between persons
max_change=0.001, # Maximum change in PageRank scores for convergence
maximum_iteration=25,# Maximum number of iterations for convergence
damping=0.85, # Damping factor for the PageRank calculation
top_k=100, # Number of top results to display
print_results=True,# Whether to print the PageRank results
result_attribute="", # Optional attribute to store the PageRank results
file_path="", # Optional file path to save the results
display_edges=False# Whether to display the edges during computation
)
加速方法:accel_pagerank
使用加速 PageRank 查询,利用 GPU-CPU 融合架构显著提升性能,使其成为大规模图形处理的理想选择,如 GSQL。
QUERY accel_pagerank( INT numServers, #Number of servers to distribute computation INT seg_size, #Segment size for processing STRING v_type, #Vertex type STRING e_type, #Edge type FLOAT max_change=0.00001,#Maximum change threshold for convergence INT maximum_iteration=50,# Maximum number of iterations FLOAT damping=0.85, #Damping factor for PageRank calculation INT top_k=100, #Top-k results to retrieve BOOL print_accum=TRUE, #Print accumulated results (default: TRUE) STRING result_attr="", #Result attribute name STRING file_path, #File path for storing results BOOL display_edges=FALSE,#Display edges in results (default: FALSE) STRING profile_path, #Path for profiling data STRING graph_name, #Name of the graph STRING server_name, #Server address UINT port, #Port for communication UINT total_segments, #Total segments for computation STRING tmp_dir, #Temporary directory for processing INT streaming_limit=300000, #Streaming data limit BOOL cache_graph=FALSE #Cache the graph (default: FALSE) )
无缝过渡
在传统的 tg_ 分页排名和加速的 PageRank 查询之间切换就像更改 API 调用一样简单。您无需担心底层的技术细节。过渡旨在轻松进行,因此您可以根据自己的需求轻松调整图形处理。无论您是需要 GPU 加速的强大功能,还是更喜欢熟悉基于 CPU 的处理,您的图形分析都将无缝满足您的需求。
创建架构
本节介绍架构的分步过程,让 GPU-CPU 融合的魔力如生。
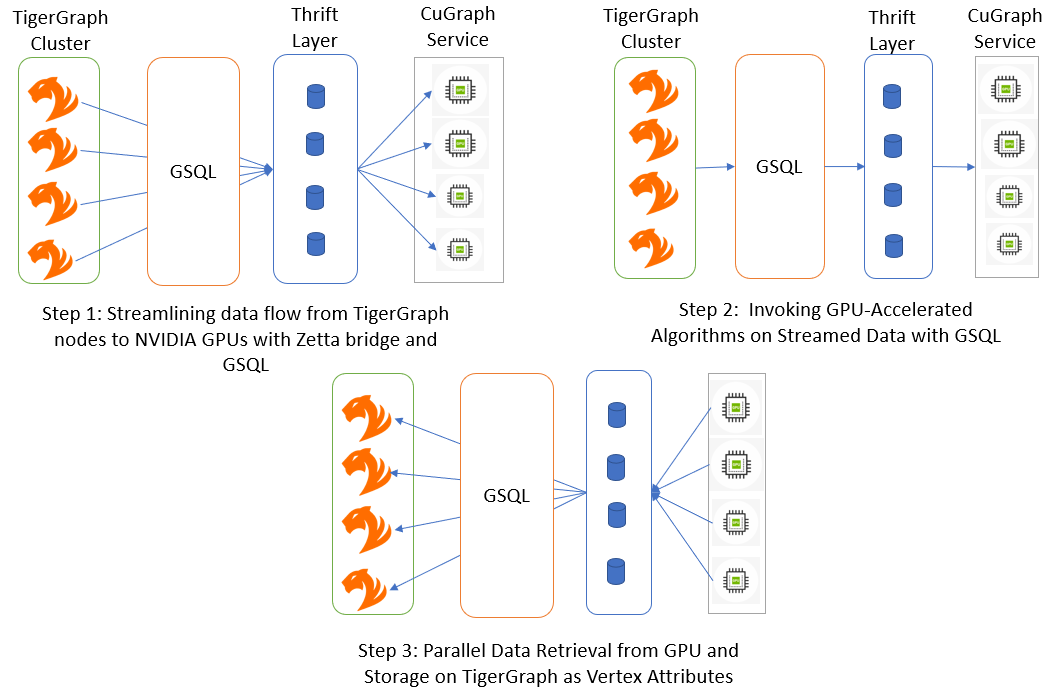
将边缘从 TigerGraph 流式传输到 cuGraph
首先,将边缘从 TigerGraph 高效流式传输到 cuGraph 以进行 GPU 加速处理。当边缘从 TigerGraph 并行读取时,系统会批量收集这些边缘,直到边缘计数达到预定的值(例如 100 万)。批量完成后,系统会通过 Thrift RPC 层将其刷新到 cuGraph.
