
开发自动驾驶车辆(AV)政策需要弥合训练与部署之间的一个重要差距。能够对更复杂的驾驶场景进行推理并生成更丰富中间推理过程的视觉-语言-动作(VLA)模型,主要是在开放环路中训练的,在这种训练方式下,模型输出会直接与真实行为进行比较,而不考虑其对环境的影响。
然而,在部署时,驾驶策略以闭环方式运行,其中每一次制动、转向和导航决策都会影响环境,而微小的错误会随着时间推移而累积。
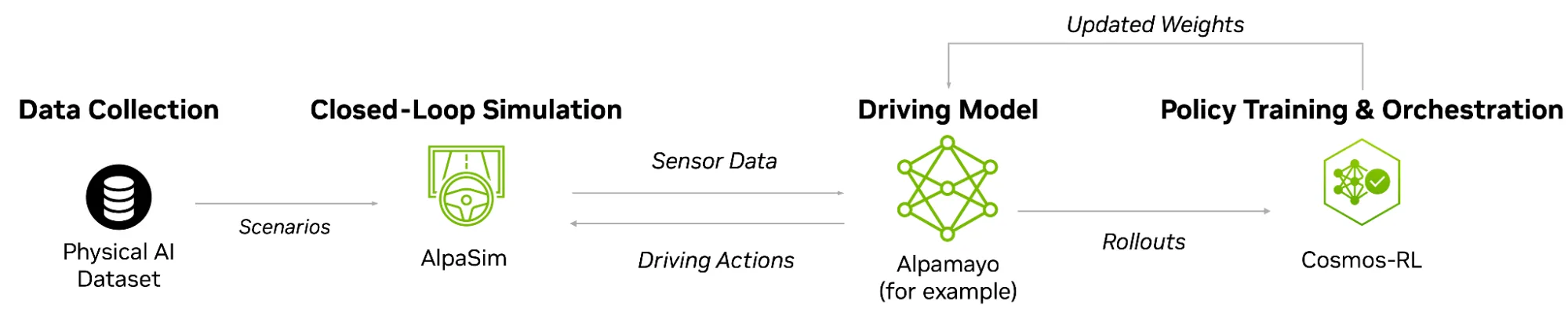
NVIDIA Alpamayo 提供了一种系统性的方法来应对这一挑战,它是一个面向自动驾驶汽车开发的开放式 AI 模型、仿真框架和 物理 AI 数据集组合。Alpamayo 包括 AlpaSim 自动驾驶仿真平台和 AlpaGym 闭环训练框架(即将推出)。
这篇文章解释了如何使用 NVIDIA Alpamayo 对自动驾驶汽车(AV)模型进行闭环训练。具体来说,它将逐步介绍如何:
- 安装并配置 AlpaGym
- 定义闭环奖励
- 启动闭环训练
- 导出后训练检查点供下游使用
闭环后训练通过将 AlpaSim 运行结果转化为训练经验,扩展了 AV 训练工作流程。AlpaGym 不再将仿真仅仅视为最终评估阶段,而是将模拟器反馈直接连接到策略训练循环。
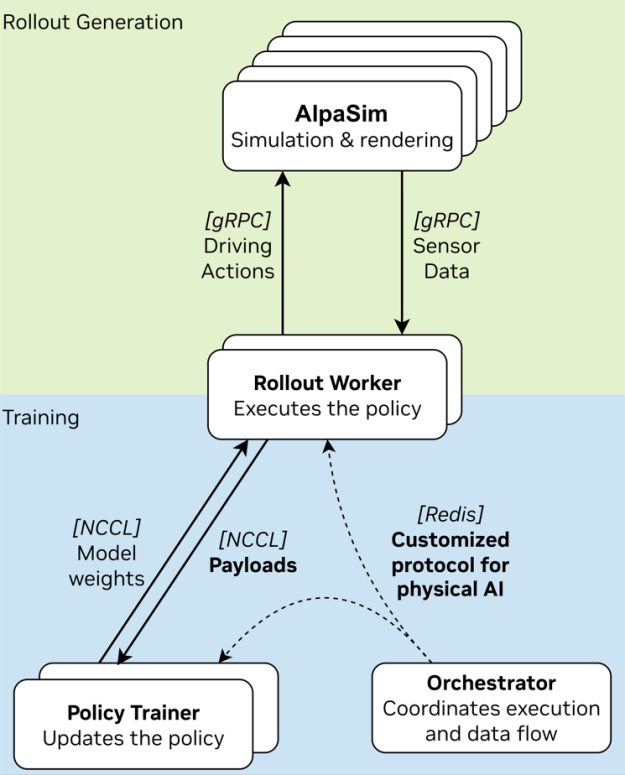
如何将 AlpaGym 用于闭环强化学习
强化学习(RL) 可用于改进最初以开环方式训练的策略。模型不再只针对已记录的专家轨迹进行优化,而是可以在仿真中从自身动作的后果中学习。
这种转变对自动驾驶汽车(AV)开发至关重要,因为微小的预测或规划错误会随着时间推移而累积。在闭环训练中,每一次刹车、转向和导航决策都会影响环境的下一个状态,从而揭示静态数据集或开环评估可能遗漏的失败模式。
然而,启用闭环强化学习本身也带来了挑战。模型推理、运行仿真、训练模型、同步权重更新、跨实例通信以及数据搬运——所有这些都要并行进行——这一过程非常复杂。这需要以稳健而灵活的方式进行编排,并高效利用计算资源。

为应对这些挑战,AlpaGym 将策略训练与 AlpaSim 的闭环回放连接起来,并提供了一个用于闭环强化学习的开源、高吞吐量框架。该系统将 AlpaSim 仿真器微服务, NVIDIA Physical AI 开放数据集 和 NVIDIA Cosmos-RL 训练框架结合为一个可扩展的后训练流水线。
