
几十年来,计算生物学一直在简化主义妥协下运作。为了将复杂的生物系统整合到单个 GPU 的有限内存中,研究人员不得不将它们解构为单个蛋白质或小结构域等孤立的片段。这造成了上下文差异,即由于 GPU 硬件内存限制,较大的蛋白质或配合物无法零样本折叠。
现在,上下文并行 (CP) 框架从 NVIDIA BioNeMo 团队正在打破结构生物学的内存障碍,实现系统的整体建模。
本文将介绍如何在偏离标准 Transformer 的生物分子架构中实现 CP。如果您是结构生物学家、计算化学家或机器学习工程师,想要在不牺牲全球环境的情况下对大规模生物分子复合体进行建模,请继续阅读。
要使用本文中概述的解决方案,您需要:
- 熟悉几何深度学习基础模型,如 AlphaFold3 或 Boltz-2。
- 了解 PyTorch 分布式 (DTensor) 运算和自定义自动调整函数。
- 访问 NVIDIA H100 或 B200 GPU 集群,因为该框架严重依赖其互连带宽和 Transformer 引擎加速来执行百亿亿次级 (Exascale) 任务。
如需了解更多详情,请参阅 Fold-CP:用于生物分子建模的上下文并行框架。
跨多个 GPU 对单个大分子系统进行分片
在没有 CP 的情况下,折叠大型配合物 (通常超过 1000 – 3000 个残基) 需要采用简化法,将系统在物理或计算上解构为可管理的块。这些方法使研究人员能够保持在单个 GPU 的严格 VRAM 限制范围内,但往往会牺牲全局结构准确性。
对于块状蛋白质,最常见的变通方法是将序列分成较小的重叠段。片段必须显著重叠,以确保局部二级结构在分割点之间保持一致。这种方法会破坏远程信息。例如,研究人员无法对整个复合体中的异构或信号转导进行建模。
另一种常见的优化方法是分块,它不同于物理序列的碎片化,而是在模型架构层面进行,旨在推理过程中节省显存。例如,玻尔兹模型采用主动分块,将大型矩阵拆分为较小的图块进行处理。而像 FastFold 等其他技术则使用自动分块,可动态调整分块策略,从而降低峰值内存占用。更多细节请参见:FastFold:将 AlphaFold 的训练时间从 11 天缩短至 67 小时。
所有这些技术本身都缺乏全局上下文,尤其是在训练期间。NVIDIA BioNeMo CP 框架通过跨多个 GPU 对单个大分子系统进行分片,克服了这些限制。传统的数据并行机制为每个 GPU 分配不同的折叠蛋白质,与之不同的是,CP 将单个大规模样本分割到 GPU 上。
BioNeMo 上下文并行实现
NVIDIA BioNeMo CP 实现基于 Torch 分布式 API 构建,用于 GPU 之间的通信。该架构自下而上构建,从低级通信协议开始,一直到高级模型特定工作流。本文使用玻尔兹作为示例代码库。
