
随着上下文窗口变长,高效移动大型模型权重对性能至关重要。解决此问题的常用方法是量化,这是一种将模型权重压缩为较小数据格式的优化技术。NVFP4 是一种量化格式,是 NVIDIA Blackwell 架构引入的创新 4 位浮点。
这就是我们新的 Nemotron 3 Ultra NVFP4 检查点背后的方法:我们使用 NVIDIA Model Optimizer 将模型量化为 NVFP4。其结果是,在处理解码密集型工作负载时,该模型的推理吞吐量比 GLM-5.1 754B FP4 模型高 5.9 倍,同时在几乎所有基准测试中都达到了 BF16 的准确性,如图 1 所示。
虽然 NVFP4 的性能优势已得到充分理解,但生成高质量 NVFP4 检查点的过程并非如此。本文将介绍我们如何使用 NVIDIA Model Optimizer 将 Nemotron 3 Ultra (550B) 量化为 NVFP4,并向开发者展示如何为自己的模型生成最佳量化检查点。
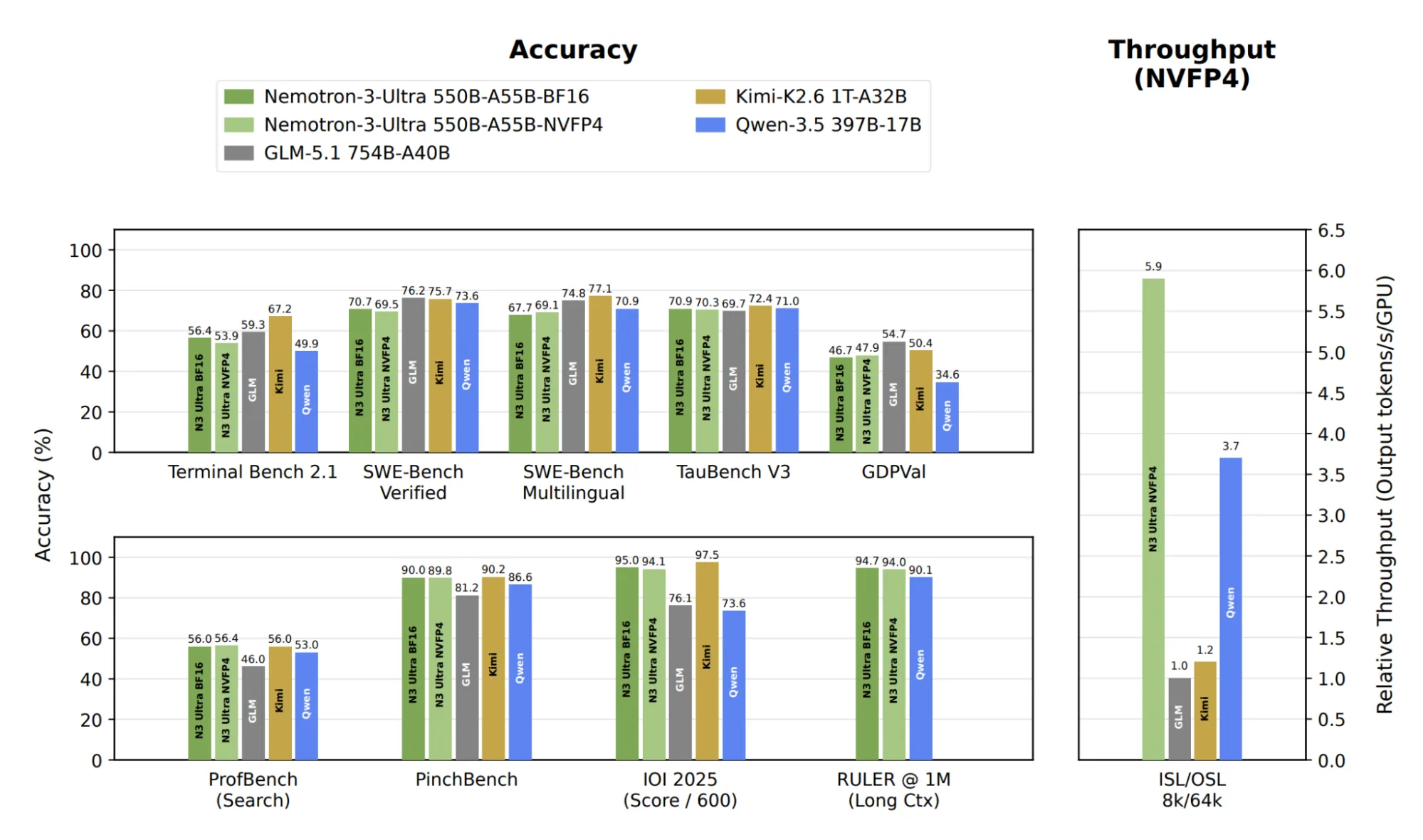
图 1. 与其他 NVFP4 模型相比,Nemotron 3 Ultra NVFP4 的性能
Nemotron 3 Ultra NVFP4 检查点
一个常见的误解是,NVFP4 检查点的每一层都存储在 NVFP4 中。如表 1 所示,情况并非如此:根据每层对架构的敏感度及其对模型准确性的影响,我们会将不同的层量化为不同的精度格式。经过 NVFP4 量化后,Nemotron 3 Ultra 模型从 BF16 中的 1121 GB 缩小到 352.3 GB,减少了 3.2 倍。回报是巨大的,将硬件占用空间减半。
| 层/ 运算符 | BF16 基准 | 量化检查点精度 |
| 嵌入、输出分类层、MTP 层 | BF16 | BF16 |
| MoE 路由专家 | BF16 | NVFP4 |
| MoE 共享专家 | BF16 | 每张量 FP8 |
| Mamba 混合线 | BF16 | 每张量 FP8 |
| 注意力线性 | BF16 | BF16 |
| 潜在 MoE | BF16 | BF16 |
| Mamba conv1d | BF16 | BF16 |
| KV 缓存 | BF16 | FP8 |
| Mamba SSM 缓存 | FP32 | 采用随机舍入算法的 FP16 |
表 1. BF16 基准与 Nemotron 3 Ultra 论文中每层/ 运算符的量化检查点精度的比较
Nemotron 3 Ultra NVFP4 的一项关键创新是,单个检查点可以在 NVIDIA Hopper 和 Blackwell 上运行。它通过将权重格式转换为与其运行的硬件相匹配来实现这一点。在缺少原生 FP4 Tensor Core 的 Hopper 上,服务框架会自动切换到 W4A16。在 Blackwell 上,它使用原生 W4A4。
