
当 AlphaFold2 在 2020 年彻底改变药物研发时,其成功完全依赖于科学家自 1971 年以来收集并保存在蛋白质数据库中的大约 17 万个蛋白质结构。测量数据是所有 AI 模型和工作流的支柱,可在创建时处理数据、实时处理重要数据并分析数据以获得深入见解。随着现代传感器和检测器的兴起,没有人需要等待 50 年才能为开创性的 AI 模型收集足够的数据。
从生成 1 MHz 重复频率光子脉冲的 Linac 相干光源 II (LCLS-II) 等大型科学设施,到工业 CT 扫描仪和高带宽软件定义的无线电,输出率不断提高,并将瓶颈从缺失数据转移到当前的“收集、存储、分析”架构,而该架构从未被设计用于处理高数据
通过迁移到适应性强的数据采集工作流,在来源处对数据进行预处理可以减少数据洪流造成的信息损失,同时加快从数据收集到发现的过程。
NVIDIA DAQIRI (集成实时仪器的数据采集) 将数据采集从不灵活的以硬件为中心的设计转变为以软件为中心的适应性架构。作为 NVIDIA Holoscan 平台的高性能网络库,DAQIRI 可将现有的高带宽流检测器和传感器直接连接到 NVIDIA 软件生态系统。例如用于实时多模态、多速率处理的 Holoscan;用于实时推理的 NVIDIA TensorRT;以及用于流压缩的 NVIDIA nvCOMP。除了 NVIDIA 生态系统之外,DAQIRI 还可以直接串流到自定义仪器专用软件平台。
借助 DAQIRI,开发者和仪器组装商能够创建数据采集工作流,在无需修改仪器的情况下处理流式数据,以执行过滤、推理、压缩、事件选择和自适应控制等任务。
通过将仪器输出直接流式传输到配备 NVIDIA ConnectX 网络接口卡 (NIC) 的边缘超级计算功能中,仪器可以实时持续监控实验、对不断变化的条件做出响应并触发操作。这些边缘超级计算系统的规模多种多样,从 NVIDIA DGX Spark 到 NVIDIA IGX 平台,再到基于节点和机架的解决方案 (例如 NVIDIA RTX Pro 服务器或 VR200) ,具体取决于特定仪器所需的计算能力。
这种方法使研究人员能够立即洞察传入数据,同时还可以使用 AI 和其他计算密集型方法准备选定的输出,以便在超级计算设施中进行下游处理。
A-GHOST:使不可保存的数据可供搜索
与原始设计相比,欧洲核子研究组织 (CERN) 的高亮度大型强子对撞机 (HL-LHC) 升级将使亮度提高 10 倍。为了处理更高的数据速率,ATLAS 检测器将升级其当前的选择系统。新设计仍将使用双阶段选择系统,但现在,在第一阶段进入存储阶段后,选定事件的带宽为 1 MHz (高于 100 kHz) ,在第二阶段进入存储阶段后最高可达 10 kHz (高于 1 kHz) 。即使在这种提高的速度下,这仍然意味着拒绝了在线系统中 99% 以上的碰撞。
