
Transformer 架构是许多现代大型语言和生成式 AI 模型的支柱。随着这些模型规模的扩大,运行训练会消耗更多的 GPU 小时和更多的工程迭代时间。因此,加速 Transformer 不仅仅是一种性能优化,它还直接影响团队的实验速度以及训练模型的能力。NVIDIA Hopper 和 NVIDIA Blackwell GPU 通过引入低精度运算符支持 (包括 FP8 和 NVFP4) 来帮助解决这一问题。
Transformer 的大部分训练时间都花在 GEMM 上,而低精度格式主要通过使矩阵乘法更快、更便宜来加快训练速度。但是,Transformer 配置无法告诉您模型中实际运行的是哪些 GEMM。如果您想了解训练时间的推移,您需要将 Transformer 配置和批量大小转换为模型执行的确切 M×K×N 矩阵形状,然后跨精度对这些形状进行基准测试。这将帮助您在投入更昂贵的训练之前,确定架构的最佳精度。
NVIDIA Transformer 引擎 (TE) 可以处理量化和内核调度,解锁低精度格式。本文将介绍如何从高级模型设置转向具体的 GEMM 工作负载,使用微基准测试对其进行分析,并估计较低精度会在哪些方面转化为加速,从而帮助您加速基于 Transformer 的模型。该用例采用了专注于 RNA 的生物学语言模型 CodonFM。
模型配置和训练输入
假设您使用的是 5B 参数模型,例如 CodonFM 5B。它将具有如下配置:
hidden_size: 4096
intermediate_size: 16384
num_attention_heads: 32
num_hidden_layers: 24
您的训练配置如下:
micro_batch_size: 31
sequence_length: 512
然后,基准测试工具可以直接获取这些超参数,然后使用单个命令导出 GEMM 形状,跨精度对其进行基准测试,并计算完整的加速分析:
python benchmark.py \
--hidden_size 4096 \
--intermediate_size 16384 \
--num_attention_heads 32 \
--num_hidden_layers 24 \
--micro_batch_size 31 \
--sequence_length 512 \
-o ./images/b300_model_config_speedup.png
注意:要禁用 Blackwell 专用标志,请添加 --no-fp8 --no-fp4。--no-fp8 --no-fp4 提供 BF16 以及在 Hopper 上运行的三个 FP8 recipe。
--no-fp8禁用 MXFP8--no-fp4禁用 NVFP4
使用自动投射模式与预量化模式