虽然 W8A8 ( 8 位权重,8 位激活函数) 似乎是显而易见的 Hopper 选择,但其较大的内存占用空间太少,无法适应多令牌预测 (MTP) 。我们发现 MTP 只能与 W4A16 ( 4 位权重,16 位激活函数) 配合使用,因此 W4A16 可全面匹配或击败 MTP。阅读完整的 Nemotron 3 Ultra 技术报告 (第 4.6 节) 了解详情。
我们如何找到理想的 NVFP4 检查点
找到最佳 NVFP4 检查点需要进行一些迭代。在本节中,我们将深入探讨开发者如何获得 NVFP4 Checkpoint 的案例。
FP4 量化的挑战
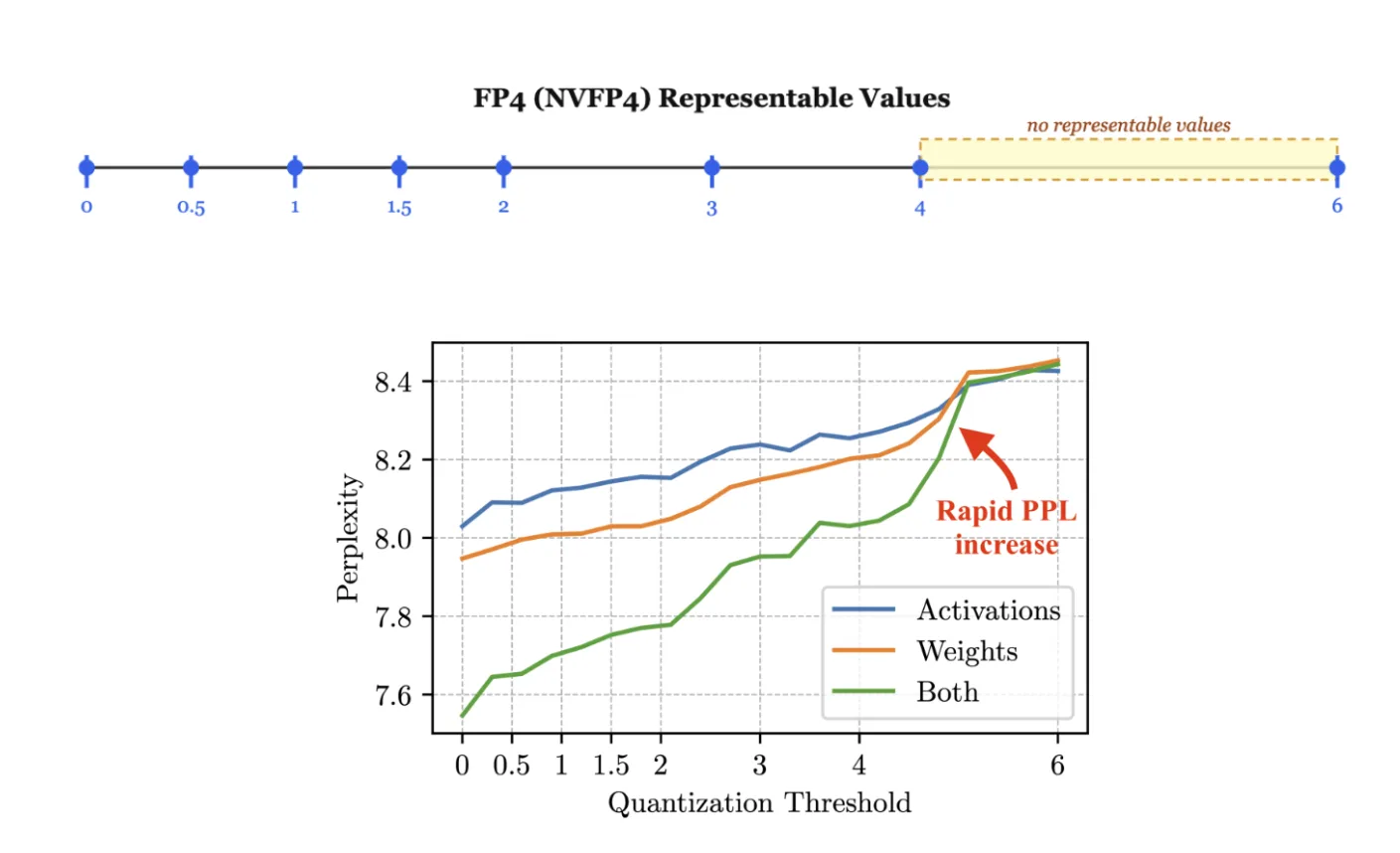
使用 FP4 量化时,只有 8 个正值[0、0.5、1、1.5、2、3、4 和 6]来表示整个权重块。我们需要确定如何映射原始值范围。这由刻度控制,本质上是决定表示粒度的乘数。选择较差的刻度意味着我们要么在较小的值上浪费精度,要么在较大的值上进行裁剪,这两者都会损害模型质量。那么,我们该如何选择最佳比例系数呢?有几种方法。
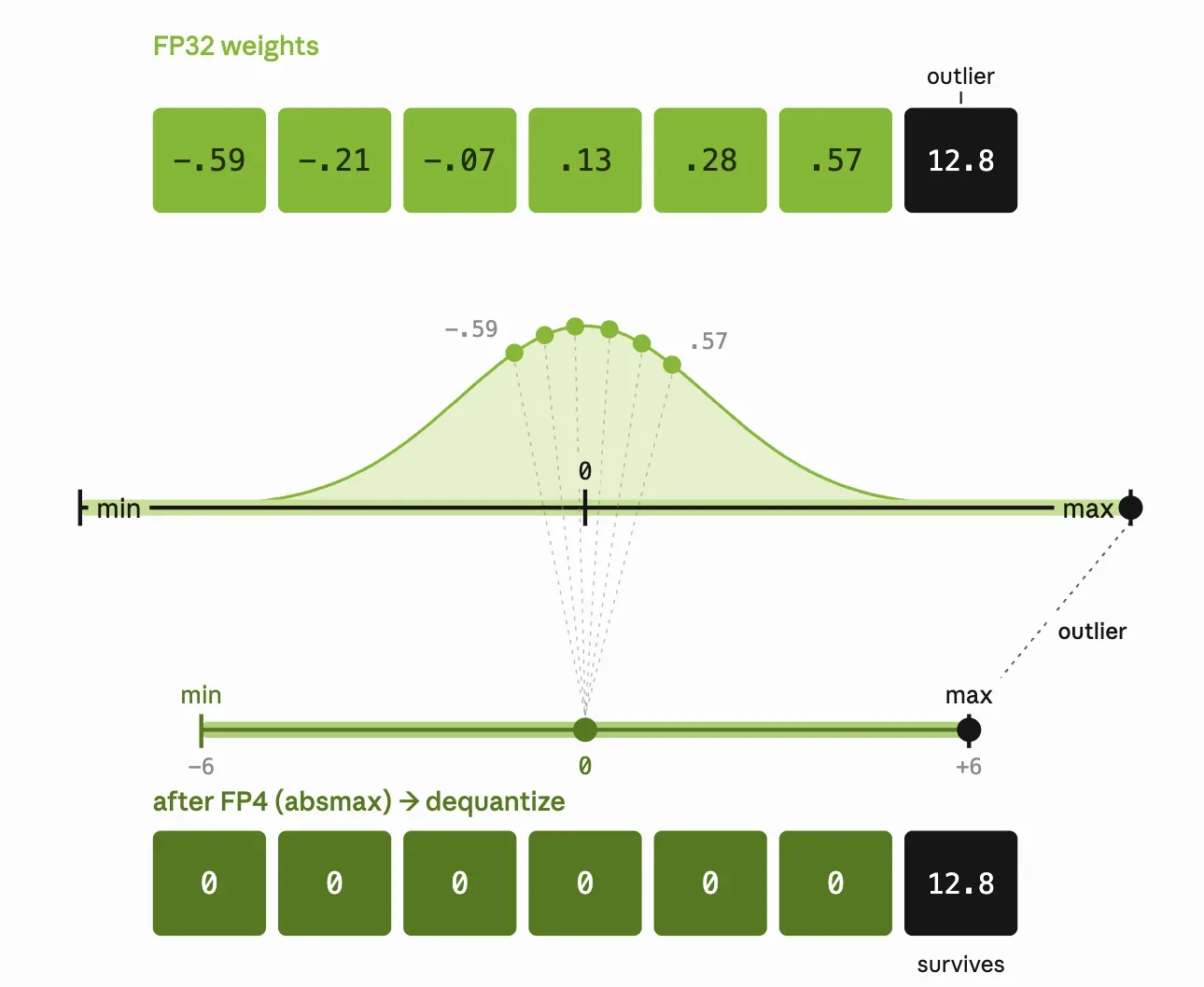
最大缩放
在这里,我们将区块图中的最大值的比例设置为最大可表示 FP4 值。但是,如果存在单个较大的权重离群值,则最大比例会将块中的所有其他值压缩到较小范围,最终会将这些值刷新为零。这种信息丢失可能会对准确性产生不利影响。最大缩放比例可保留块中的最大值,并可能产生将其他值刷新为零的副作用。
使用 NVIDIA Model Optimizer 试用:
# W4A4 — weights + activations to NVFP4 (default, max scaling)
model = mtq.quantize(model, mtq.NVFP4_DEFAULT_CFG, forward_loop=forward_loop)
最大缩放 (也称为 absmax,因为缩放完全由块的绝对最大值设置) 是最简单的选项,但对异常值的敏感性使其很少成为最佳选项。
这正是我们在上一个模型 NVIDIA Nemotron 3 Super:naive absmax NVFP4 PTQ 上遇到的差距,因此团队评估了一系列替代校准策略,从基于均方误差 (MSE) 的权重缩放到 GPTQ,一种使用二阶信息对权重进行编码的高效方法,这些策略不会让单个离群值决定规模。
| 算法 | 详细信息 | MMLU-Pro | GPQA | LiveCodeBench | AA-LCR |
| BF16 | — | 83.49 | 79.92 | 72.907 | 53.00 |
| 默认 NVFP4 PTQ (基准算法) | 使用最大值校正来计算每个张量的静态比例;根据块的最大值来动态计算每个块的比例。 | 82.99 | 79.29 | 70.18 | 55.50 |