A-Ghost 项目使用 DAQIRI,通过高效网络使 GPU 更接近原始检测器数据,从而对被标称选择路径丢弃的流应用更强大的 AI 驱动搜索。
研发工作的重点是探索如何利用串流链路,连接计划在 HL-LHC 期间使用的基于现场可编程门阵列 (FPGA) 的定制硬件板和支持 GPU 的高性能处理场。借助该架构,由 CERN Openlab、芝加哥大学和伦敦大学学院科学家领导的研发工作将通过部署卷积自动编码器 (CAE) 、时间卷积神经网络 (TCCN) 和基于 Transformer 的模型等强大的模型,对整个数据流进行实时分析,这些模型计划使用原型硬件进行测试。
DAQIRI 的工作原理
DAQIRI 旨在以 100 Gbps 及以上的线速处理高带宽以太网数据,包括 UDP 和 RoCE v2 流量。为此,该架构完全绕过了 Linux 内核。
通过利用数据平面开发套件 (DPDK) ,DAQIRI 提供零拷贝访问,将数据直接从网卡路由到 GPU 的直接内存访问 (DMA) 缓冲区。这种内核旁路机制可降低通常与传统网络堆栈相关的延迟和 CPU 开销,确保大量仪器数据流到达 GPU,以便立即进行处理。
NVIDIA DAQIRI 主要特性:
- High Throughput, Low Latency
- 使用合适的硬件和 CPU/ NUMA 调优,在任何接口上实现线速
- Customized Receive Processing
- 自动数据包重新排序、数据类型转换和基于硬件的流转向
- Zero Memory Copy to GPU
- 对 GPU 张量的直接 NIC 环形缓冲区访问 (批处理和标头数据拆分) 可在 PCIe 传输时保持延迟
- YAML-Driven Configuration
- 经过优化且可定制的样板网络配置,便于部署
- Flexible Data Movement Backends
- Linux Socket、DPDK 和 RoCEv2 支持,可满足不同的应用和硬件需求
- Plug and Play C++ and Python APIs
- 在几分钟 (而非几小时) 内构建与其他 GPU 库的实时应用和接口”
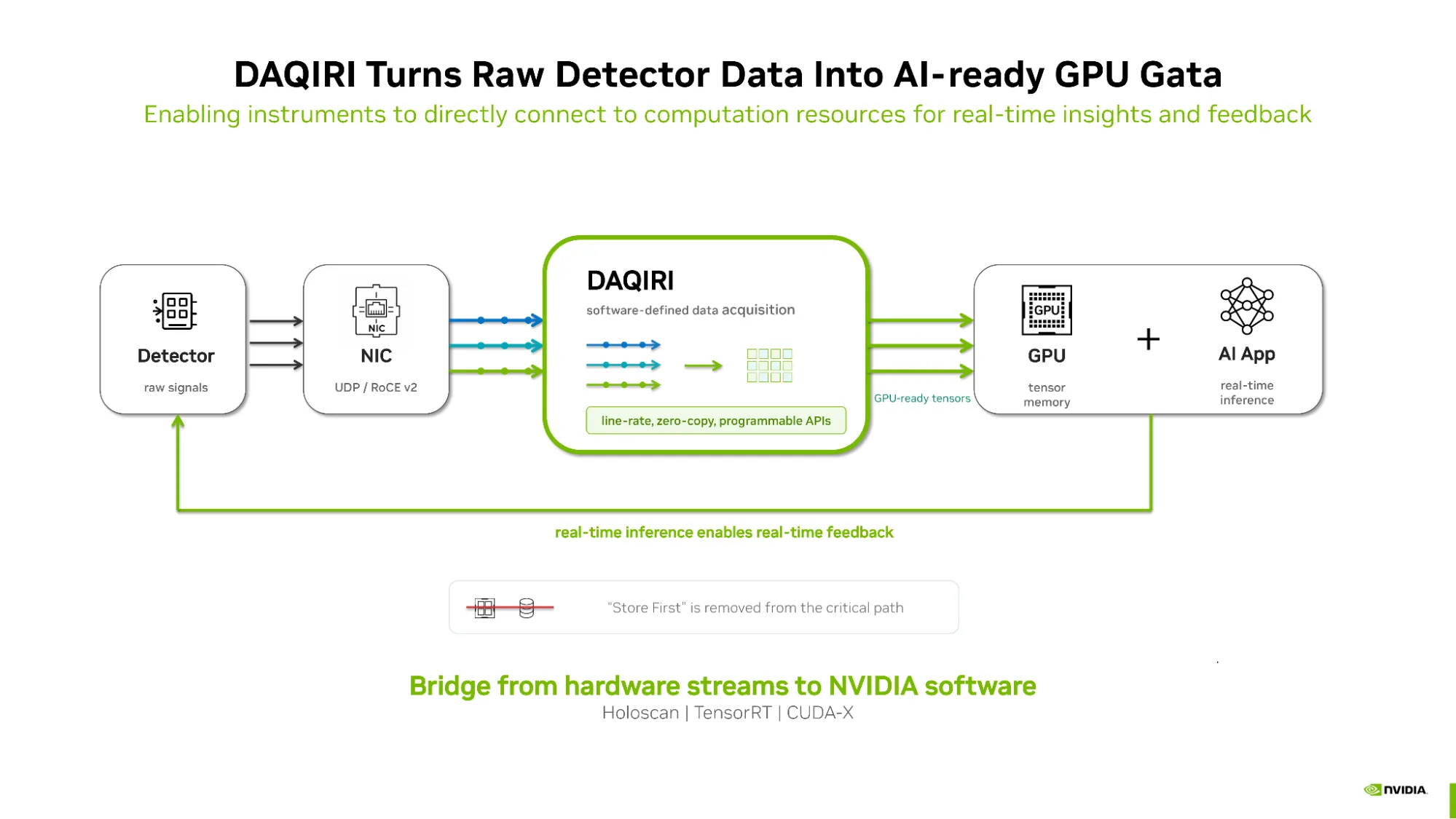
图 1. DAQIRI 充当从高带宽检测器流到 NVIDIA 加速计算的软件定义桥接器,消除了关键路径中的“存储优先”,因此仪器可以处理流中的数据、运行 AI 推理并实时响应
虽然底层数据移动依赖于底层网络优化,但 DAQIRI 为仪器制造商抽象了这种复杂性。开发者可以使用可访问的 C++ 和 Python API (通过可读的 YAML 文件进行配置) 编排数据采集工作流。
DAQIRI 不会管理单个网络数据包或手动分配内存,而是会自动将传入的网络数据包直接批处理到 GPU 张量中。这使得开发者可以完全专注于编写自定义推理或过滤逻辑,而不是管理网络协议。
