
自主、长期运行的 AI 智能体的兴起带来了一种新型计算需求,即维护大型上下文窗口、生成并发子智能体,以及在不依赖云的情况下持续迭代的任务。安全和隐私问题也加速了向本地代理的转变。
开发者通过 NVIDIA NemoClaw 编排执行在其拥有的硬件上运行自主代理,可以在设备上保留敏感的上下文,保留对代理访问内容的直接控制,并消除每词元成本。
NVIDIA DGX Spark 旨在本地构建和运行自主智能体。在 Computex 2026 上,NVIDIA 大幅简化了从开箱到运行 AI 智能体的过程,只需几分钟即可完成 (不包括初始模型下载,这取决于网络速度) 。此外,Qwen3.6 和引导式多节点集群设置也提高了模型性能,适用于需要扩展到单个设备以外的团队。
本文将介绍这些更新对开发者构建代理式 AI 系统的意义,包括如何安装 NVIDIA NemoClaw、NemoClaw 设置的内容,以及如何在 DGX Spark 上使用 OpenClaw 构建和运行您的首个智能体。
预备知识
- 用于下载初始模型的主动互联网连接
- 熟悉终端可选配置步骤
从开箱到运行本地智能体
过去,让本地 AI 智能体运行涉及采购合适的模型、配置推理后端、安装运行时并将其连接在一起。即使对于经验丰富的开发者来说,这个过程也可能需要一天的大部分时间。新的精简版 NemoClaw 安装路径改变了这一点。
对于新系统,首先要体验开箱和首次设置 DGX Spark。DGX Spark 系统软件的最新版本 2026 年 6 月版本,提供更精简的开箱即用体验 (OOBE) ,因此用户可以更快地联系本地代理。借助此版本,在初始设置期间,默认情况下将不再安装无线更新,从而缩短设置时间,让用户更快地访问 Ubuntu 桌面。
NemoClaw 是一个开源蓝图,可将三项功能打包到一次安装中:开放模型、智能体线束 (例如,Hermes Agent 或 OpenClaw) 以及 NVIDIA OpenShell 运行时。OpenShell 是一个安全的沙盒执行环境,旨在更安全地运行自主代理。它为智能体循环增加了访问控制、隐私保护和操作护栏。结合设备端推理,这可为开发者提供更强大的默认安全和隐私状态,以处理代理式工作负载。
第 1 步:安装 NemoClaw
下图 1 显示了从 OOBE 完成到在 DGX Spark 上运行 NemoClaw 代理的完整路径。
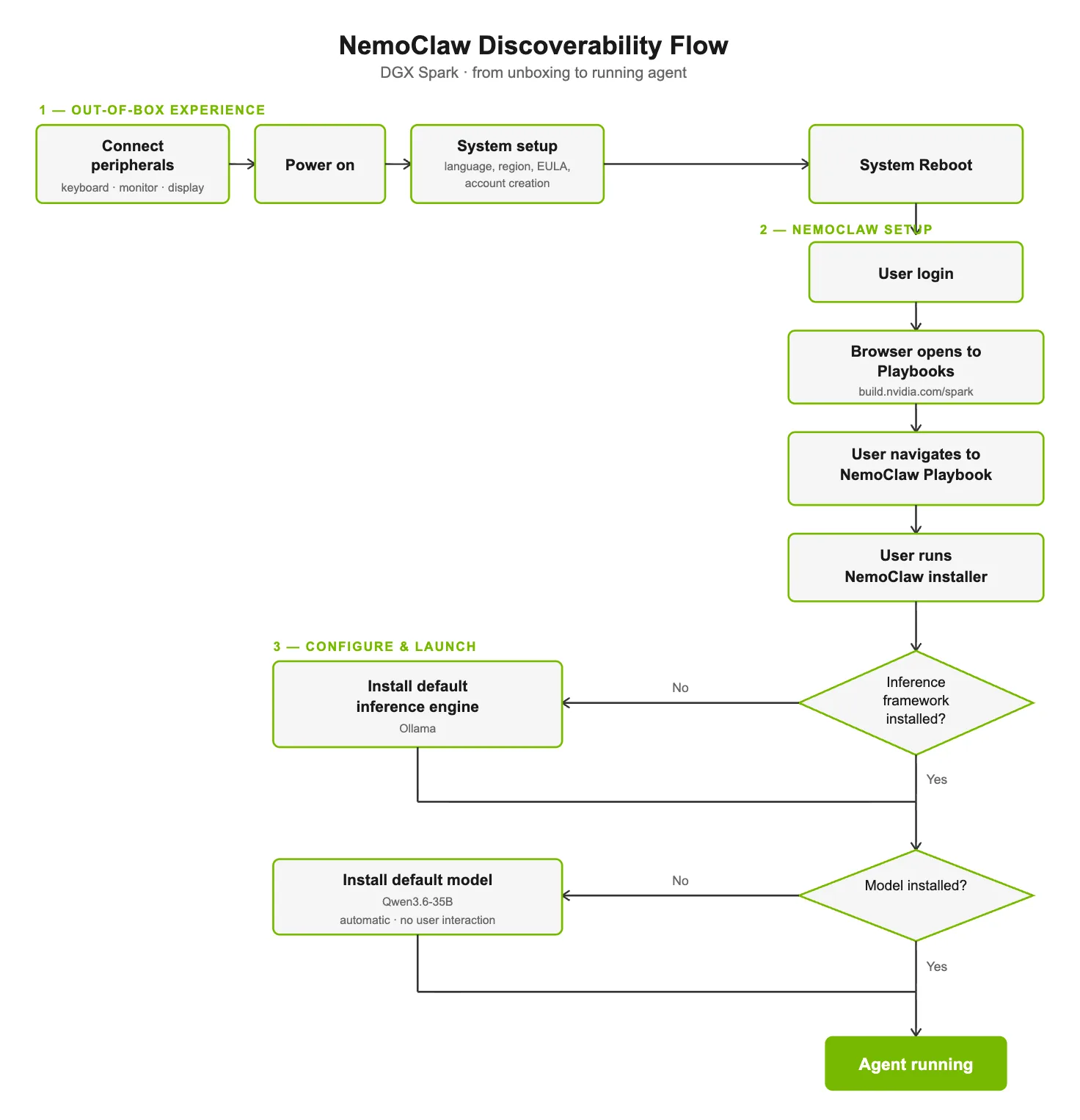