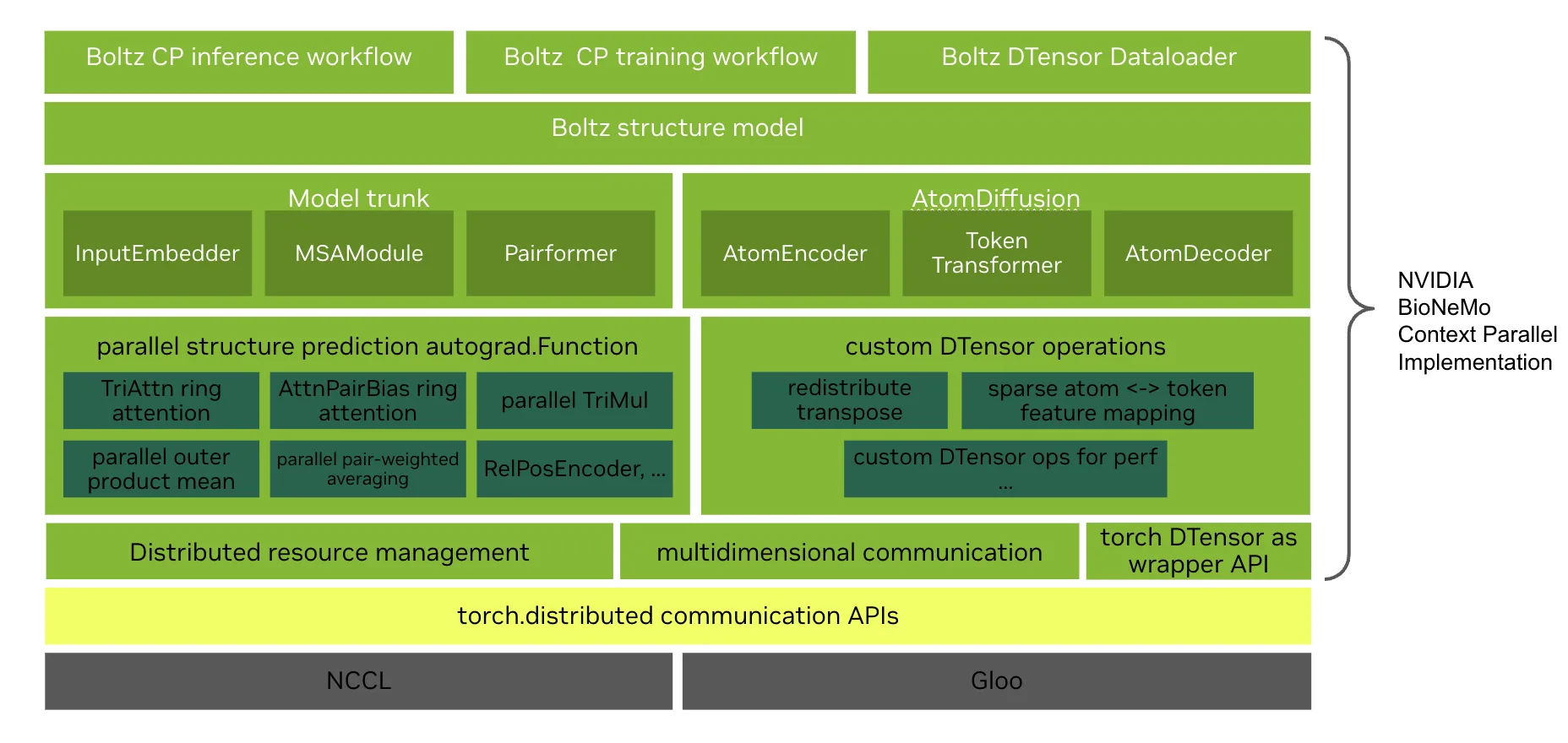
为了实现线性容量扩展 (系统的能力随 GPU 数量呈线性增长) ,该框架实施了多维分片策略。这可确保没有任何单一设备能够满足生物分子的完整全局状态,而这会破坏 CP 的内存目标。为不同的模块构建了自定义的乐高类组件,以提高实现效率,并更容易移植到其他架构。
对表示的 2D 平铺
该框架将全局 (N x N) 矩阵划分为块网格。对于代表 1 亿次交互的 1 万个残差复合体,每个 GPU 仅管理特定的子块。这将每个设备的内存占用从 O (N2) 定位到 O (N2/ P) 。
计算和通信重叠
该框架实现分布式基元,通过异步点对点传输来编排本地计算。GPU 在计算本地更新时,会同时向行和列环中的相邻节点发送和接收数据。随着生物问题规模的扩大,计算与通信的比率也会提高,从而提高系统在更大范围内的效率。
高效原子序列局部注意力
AlphaFold3 序列局部注意力将原子注意力限制在大小为 32 x 128 的局部注意力窗口上,而此类窗口的堆栈会在其中通过批量注意力计算。前面提到的原子特征平铺需要重新分区,以获得此基于窗口批处理的原子注意力的分布式版本。NVIDIA 团队实施了基于光环交换的分布式基元来划分原子特征,因此后续的窗口批量注意力不需要 GPU 之间的通信。
用于三角形乘法的上下文并行实现
以下示例展示了如何创建 CP 感知层,以分布式方式计算三角形乘法。
# … torchrun or srun SPMD launcher sets up the environment # Initialize the grid of devices DistributedManager.initialize(device_type="cuda") manager = DistributedManager() # Create a square 2D device mesh for symmetrical communication size_ring = math.isqrt(manager.world_size) DistributedManager.create_grid_group({"dp": 1, "cp": (size_ring, size_ring)}) # Instantiate the specialized peer-to-peer communication handle ring_comm = Ring2DComm(manager.group["cp"], manager.subgroups["cp"][0], manager.layout_subgroups["cp"]) # Data processing or previous layer output x_dtensor, mask_dtensor = … # Instantiate standard layer and load the checkpoint on CPU before distributing across the device grid layer_serial = TriangleMultiplicationOutgoing(size_input_embed) layer_serial.load_state_dict(layer_state_dict) # Map standard layer to GPU device layer_serial = layer_serial.to(manager.device) # Wrap with BioNeMo CP to handle DTensors layer = DistributedTriangleMultiplication(Outgoing, layer_serial, manager.device_mesh_subgroups, ring_comm) # The resulting activation tensors are now sharded across the device grid result_dtensor = layer(x_dtensor, mask_dtensor) DistributedManager.cleanup() |
此代码通过使用 DistributedManager 设置方形 2D 设备网格来初始化 CP 环境,这是一项特定的架构要求,可确保行和列的通信模式保持对称和高效。然后对 Ring2DComm 句柄进行实例化,以管理专用的点对点通信,从而实现数据块在连续循环中的循环。这种环形方法至关重要,因为它实现了本地计算与数据传输的重叠,确保 𝑂(𝑁2) 对表示张量永远不会超过单个 GPU 的显存容量。
脚本的后半部分处理从标准串行模型到基于 DTensor 的模型的过渡。TriangleMultiplicationOutgoing 等标准层先加载到 CPU 上,然后由 DistributedTriangleMultiplication 封装,实现了适用于 NVIDIA BioNeMo CP 框架的分布式算法版本。通过将输入处理为分布式张量 (DTensors) ,该模型可确保在整个网格中对大型激活张量进行分片。
为结构生物学解锁词元扩展
图 2 显示,随着 词元 容量扩展定律现已适用于生物分子架构。利用 256 个 GPU,可支持高达 20,000 个词元的玻尔兹预测,并可在 NVIDIA H100 GPU 上进一步扩展最大词元长度,同时在 NVIDIA B300 GPU 上实现更快的扩展。
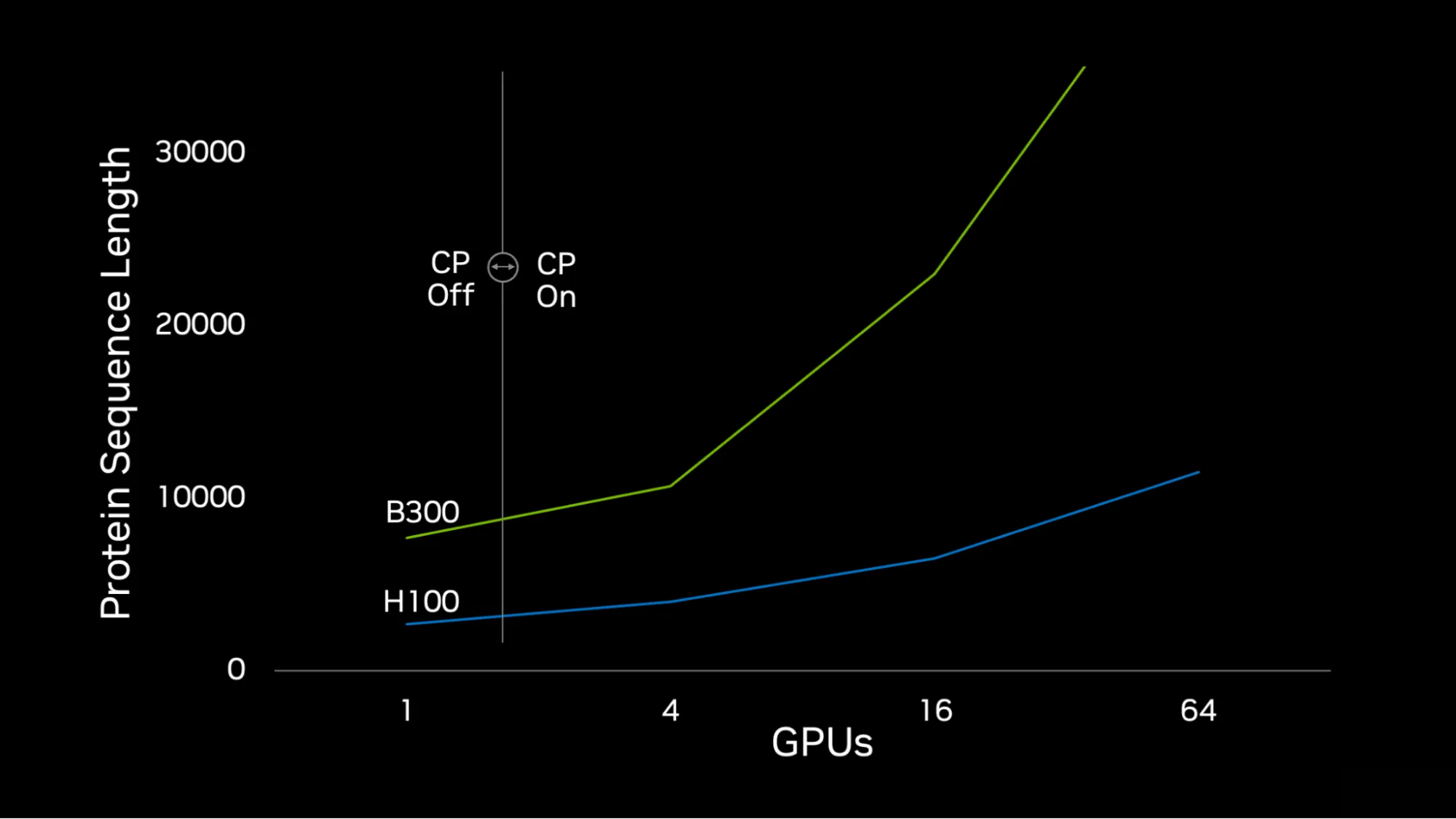