默认情况下,该工具在自动投射模式下运行,这正是 TE 在训练期间所做的:在每个 GEMM 之前,输入会动态量化为目标精度,因此测量时间包括量化成本和 GEMM 内核本身。这将在训练步骤中为您提供每个 GEMM 的逼真图像。
该工具计算 M = 31 × 512 = 15,872 个 token,推导出所有 12 个 GEMM 形状,跨启用的精度对每个形状进行基准测试,并打印完整结果。Fprop、Dgrad 和 Wgrad 形状均单独进行了基准测试,以捕获不同矩阵高宽比对内核选择的影响。
默认情况下,该工具在自动投射模式下运行,这正是 TE 在训练期间所做的:在每个 GEMM 之前,输入会动态量化为目标精度,因此测量时间包括量化成本和 GEMM 内核本身。这将在训练步骤中为您提供每个 GEMM 的逼真图像。
该工具计算 M = 32 × 1024 = 32768 个 token,推导出所有 12 个 GEMM 形状,跨启用的精度对每个形状进行基准测试,并打印完整结果。Fprop、Dgrad 和 Wgrad 形状均单独进行了基准测试,以捕获不同矩阵高宽比对内核选择的影响。
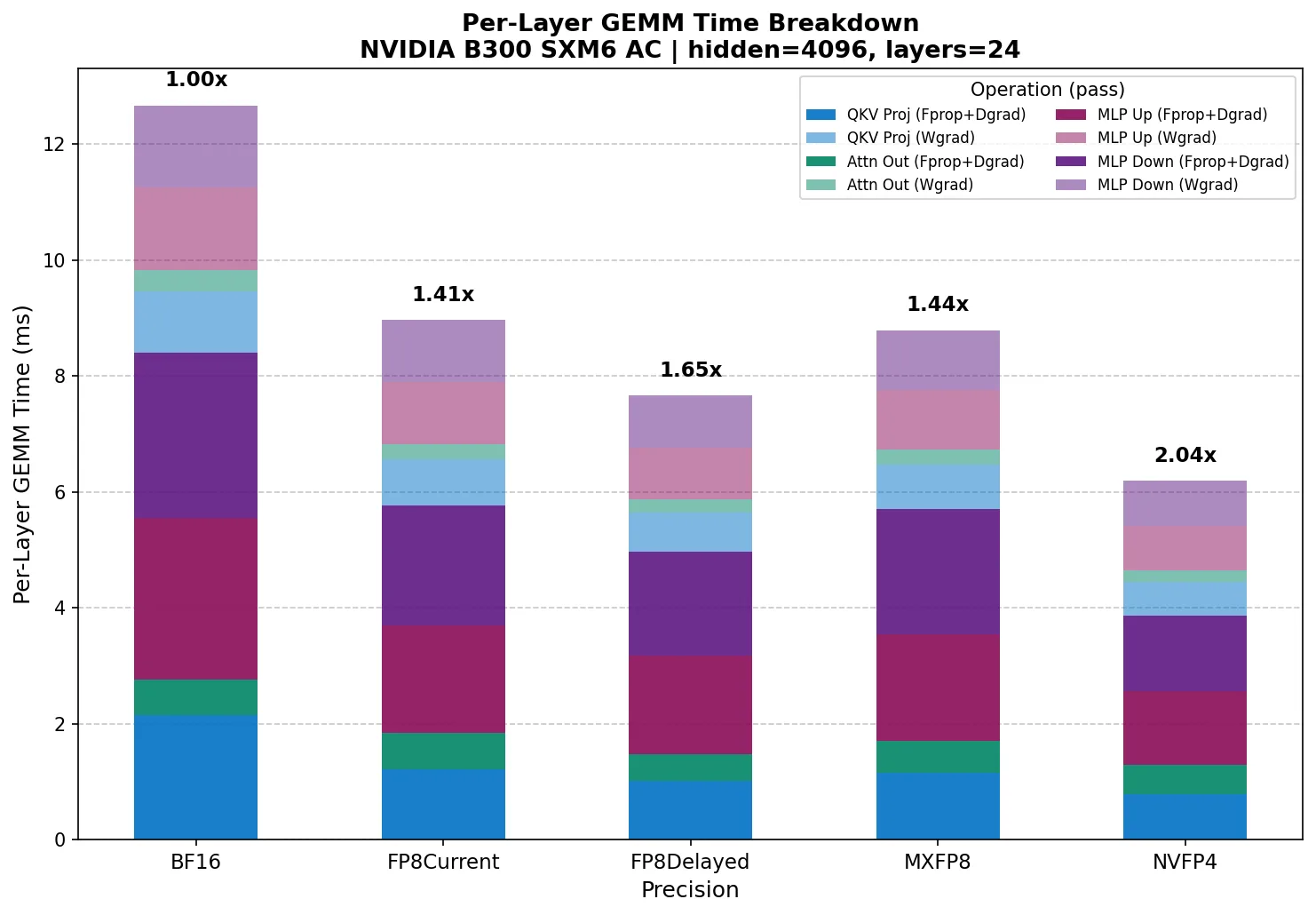
要分离原始 GEMM 内核性能,请添加 --pre-quantize。这会在计时循环之前对所有输入进行一次预量化,因此测量时间仅反映 GEMM 核函数的执行情况,在计时区域内没有动态量化,没有块扩展计算,也没有格式转换。
请注意,FP8 DelayedScaling 始终在自动投射模式下运行,即使在使用 --pre-quantize 时也是如此,因为它依赖于需要动态量化的 Amax 历史记录。因此,它的时间无法直接与预量化模式下的其他精度进行比较。
python benchmark.py \
--hidden_size 4096 \
--intermediate_size 16384 \
--num_attention_heads 32 \
--num_hidden_layers 24 \
--micro_batch_size 31 \
--sequence_length 512 \
--pre-quantize \
-o ./images/b300_model_config_speedup_prequant.png
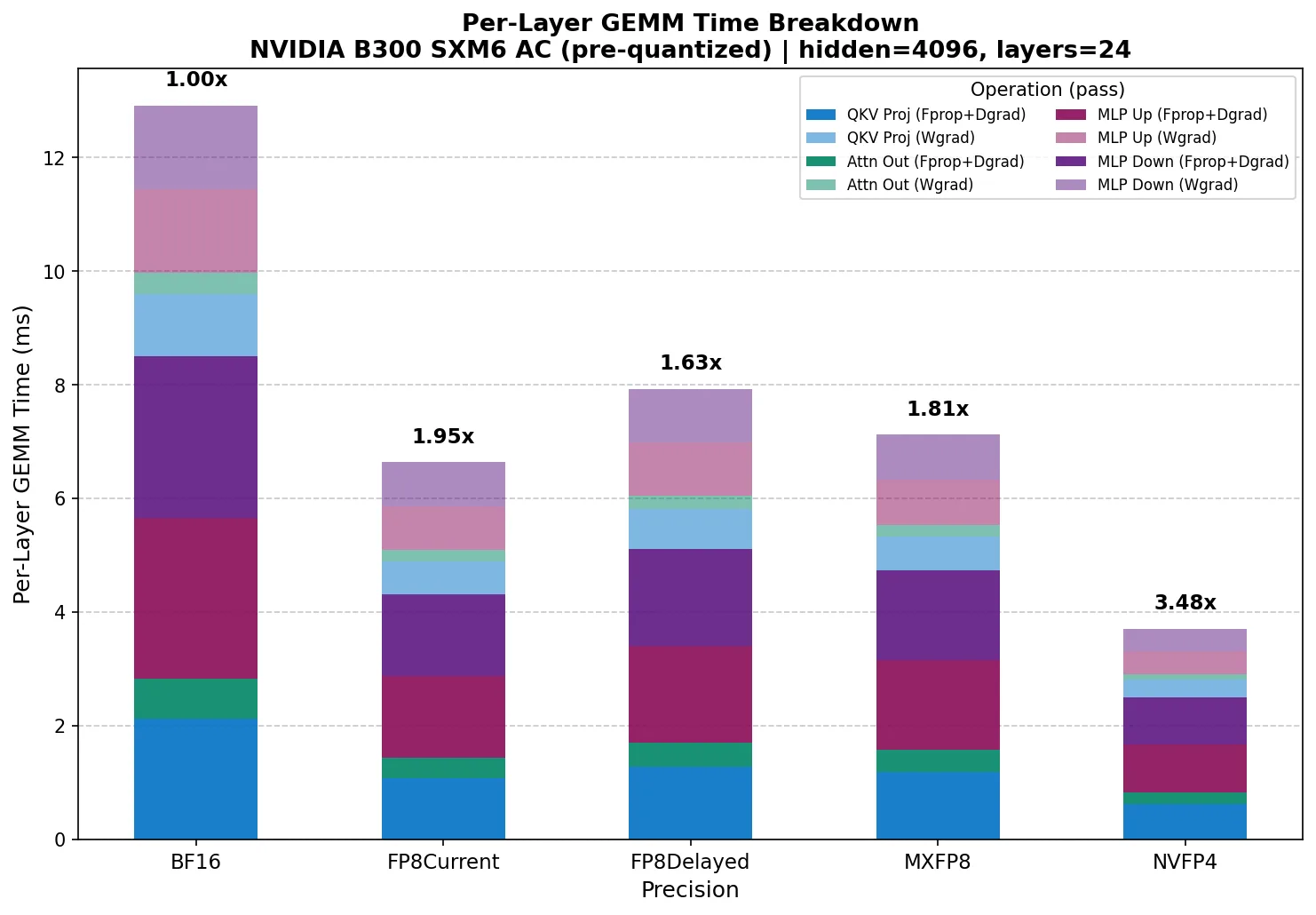
通过比较自动投射和预量化加速,您可以了解量化开销的确切程度:NVFP4 与 BF16 的开销介于 1.98 倍 (自动投射) 和 3.48 倍 (仅内核) 之间。这两个数字之间的差距是每个训练步骤中发生的动态量化、阿达玛变换和块缩放所产生的开销。