| 每块权重可更大限度地减少 MSE | 扫描每个块的权重,以更大限度地减少每个块的 MSE。 | 83.31 | 79.92 | 71.37 | 56.75 |
| 按块权重扩展以更大限度地减少输出 MSE | 每块权重刻度独立扫描,以更大限度地减少 GEMM 输出 MSE。 | 83.05 | 78.98 | 71.00 | 57.06 |
| GPTQ | GPTQ ( Frantar 等人,2023 年) 用于权重量化。 | 83.11 | 80.05 | 69.79 | 57.87 |
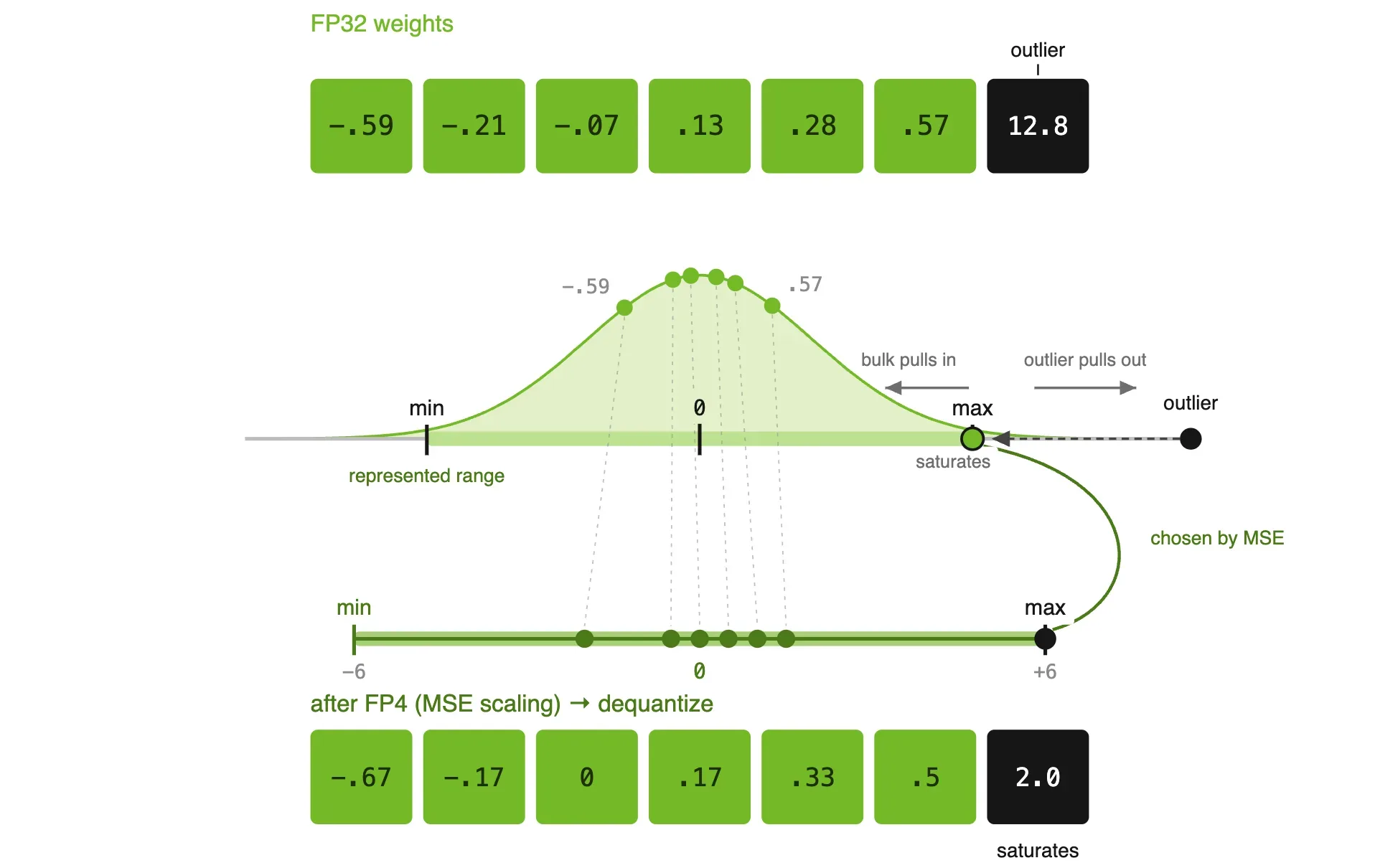
均方误差缩放
另一种方法是均方误差 (MSE) 缩放,该方法可搜索能够最大限度地减少整个区块平均重建误差的缩放比例。
但是,较低的 MSE 并不总是转化为更高的模型准确性。在我们的 Nemotron 3 Ultra 实验中,MSE 校正将每张量权重误差比 4 比 6 缩放减少了 27.1%,但在下游基准测试中并没有产生一致的改进。
使用 NVIDIA Model Optimizer 试用基于 MSE 的扩展:
model = mtq.quantize(model, mtq.NVFP4_W4A4_WEIGHT_MSE_FP8_SWEEP_CFG, forward_loop=forward_loop)
对于我们之前的模型 NVIDIA Nemotron 3 Super,最终的量化配方将基于 MSE 的权重块缩放与每张量 FP8 扫描和基于最大值的动态激活缩放相结合。将 MSE 权重与 FP8 激活扫描相结合,在我们尝试的所有内容中实现了最佳精度与大小的权衡,并成为我们针对 Super 的最佳 NVFP4 配置。
Max 和 MSE 缩放都会选择一个缩放比例,以更大限度地减少整体舍入误差,但不会注意误差来自网格上的位置。对于 Nemotron 3 Ultra,我们使用了一种缩放方法,根据网格中间隙的误差选择范围。
四比六的缩放
请记住,NVFP4 只能表示 8 个正值:0、0.5、1、1.5、2、3、4 和 6。请注意,在 4 之后,下一个值直接跳到 6。落在该范围内的任何权重都会被四舍五入到 4 或 6,有时单个值的误差超过 13%。
4 比 6 可解决此问题,因为每个权重块各自选择缩放到 M = 4 或 M = 6 的最大值,并选择可最大限度减小重建误差的选项。4 比 6 处理权重,并在激活时回退到默认的 NVFP4。
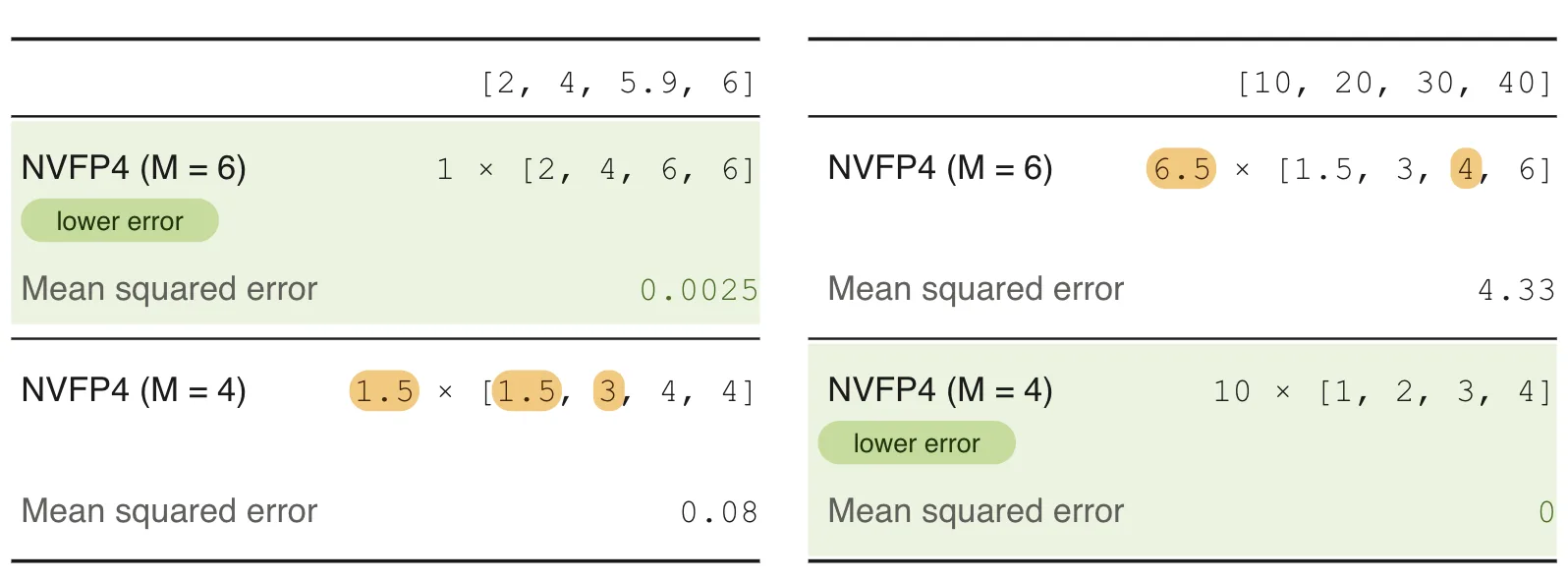
当 M+ 6 赢得方块时:[2、4、5.9、6]
在 M = 1 的刻度下,值 2、4 和 6 精确映射到 FP4 网格点,仅需 5.9 轮到 6 轮,且成本可忽略不计。扩展到 M+ 4 会将 2 推至 2.25,将 4 推至 4.5,从而引入误差。
当 M+ 4 赢得方块:[10、20、30、40]
缩放到 M+ 6 时,映射为 30 到 4.62,舍入为 4,误差为 13%。将 10、20、30 和 40 精确映射到 1、2、3 和 4 上,并在整个区块中实现零舍入误差。MSE:4.33 与 0.0。