完成 OOBE 后,DGX Spark 会重启并打开 build.nvidia.com/spark,并在 NemoClaw 剧本的醒目位置进行引导式演示。运行此命令以安装 Node.js (如有需要) ,安装 OpenShell,克隆最新的稳定版 NemoClaw,构建 CLI,然后运行板载向导以创建沙盒。
curl -fsSL https://www.nvidia.com/nemoclaw.sh | bash |
安装向导将引导您完成设置:
- 接受 NemoClaw 和 OpenClaw 许可证 — 输入“Yes” (是) 进行确认
- 运行 express install — 通过输入 Y 进行确认
- 设置本地 Ollama 并自动下载 Qwen3.6-35B
详细了解如何在 DGX Spark/ GB10 系统上安装 NemoClaw:从 DGX Spark 上的 NemoClaw 开始 →
第 2 步:联系代理
安装完成后,您就可以自定义代理了。
首先,使用 WebUI 进行交互:
nemoclaw <sandbox name> gateway-token --quiet |
然后在浏览器中打开标记化 URL:http://127.0.0.1:18789/#token=<WEBUI_TOKEN>。精确使用 127.0.0.1– 网关原点检查需要它 (不是 localhost) 。
发送快速测试消息 "hello 或“what can you do?”,以确认整个堆栈已启动。本地 Ollama 模型已被选中;NemoClaw 会在引导过程中自动进行配置。
第 3 步:构建首个智能体
在沙盒运行后,NemoClaw 应用手册提供了四个可立即运行的智能体,每个智能体都有策略设置、入门提示和个性化指导:
- Daily Personal News Digest (每日个人新闻摘要) – 预先安排的上午简报会,内容包括您的主题,并在 Telegram 上发布结构化摘要
- 软件开发智能体 — 读取本地项目目录、构建计划、编写和审查自己的代码,除了本地推理之外,没有任何出站网络
- Deck 和 Document Reviewer — 在文件发布前对其进行红色小组检查,返回按严重程度排名的不一致、未经来源声明和可访问性问题清单
- Calendar Negotiator — 调度办公室主任,将“我们何时可以见面?”线程转换为已确认的日历活动
第 4 步:进一步自定义
沙盒运行后,塑造智能体行为的主要手段包括:
- 系统提示 — 编辑控制面板中智能体的指令,调整智能体的响应方式,以及智能体在行动前应该询问的内容。更具体的提示会产生更可靠的智能体。