批量串流边缘可优化数据传输,减少开销,并确保 GPU 加速的处理能够接收连续的数据流。串流流程可高效准备图形数据,以用于后续基于 GPU 的计算。
使用 PageRank 的 GPU 加速计算
现在,整个图形数据都驻留在 NVIDIA A100 GPU 上的 cuGraph 内存中,该架构已准备好释放其真正的潜力。
以经典的 PageRank 算法为例。PageRank 根据传入链路的数量和质量计算图形中节点的重要性。该算法是 GPU 加速的绝佳候选算法,因为它具有迭代和并行性。cuGraph 基于 GPU 的 PageRank 算法并行处理整个图形,高效地遍历网络并迭代地更新 PageRank 分数。
使用 Thrift RPC 层获取结果
GPU 加速的计算完成后,是时候获取结果了。现在位于 cuGraph 内存中的 PageRank 分数使用 Thrift RPC 层获得,并带回 UDF.
实现 100 倍加速突破
性能比较不言自明 – 现实世界的基准测试展示了使用这种混合架构所取得的令人惊叹的结果。100 倍加速是图形算法性能的重大飞跃。
借助此架构,开发者可以在社交网络、推荐系统、基于图形的机器学习 (ML) 等不同领域获得竞争优势。
图形算法性能比较
此基准测试展示了两种著名图形算法(Louvain 和 PageRank)的性能,在由 NVIDIA A100 80GB GPU 和 AMD EPYC 7713 64 核处理器提供动力支持的高性能 GPU 基础设施上使用 TigerGraph 和 TigerGraph 以及 cuGraph,并且使用具有 512GB RAM 的单节点配置。
基准测试数据集
由 Linked Data Benchmark Council (LDBC) 开发的 Graphalytics,是一款全面的基准套件,专门设计用于评估图形数据库管理系统 (GDBMS) 和图形处理框架的性能。它提供真实的数据集、各种工作负载和一系列图形算法,帮助研究人员和组织评估系统的效率和可扩展性。有关更多信息,请参阅 LDBC Graphalytics Benchmark。
| Graph | Louvain | PageRank | |||||
| 顶点 | 边缘 | CPU (秒) |
CPU+GPU (秒) |
加速 (x) |
CPU (秒) |
CPU+GPU (秒) |
加速 (x) |
| 2396657 | 64155735 | 1265 | 7 | 172 | 1030 | 7 | 147 |
| 4610222 | 129333677 | 2288 | 12 | 188 | 2142 | 19 | 113 |
| 8870942 | 260379520 | 小行星 4723 | 27 | 174 | 4542 | 38 | 120 |
| 17062472 | 523602831 | 小行星 9977 | 77 | 130 | 8643 | 46 | 188 |
最佳实践和注意事项
在您踏上 GPU-CPU 融合之旅时,请考虑以下最佳实践和注意事项,以优化图形分析。
GPU 加速算法选择
CPU 和 GPU 之间的协同作用对于为 GPU 加速选择合适的算法至关重要。虽然一些图形算法具有高度并行性,并从 NVIDIA A100 GPU 中的数千个核心中受益匪浅,但其他图形算法可能需要更多的顺序处理,从而使 CPU 成为更好的选择。通过从战略角度将可并行算法卸载到 GPU,您可以在图形计算中实现显著的加速和效率,同时利用 CPU 和 GPU 的优势实现最佳性能。
高效的数据预处理