使用自动投射结果预测实际的训练加速。这正是 TE 在训练过程中所做的。使用预量化结果来了解量化开销是否是瓶颈,或者独立于量化实现来比较跨精度的原始 Tensor Core 吞吐量。
解释真实模型的结果
本节介绍如何为真实模型解释这些结果。使用相同的 CodonFM 5B 配置,我们在 NVIDIA B300 上运行了完整的模型配置基准测试。Fprop 结果中每个形状的 NVFP4 与 MXFP8 的加速效果对比如下:
QKV proj: 0.579 / 0.392 = 1.48x
Attn out: 0.269 / 0.256 = 1.05x (barely faster — overhead nearly matches GEMM gain)
MLP up: 0.924 / 0.635 = 1.46x
MLP down: 1.076 / 0.649 = 1.66x
请注意以下几点:
- 较低精度对注意力输出 GEMM 的益处微乎其微。与 MXFP8 基准相比,速度仅提升了 1.05 倍。这是图层中最小的权重矩阵 ( 4096 × 4096) ,几乎没有足够大的精度来克服开销。相比之下,在相同的硬件上,更大的 MLP 向下 GEMM 可提供 1.66 倍的 NVFP4,相较于 MXFP8。在 GEMM 下方,MLP 足够大,足以摊销量化开销,而注意力输出无法做到这一点。
- 大型 GEMM 展现出真实但亚理论性的收益。在大型 GEMM 上,FP4 Tensor Core 的性能是 MXFP8 的 1.46 倍至 1.66 倍。这远远低于硬件规格中理论上的 2 倍到 3 倍。添加注意力输出 GEMM 后,混合后的 Fprop 加速降至 1.47 倍。添加 Wgrad 时间、非 GEMM 开销和 NVFP4 特定量化成本后,NVFP4 和 MXFP8 在训练中的端到端差距与这些内核级数字一致。
- FP8 DelayedScaling 在 NVIDIA Blackwell 上具有惊人的竞争力。在自动投射模式下,其性能为 7.80 毫秒/ 层,优于 FP8 电流缩放 (9.15 毫秒) 和 MXFP8 (8.98 毫秒) 。在预量化模式下,FP8 CurrentScaling 向前推进 ( 6.81 毫秒与 8.12 毫秒) ,这表明 DelayedScaling Amax-history 方法的量化开销较低,但原始内核吞吐量相似。这是一个很好的示例,比较了自动投射和预量化后的结果,根据您是否使用量化税进行测量,得出了不同的获胜结果。
- 预量化结果揭示了真正的核函数势。使用