下方演练展示了仪器设计师如何将高速数据流配置为可检查的小片段,然后使用简短的 C++ 循环来接收 GPU – Ready 张量。
DAQIRI 应用程序从配置文件开始。该配置描述了应用程序运行之前的数据路径:要使用的 NIC、数据包缓冲区由哪些 GPU 拥有、数据包应如何过滤,以及应如何组合接收到的数据包负载以进行下游处理。
这是大多数仪器工作流所需要的传递点:已驻留在 GPU 上的批量形状张量,而非单个网络数据包。重新排序阶段还可以在组装张量时转换有效载荷数据。例如,传感器前端可能会在线缆上发送紧凑的 int4 样本,而 GPU 处理或 AI 推理阶段则需要 fp16。
DAQIRI 可以在 GPU 重新排序步骤中执行该转换,从而避免在应用程序中进行单独的解压缩。这些文件可针对任何硬件配置轻松进行编辑,更多示例请参阅“鸡尾酒会手册 (Cocktail Book)” (代码示例)。
DAQIRI 演示
从顶层 DAQIRI 设置开始。这将建立原始串流路径,分配 CPU 核心来管理 DAQIRI,并保持日志足够简洁以便部署。
%YAML 1.2
---
daqiri:
cfg:
version: 1
stream_type: "raw" # Use DAQIRI's high-speed DPDK/GPUDirect path.
master_core: 3 # CPU core used to start and manage DAQIRI.
log_level: "info"
接下来,定义 DAQIRI 将使用的 GPU 显存区域。rx_packets 是原始数据包缓冲区通过 GPUDirect 到达的位置,而 rx_tensor 是 GPU 工作负载使用的已完成、重新排序的张量。缓冲区大小还会使 int4-to-fp16 扩展显式化。
memory_regions:
- name: "rx_packets"
kind: "device" # Raw packets land directly in GPU memory.
affinity: 0 # Use GPU 0.
num_bufs: 16384
buf_size: 8192 # Headers + sequence number + 8000B payload.
- name: "rx_tensor"
kind: "device" # Reordered output also stays on the GPU.
affinity: 0
num_bufs: 128 # Number of completed tensors DAQIRI can queue.
buf_size: 32768000 # 1024 packets * 8000 int4 bytes * 4 bytes after fp16 expansion.