在 Nemotron 3 Ultra 中,我们使用 4 比 6 来设置 FP4 路由专家权重表,将全局每张量权重表提升了 1.75 倍,并且每个微块选择 M = 4 或 M = 6 网格。在该模型的 48 个 MoE 专家层中的所有 49152 个投影权重中,与标准最大校正值相比,MSE 重建中值降低了 16.4%,并在平衡 5.03-BPE 设置中提供了最佳下游结果:相对于 BF16,其恢复中值为 98.5%,高于最大值 (96.8%) 和 MSE (98.4%) 。
使用 NVIDIA Model Optimizer 试用“四比六”:
model = mtq.quantize(model,
mtq.NVFP4_FOUR_OVER_SIX_CFG, forward_loop=forward_loop)
NVFP4_FOUR_OVER_SIX_CFG 将于 7 月在即将推出的 0.46 NVIDIA Model Optimizer 上发布。查看 Nemotron 3 Ultra PTQ 示例。
每个元素的比特率
每单元有效位 (BPE) 是指存储模型所有权重所需的平均位数。具有所有 BF16 权重的模型每元素使用 16 个有效位元,而半 FP8 半 BF16 模型仅使用 12 个有效位元。NVFP4 增加了每个块和每个张量的扩展用度,使每个元素的有效位数最低为 4.5。每张量刻度的 32 位在整个张量中摊销,并且假设在整个 BPE 计算中可以忽略不计。
其目标是寻找量化配置,在不牺牲准确性的情况下尽可能降低有效的 BPE。这一点比较棘手,因为层的鲁棒性不同。有些模型对量化很敏感,必须保持更高的精度,这会提高有效的 BPE。由于每层可以在不同的级别进行量化,也可以不量化,因此可能的组合数量呈指数级增长,因此进行详尽的搜索并不可行,因此需要更智能的策略。NVIDIA Model Optimizer AutoQuantize (mtq.auto_quantize) 可为您完成此操作。而不是固定配置,而是为其提供目标位预算 (例如 auto_quantize_bits=4.8) 和候选格式列表,例如 NVFP4_DEFAULT_CFG 和 FP8_DEFAULT_CFG。然后,它会对每层的灵敏度进行评分,并搜索符合预算且具有最佳准确性的每层格式分配,从而将最敏感的层保留为更高精度的格式,或者完全跳过这些层。
NVIDIA Model Optimizer AutoQuantize (
uv run launch.py --yaml examples/nvidia/NVIDIA-Nemotron-3-Ultra-550B-A55B-BF16/megatron_lm_ptq.yaml --yes