该团队无需进行任何额外训练,也无需对更长的作物长度进行微调,便将 TTC7A/ PI4KA/ FAM126A/ EFR3A (700 – 823) 系统折叠起来,该系统在四个链中包含 3605 个残基,远远超过了 768 个残基的玻尔兹 – 2 训练作物大小和单个 GPU 的内存容量。使用 CP 后,在 4 块 NVIDIA H100 GPU 上可在 5 分钟内 (每个样本约 54 秒) 生成 5 个结构样本,同时在模型上下文窗口内保持所有远程亚基间接触。
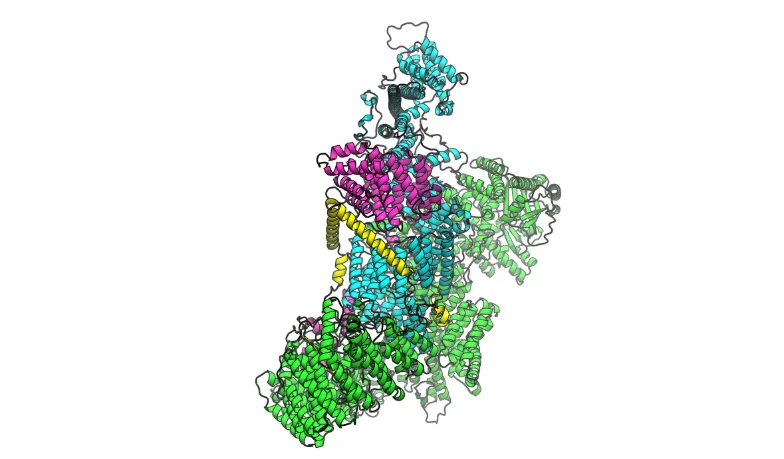
与此同时,该团队还与 Rezo Therapeutics、Proxima 和 Earendil Labs 等为 CP 框架开发做出重大贡献的合作伙伴一起,致力于推动这一新一代前沿技术的发展。
Rezo Therapeutics 集成了 CP 框架,可预测多达 6500 个残基的大规模蛋白质 – 蛋白质相互作用 (PPI) ,从而对绝大多数已知蛋白质配合物进行结构预测,并快速发现新的配合物。事实上,与仅使用公共领域中的高置信度 PPI 进行的预测相比,CP 分辨率、高质量的新型蛋白质配合物的富集度提高了 3 倍以上。
Proxima 在其全原子生成基础模型 Neo 中嵌入了 CP,能够对多达 4000 词元的组件进行推理,从而从结构上解析其独特质谱仪平台映射的蛋白质组中与治疗相关的相互作用,从而帮助其开发分子胶水和其他基于邻近的疗法的药物研发工作。
Earendil Labs 将该框架集成到其专有的生物分子基础模型中,成功扩展了输入序列长度,以对复杂的多蛋白质系统进行建模,而这些系统以前无法进行计算。Earendil Labs 表明,即使序列复杂性增加,CP 也有可能保持高保真的结构预测,同时缩短新一代生物疗法的研发时间。
开始使用上下文并行处理技术进行生物分子建模
虽然最初的概念验证表明,CP 打破了之前的内存障碍,能够对无限大小的结构进行建模,但仅凭物理能力并不能保证生物准确性。目前的模型往往难以大规模地执行高保真折叠,因为它们是在小片段上训练的。对更大的作物进行微调对于准确捕获远程交互的新兴逻辑至关重要。
作为这项工作的一部分,我们正通过向 AlphaFold 蛋白质结构数据库 贡献数据,解决该领域的一个主要瓶颈——数据稀缺问题。借助 NVIDIA cuEquivariance 和 NVIDIA TensorRT 等 NVIDIA 加速计算软件,我们实现了对 AFCDB 中大规模同源和异源复合体的高通量结构预测,为构建合成复杂数据奠定了基础。这些数据可能对训练能够代表生物学中更大系统的基础模型具有重要价值。
如需了解更多信息,请参阅玻尔兹 CP 代码开源文档并查看Fold-CP:用于生物分子建模的上下文并行框架。