- 工具权限 — OpenShell 网络策略控制代理可以调用的外部目标。权限范围缩小可减少意外行为。
- 集成 — 如果您在入职培训期间启用了消息渠道,则表示可以在此处联系智能体。通过手机向它发送消息,它将使用相同的本地模型进行响应。
开发者可以通过交换不同的模型、调整 OpenShell 权限以及将智能体连接到本地工作流,进一步进行自定义。要使用其他模型启动新的沙盒,请运行 nemoclaw onboard --fresh --gpu,并在向导过程中选择其他模型。请注意 – fresh 会破坏并重建现有沙盒 – 使用 --name <new-name> 创建额外的沙盒,而不会影响现有沙盒。完整的 NemoClaw 安装说明 和型号目录可在 NVIDIA NGC 上获取。
小贴士:缩小范围。在首次运行时,为智能体指定一项范围广泛的单一任务,例如在本地文档中“总结文件”或“回答问题”。在扩展其权限之前,验证响应和工具调用是否正确。
在您进行迭代时,一些命令值得您随身携带:
| 命令 | 它的作用 |
|---|---|
nemoclaw <sandbox name> status |
显示沙盒状态和推理运行状况 |
nemoclaw <sandbox name> logs --follow |
实时串流沙盒日志 |
nemoclaw list |
列出所有已注册的沙盒 |
使用 Qwen3.6-35B 的 DGX Spark 代理
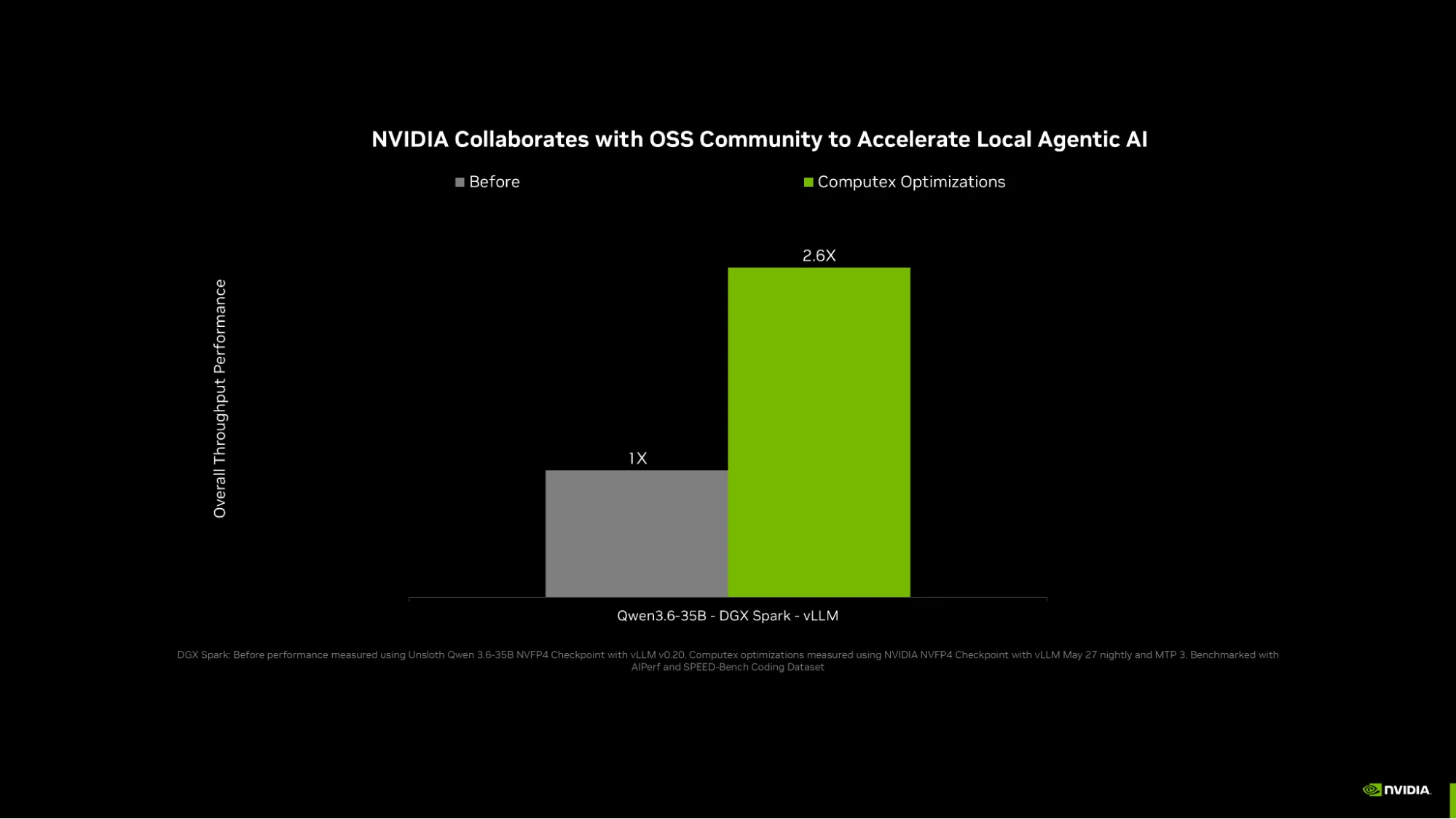
借助采用 MTP 优化的 NVIDIA NVFP4 量化检查点,开发者可以在 vLLM 上使用顶级代理式模型 (如 Qwen 3.6 35B) ,体验高达 2.6 倍的推理速度。进一步改进了 vLLM CUDA Graph 对使用 FlashInfer 的 MTP、跨 FlashInfer MoE 内核的 BF16 自动调整、TinyGEMM 和 cuBLAS BF16 路径的支持。
纵向扩展:NVIDIA Sync 中的集群助手
对于需要超过单个 DGX Spark 所能提供的内存或吞吐量的开发者,NVIDIA Sync 中的集群助手可自动完成将两到四个 DGX Spark 单元连接到高带宽集群的过程。
模型级别的集群十分重要:两个 DGX Spark 节点提供 256 GB 的统一内存 (足以容纳约 400B 参数模型) ,四个节点提供 512 GB。这足以运行大型 MoE 模型、具有多个并发推理实例的多智能体工作流,或者微调受益于分布式内存的作业。