9) 可为您完成此操作。而不是固定配置,而是为其提供目标位预算 (例如 NV_skp_28) 和候选格式列表,例如 NV_skp_27 和 NV_skp_26。然后,它会对每层的灵敏度进行评分,并搜索符合预算且具有最佳准确性的每层格式分配,从而将最敏感的层保留为更高精度的格式,或者完全跳过这些层。
import modelopt.torch.quantization as mtq
model, search_state = mtq.auto_quantize(
model,
constraints={"auto_quantize_bits": 4.8},
quantization_formats=["NVFP4_DEFAULT_CFG", "FP8_DEFAULT_CFG"],
data_loader=calib_dataloader,
forward_step=forward_step,
loss_func=loss_func,
为了找到适合 Nemotron 3 Ultra 的每个元件比特率,我们在表 3 中比较了几个基准的准确性,涵盖了从 4.85 到 7.19 的每个元件有效比特率范围内的五个操作点。关键信号来自 AA-LCR,从 4.85 到 5.03,基准测试性能提高了 2.4 个点,然后基准测试性能再次下降到 5.03 以上。这使得 5.03 BPE 成为最佳点。
| 量化 (每单元比特) | ||||||
| 任务 | 指标 | 4.85 | 5.01% | 5.25 | 5.43 | 7.19 |
| 编码 | ||||||
| SciCode | pass = 1 ( avg-16) ,子任务 ACC | 43.82 | 43.88 | 43.45 | 43.27 | 43.44 |
| 科学推理 | ||||||
| GPQA 钻石级 | pass = 1 ( avg-32) ,sym。正确 | 84.66 | 84.33 | 84.75 | 84.12 | 84.52 |
| HLE | 第 1 步:判断正确 | 24.24 | 24.84 | 25.00 | 24.98 | 25.44 |
| CritPt | 通过 = 1 (平均值 – 8) ,精度 | 3.04 | 3.93 | 5.18 | 4.82 | 4.46 |
| 常规 | ||||||
| AA-Omniscience | 通过 = 1 (平均 20) ,判断正确 | 29.21 | 29.75 | 29.18 | 29.29 | 29.00 |
| 通过 = 1 (avg-20) ,无幻觉 | 54.13 | 51.59 | 51.84 | 51.70 | 52.81 | |
| IFBench | 平均通过 = 1 (avg-8) 。评分 | 79.34 | 79.26 | 79.83 | 79.53 | 79.83 |
| 长上下文 | ||||||
| AA-LCR | 通过 = 1 (avg-16) ,判断正确 | 62.25 | 64.69 | 64.19 | 64.94 | 65.00 |