--pre-quantize运行时完全消除了量化开销,NVFP4 与 BF16 的性能对比从 1.98 倍 (自动投射) 跃升至 3.48 倍 (仅内核) 。这表明 FP4 Tensor Core 真正实现了加速。正是自动投射模式下的量化开销缩小了差距。 - Fprop 与 Dgrad 的比较显示,对于量化格式,2 倍的近似值是不精确的。虽然 BF16 Dgrad 与 Fprop 的差距在 2% 以内,但量化格式显示 Dgrad 求和的速度要慢 5 – 13%。QKV Proj Dgrad 尤其不对称 (在 FP8/ FP4 下速度比 Fprop 慢 33 – 51%) ,因为交换 K (4096) 和 N (12288) 会显著改变矩阵长宽比和内核选择。这正是工具分别对 Fprop 和 Dgrad 进行基准测试的原因,而不是将 Fprop 时间计算两次。
获得仅 GEMM 的预估加速后,请将其与观察到的端到端训练加速进行比较:
- GEMM 加速 ≈ 训练加速: GEMM 主导步骤,一切均按预期运行
- GEMM 加速 >> 训练加速: GEMM 之外的开销正在消耗收益。特别是对于 NVFP4,此开销包括 Wgrad 输入上的随机 Hadamard 变换、梯度的随机舍入、权重的 2D 块缩放,以及用于每张量最大值计算的额外内存通道。这些都是 MXFP8 不需要的额外运算,即使原始 FP4 GEMM 的速度更快,它们也可以显著缩小差距
- 即使在微基准测试中,GEMM 的加速也小于 1.0。在处理这些形状时,FP4 内核的速度实际上并不快,或者它们正在悄无声息地回落到 FP8
最后一种情况特别值得检查。设置 NVTE_LOG_LEVEL=1 或使用 NVIDIA Nsight Systems 进行检查,以确认 TE 实际上正在分发 FP4 内核。对于尚不支持 FP4 的层或运算,TE 可以静默地回退到 FP8 或 BF16,这解释了相同的性能,没有其他症状。您还可以比较 MXFP8 和 NVFP4 运行时的 GPU 显存占用情况。如果显存几乎相同,则表示 FP4 权重实际上并未存储。
开始对模型进行基准测试,以进行低精度训练
低精度训练加速高度依赖于模型运行的实际 GEMM 形状,并且在低精度下运行不会自动转换为端到端训练收益,尤其是在量化开销、内核选择和非 GEMM 运算中。通过将 Transformer 配置转换为具体的 M* K* N 工作负载,您可以在投入完整训练运行之前,在对模型至关重要的形状上对 BF16、MXFP8 和 NVFP4 进行基准测试。
对您的 GEMM 进行基准测试,看看哪个精度适合您。首先,请查看基准测试脚本。如需了解完整文档以及这些形状的衍生方式,请参阅Transformer Engine 文档中的GEMM 分析教程。
使用此基准测试来:
- 自动投射结果,设定实际的训练加速预期
- 对结果进行预量化,以确定您是遇到了内核瓶颈还是量化瓶颈
- 在投入训练之前,通过该工具运行候选模型配置,因为该工具是一种有用的架构协同设计工具