设置集群需要配置 ConnectX-7 网络。每个 DGX Spark 都有支持 200 Gbps RoCE 的 ConnectX-7 网卡,但要正确使用它们,需要配置 netplan、设置节点到节点的 SSH 信任、验证每个链路的带宽,以及了解目标拓扑的正确 IP 分配方案。集群助手通过 Sync 中的引导式工作流简化了网络配置。
Sync 的配置
从已在 Sync 中注册的设备开始,集群助手将完成:系统就绪性检查 ( OTA 版本、sudo 访问) 、使用在每个节点上并行运行的探针进行 CX-7 拓扑检测,并将 LLDP/ BPDU 证据与接口和 IP 检查相结合、IP 规划和解冲突以及 netplan 应用、通过 ib_write_bw / ib_write_lat 验证带宽和延迟,以及节点间 SSH 设置
支持的物理配置包括双节点直接连接 (单根 QSFP 线缆,无交换机) 、三节点环形连接 (三根 QSFP 线缆,每个节点均有两个 CX-7 端口处于活动状态) ,以及通过 QSFP 交换机实现的两到四个节点,最低要求如下所示:
- 至少 4 个端口 QSFP56-DD
- 突破 25/ 50/ 100/ 200/ 400G
- 建议每个端口的最高端口速度为 200G-400G
- 1 个 1/ 10GbE 管理以太网端口
- 支持 RoCE v2
- 交换容量/ 吞吐量:最低 0.8 -1.6 Tbps
有关 NVIDIA Sync 集群助手和支持的拓扑的文档,请参阅 NVIDIA Sync 文档。
详细了解 DGX Spark
这三种功能现已推出:
- NemoClaw 简化安装: 从 DGX Spark 上的 NemoClaw 开始 →
- NemoClaw 应用示例:设置示例 NemoClaw 智能体 →
- 将 DGX Spark 引入 NVIDIA Brev:在 NVIDIA Brev 上注册您的 DGX Spark →
开始构建
Computex 2026 上的 DGX Spark 更新减少了构建生产级本地智能体的两大障碍:创建首个智能体所需的时间以及访问运行大型模型所需的计算能力。
经过简化的 NemoClaw 安装可让开发者从开箱到运行中的 OpenClaw 智能体,并将 Qwen3.6-35B 作为默认模型和内置的安全执行环境。对于需要更多资源的团队,Sync 中的集群助手消除了专业知识障碍,无法启动具有完整 ConnectX-7 性能的多节点集群。