如何使用模型优化器将 Nemotron 3 Ultra 量化为 NVFP4
与 Nemotron 3 Super 120B 不同,Nemotron 3 Ultra 是一个 550B 模型,因此它从量化过程的并行化中受益匪浅。因此,我们支持两种量化路径。
| 这两种路径均由 NVIDIA Model Optimizer 提供支持 | ||
| 指标 | Hugging Face Transformer | Megatron-LM |
| 计算 | 4* B300 | 16 B300;专家并行+ 数据并行 = 16 |
| 模型加载时间 | 40 分钟 | ~ 2 分钟 |
| 模型加载和校准时间 | 85 分钟 | 9 分钟 |
| 导出 | 42 分钟 | 33 分钟 |
| 总时间 | 120 分钟 | 45 分钟 |
将 Nemotron 3 Ultra 量化为 NVFP4,遵循 NVIDIA Megatron-LM 中的 NVIDIA ModelOpt 训练后量化 (PTQ) 流程。借助并行路径,预训练检查点首先转换为 Megatron-LM 格式,然后通过对 quantize.sh 的单次调用进行量化,并将 NVFP4 量化配置作为 recipe。在后端,Megatron-LM 利用专家并行性和数据并行性跨 GPU 对模型进行分片 ( 16* B300 上为 EP = DP = 16) ,因此校正前向传递会分布在所有设备上运行。这将负载和校准时间从~85 分钟缩短到~9 分钟。
校准运行 nemotron-post-training-dataset-v2 以适应每个块的规模,并且精度策略完全由配置驱动。通过向 quantize.sh 传递配置进行选择。可以是内置名称 (例如 NVFP4_DEFAULT_CFG、FP8_DEFAULT_CFG) ,也可以是 YAML recipe 路径,最终交给 mtq.quantize(model, config, forward_loop) 来安装量化器并运行校准。
试用 NVIDIA Model Optimizer 的 4 比 6 扩展:
HF_MODEL_CKPT=nvidia/NVIDIA-Nemotron-3-Ultra-550B-A55B-BF16
# Step 1 — Quantize to NVFP4
TP=4 \
MLM_MODEL_SAVE=/tmp/Nemotron-3-Ultra_quant \
./quantize.sh nvidia/NVIDIA-Nemotron-3-Ultra-550B-A55B-BF16 huggingface/models/nvidia/Nemotron-3-Ultra-550B-A55B/ptq/nvfp4-4o6
# Step 2 — Export the quantized checkpoint
PP=1 \
MLM_MODEL_CKPT=/tmp/Nemotron-3-Ultra_quant \