在高效的数据预处理阶段,CPU 和 GPU 的协同作用发挥着至关重要的作用。虽然 TigerGraph 强大的图形数据库功能可以在 CPU 上处理初始数据检索和处理,但 GPU 加速的 cuGraph 库可以高效地流式传输和批处理图形数据,以进行进一步计算。GPU 的并行处理能力可确保数据的持续流动,从而最大限度地减少数据传输阶段的开销和瓶颈,从而实现数据的无缝流动,从而加速分析。
GPU 显存管理
有效的 GPU 显存管理是避免图形计算期间性能瓶颈的关键考虑因素。CPU 和 GPU 在此过程中都发挥着重要作用。在将相关数据传输到 GPU 进行处理之前,CPU 可确保高效的数据处理和分配。在 GPU 方面,并行处理能力可以高效利用可用内存在大规模图形上执行计算。CPU 和 GPU 在内存管理方面的密切合作有助于实现经优化的流畅的 GPU 加速图形处理。
未来的工作和可能性
在用于图形分析的 GPU-CPU 融合领域,有许多令人兴奋的可能性和增强功能值得探索。下文详细介绍了未来工作和潜在开发的一些关键领域。
减少 GPU 显存占用
优化 GPU 显存使用对于处理大型图形和提高算法可扩展性至关重要。未来的重点领域包括内存高效型数据结构、图形分区技术和智能缓存机制,以减少 GPU 显存占用。高效管理内存可在提高性能的同时处理更大的图形。
扩展图形算法库
当前的架构支持 PageRank、Louvain 和 Betweenness Centrality 等图形算法。但是,还有大量图形算法等待探索。扩展图形算法库以包含更多样化和更复杂的算法,将使开发者能够应对更广泛的图形分析挑战。
集成对 GNN 和其他 RAPIDS 库的支持
图神经网络 (GNNs) 已成为各种图形相关任务的热门选择。集成对 GNN 和其他 RAPIDS 库(例如 cuML 和 cuGraphML)的支持将通过先进的深度学习功能来丰富该架构,以处理基于图形的 ML 任务。这种集成将实现对传统图形算法和新兴 ML 模型的无缝探索,从而促进图形分析的创新和通用性。
性能优化和调优
持续的性能优化和调优对于充分发挥 GPU-CPU 融合的潜力至关重要。执行深入的分析和基准测试、利用特定于 GPU 的优化以及针对特定图形特征的微调算法,将提高速度和效率。
总结
本文探讨了 GPU 和 CPU 的无缝融合如何增强图形算法的性能。TigerGraph 强大的数据库能力与 cuGraph GPU 加速相结合,创造了一种无与伦比的合作关系。流畅的数据流实现了惊人的 100 倍速度提升,推动图形分析进入新的前沿。
GPU-CPU 融合将重塑团队探索数据以及浏览复杂网络和关系的方式。从社交网络到机器学习,GPU – CPU 融合将开启无限可能。未来的工作领域包括优化内存效率、扩大算法范围和微调性能,确保此架构始终处于图形分析的前沿。拥抱融合并重新定义数据探索的界限。
准备好开始使用加速图形处理了吗?如果您拥有 TigerGraph (3.9.X) 和 NVIDIA GPU (支持 RAPIDS),请联系 TigerGraph 或 Zettabolt 来表达您对探索加速图形处理的兴趣。他们将指导您完成初始步骤,为您提供必要的信息,并协助您建立加速图形处理的基础设施。
基础设施到位后,您将可以访问旨在优化图形处理任务的加速查询。这些查询利用 NVIDIA GPU 和 TigerGraph 平台的强大功能来增强性能。探索加速图形处理功能并对其进行基准测试,以体验图形分析性能的显著提升。
TigerGraph 和 Zettabolt 将在您探索加速图形处理和高效处理大规模图形数据的新可能性时,继续提供帮助并回答问题。