然后将配置绑定到物理接收接口。这将通过 PCIe 地址为 NIC 命名,启用流隔离,并分配轮询队列。队列一次批量处理 1024 个数据包,但可以在 2 毫秒后刷新,因此下游处理不会无限等待。
interfaces:
- name: "rx0"
address: "0000:00:00.0" # RX NIC PCIe address from lspci.
rx:
flow_isolation: true # Only packets matching the flow below are accepted.
queues:
- name: "q0"
id: 0
cpu_core: 9 # CPU core polling the NIC queue.
batch_size: 1024 # Build tensors from 1024 packets.
timeout_us: 2000 # Flush a partial batch after 2 ms.
memory_regions: ["rx_packets"]
流规则将已接受的流量缩小到预期的 UDP 流,并将匹配的数据包发送到队列 0。这样可将仪器或网络的其余流量排除在此接收路径之外。
flows:
- name: "data_flow"
id: 100 # This flow is attached to the reorder rule.
action: {type: queue, id: 0}
match: {udp_src: 4096, udp_dst: 4096}
最后,重新排序配置会将数据包负载转换为应用实际需要的张量形状。它会跳过数据包头,使用序列号恢复排序,批量处理 1024 个数据包,并在 GPU 重新排序步骤中将紧凑的 int4 有效载荷转换为 fp16 值。
reorder_configs:
- name: "packets_to_tensor"
reorder_type: "gpu" # Reorder and pack the batch on the GPU.
memory_region: "rx_tensor"
payload_byte_offset: 68 # Skip Ethernet/IP/UDP headers and sequence number.
flow_ids: [100]
data_types:
input_type: "int4" # Payload format on the wire.
output_type: "fp16" # Tensor format for the model/kernel.
endianness: "host"
method:
seq_packets_per_batch:
sequence_number:
bit_offset: 512 # Sequence number starts at byte 64.
bit_width: 32
packets_per_batch: 1024
有了 YAML 中的这些详细信息,应用程序代码有意变得很小。首先,从配置文件初始化 DAQIRI,并声明将接收已完成数据包批量的突发句柄。
// Initialize DAQIRI with a config file.
daqiri::daqiri_init("rx_reorder.yaml");
daqiri::BurstParams* burst = nullptr;
然后向 DAQIRI 询问下一个已完成的突发任务。当应用程序收到指针时,DAQIRI 已经将数据包重新排序到连续的 GPU 显存中,因此代码可以将张量直接交给模型或 CUDA 内核。
// Receive packets; DAQIRI reorders them into contiguous GPU memory.
daqiri::get_rx_burst(&burst);
// The reordered batch is now a GPU tensor ready for processing/inference.
auto* tensor = daqiri::get_packet_ptr(burst, 0);
run_model_or_kernel(tensor);
GPU 作业完成后,请将缓冲区返回至 DAQIRI,以便在下一次突发时重复使用。
将 DAQIRI 引入您的传感器或检测器
通过从不灵活、以硬件为中心的收集范式转向软件定义、支持 AI 的架构,DAQIRI 消除了科学数据采集的传统瓶颈。现在,开发者可以处理串流数据,在边缘运行实时 AI 推理,并确保仅将高质量的 AI 就绪型数据发送到 HPC 设施进行更深入的分析。
立即开始使用 DAQIRI 将实时处理集成到您的实时串流工作流中!
访问 GitHub 上的 DAQIRI 登陆页面,了解基准测试和示例
致谢
在此,我们要感谢来自 CERN 的 David Miller 和 Ioannis Xiotidis 在 A-Ghost 数据采集工作流中使用 DAQIRI 所做的工作和开展的协作,以及他们为撰写这篇博客文章所做的协作和技术审查。我们还要感谢 Alexis Girault,他的 ANO 文档为这项工作提供了参考。特别感谢 NVIDIA 贡献者 Cliff Burdick、Chloe Crozier、Jay Carlson、Mahdi Azizian、Julien Jomier 以及整个 Holoscan 团队提供的专业知识、指导和支持。