EXPORT_DIR=/tmp/Nemotron-3-Ultra_NVFP4_46_HF \
./export.sh nvidia/NVIDIA-Nemotron-3-Ultra-550B-A55B-BF16
NVFP4_FOUR_OVER_SIX_CFG 支持“四比六”,现已登陆 NVIDIA Model Optimizer 0.46。GitHub 上提供了适用于 4 比 6 的 Nemotron 3 Ultra recipe。4 比 6 处理权重,并在激活时回退至默认的 NVFP4。
自定义量化配置
NVIDIA Model Optimizer 专为使用不同的量化配置进行定制而构建。内置的 NVFP4 配置包括广泛量化的 NVFP4_DEFAULT_CFG,以及更具选择性的预设,例如 NVFP4_MLP_ONLY_CFG、NVFP4_EXPERTS_ONLY_CFG 和 NVFP4_OMLP_ONLY_CFG,这些预设将 FP4 限制在 MLP 和专家层,同时以更高的精度保持敏感的注意力投射。
配置是与模块名称模式匹配的规则的有序列表,mtq.quantize() 会应用这些规则。权重量化由针对 *weight_quantizer 模式的规则管理,您可以在其中设置格式 (对于 NVFP4,E2M1 元素具有 16 宽块和 E4M3 块比例) ,而激活量化则由 *input_quantizer 模式上的单独规则管理。
由于两者是独立的,因此您可以仅量化权重,也可以同时量化权重和激活函数,您可以通过附加使其禁用的规则来为特定模块划分例外。对于内置预设之外的任何内容,您可以编写完整的 YAML recipe,并使用 --recipe 加载该 recipe,然后 NV_skp_6 会完全定义量化配置。
以下 Nemotron-3 Ultra recipe 将 4 比 6 的 NVFP4 应用于路由专家权重,将共享的专家和 Mamba 投影保留在 FP8 中,使用 FP8 KV 缓存,并将其他所有内容保留在 BF16 中。完整 recipe 随附 NVIDIA Model Optimizer 的 recipe 库: nvfp4-4o6.yaml
# Nemotron 3 Ultra NVFP4 mixed-precision recipe with Four-Over-Six (4/6)
# Example recipe for HuggingFace models, for Megatron-compatible recipe see the full recipe link
quantize:
algorithm:
method: mse
fp8_scale_sweep: false
start_multiplier: 1.0 # M=6 (keep amax)
stop_multiplier: 1.5 # M=4 (amax x 6/4)
step_size: 0.5 # candidates [1.0, 1.5]
quant_cfg:
# Disable everything by default; later rules re-enable specific modules.
- quantizer_name: '*'
enable: false
# MoE routed experts -> NVFP4 W4A4, block 16, e4m3 block scale.
# 4/6 adaptive block scaling on weights only; not actvivations
# HF names: backbone.layers.*.mixer.experts.*.{up,down}_proj
- quantizer_name: '*mixer.experts.*weight_quantizer'
enable: true
cfg:
block_sizes: {-1: 16, type: static, scale_bits: e4m3, four_over_six: true}
num_bits: e2m1
- quantizer_name: '*mixer.experts.*input_quantizer'
enable: true
cfg:
block_sizes: {-1: 16, type: dynamic, scale_bits: e4m3}
num_bits: e2m1
# Shared experts + Mamba in/out_proj -> FP8 per-tensor (weights+activations).
- quantizer_name: '*mixer.shared_experts*'
enable: true
cfg: {num_bits: e4m3, axis: null}
- quantizer_name: '*mixer.in_proj*'
enable: true
cfg: {num_bits: e4m3, axis: null}
- quantizer_name: '*mixer.out_proj*'
enable: true
cfg: {num_bits: e4m3, axis: null}
# KV cache -> FP8.
- quantizer_name: '*[kv]_bmm_quantizer'
enable: true
cfg: {num_bits: e4m3}
当我们在 Nemotron 3 Ultra 上演示时,相同的工作流可用于任何 Hugging Face 模型检查点。只需将 Model Optimizer 指向 Hub 中的模型卡或本地路径,选择配置 (内置预设或您自己的 recipe) ,然后运行相同的量化和导出步骤。
import modelopt.torch.quantization as mtq
from modelopt.torch.export import export_hf_checkpoint
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("<your-hf-model-card>")
# Calibrate + quantize with the config of your choice
model = mtq.quantize(model, mtq.NVFP4_DEFAULT_CFG, forward_loop)
# Export a unified HF checkpoint for TRT-LLM / vLLM / SGLang
export_hf_checkpoint(model, export_dir="<export_path>")
试用一键启动程序
为简化部署,Model Optimizer 启动器可自动执行整个 Ultra PTQ 和导出工作流程。在启动器 README 中完成设置步骤后,只需本地机器发出一条命令,即可通过 Nemotron 3 Ultra YAML recipe 启动工作流:
启动后,该工作流将自动处理剩余的量化和导出步骤,前提是能够访问具有足够 GPU 资源的 Slurm 集群。此示例在四个节点上进行了验证,每个节点均配备四个 NVIDIA Blackwell GPU。
对于较小规模的部署,PTQ 示例也适用于 Nemotron-3 Super:
uv run launch.py --yaml examples/nvidia/NVIDIA-Nemotron-3-Super-120B-A12B-BF16
开始使用
您可以使用开源 NVIDIA Model Optimizer GitHub 资源库中提供的完整 recipe 重现此过程。Model Optimizer 是一个社区驱动的项目,我们鼓励大家做出贡献。可以提交问题以报告错误或请求功能,可以审查项目路线图以了解即将开展的工作,还可以提交拉取请求以做出改进。有关贡献指南和入门信息,请参阅 CONTRIBUTING.md。
使用以下资源了解详情:
- NVIDIA Model Optimizer GitHub
- NVIDIA Model Optimizer LLM PTQ 文档
- 采用 Megatron-LM 的 NVIDIA Model Optimizer
- Nemotron 3 Ultra 技术报告
- Nemotron 3 Ultra NVFP4 Checkpoint
致谢
如果没有 NVIDIA Model Optimizer 团队和 Nemotron 团队之间的密切合作,这项工作是不可能完成的。我们感谢两个团队的工程师,他们为量化流程、评估基础设施和模型训练做出了贡献。特别感谢 Megatron-LM 团队实现大规模分布式量化,并感谢 Nemotron 团队提供用于验证 FP4 方法的基准套件。我们还要感谢更广泛的 NVIDIA 研究和应用深度学习团队在整个项目期间给予的持续支持和反馈。
我们特别感谢 Asma Kuriparambil Thekkumpate、Jenny Chen 和 Jinhang Choi 在 Nemotron 3 Ultra 上领导实施 NVFP4 量化。