可无缝扩展至从单个 GPU 到多节点 GPU 集群,AlpaGym 通过异步且稳定的分布式 RL 流水线支持高效的大规模训练,无需更改用户代码。它将 AlpaSim 和 Cosmos RL 作为其运行时和编排层,默认采用 GRPO 算法,并包含使用 Alpamayo 模型和 Physical AI AV NuRec 数据集测试的参考奖励函数。
开始使用 AlpaGym 后训练,请按照以下步骤操作。
步骤 1:安装并配置 AlpaGym
要从 Alpamayo checkout 安装 AlpaGym,请在主机上安装原生 CUDA 依赖项和 Redis,然后同步 UV 工作空间:
sudo apt-get updatesudo apt-get install -y libcudnn9-dev-cuda-12 \ libnccl-dev=2.26.2-1+cuda12.8 libnccl2=2.26.2-1+cuda12.8 \ redis-server git-lfsgit lfs installgit lfs pullhuggingface-cli login# Or export HF_TOKEN=...uv sync --all-packagessudo apt-get updatesudo apt-get install -y libcudnn9-dev-cuda-12 \ libnccl-dev=2.26.2-1+cuda12.8 libnccl2=2.26.2-1+cuda12.8 \ redis-serveruv sync --all-packages |
Python 环境由 uv 管理,但 cuDNN、NCCL 和 redis-server 二进制文件是由 CUDA 模型栈和 Cosmos-RL 使用的主机依赖项。此外,我们也提供了合适的 Dockerfile。下载场景工件需要 Hugging Face 身份验证。
AlpaGym 运行是一个 Hydra 配置。它指定策略检查点、AlpaSim 场景集、rollout 并行度、奖励函数以及 Cosmos-RL 训练参数。在此工作流程中,起始检查点是一个 Alpamayo 模型。
步骤 2:定义闭环奖励
奖励应当与您希望在闭环中改进的行为相匹配。对于轨迹质量的后训练,常见的奖励项包括进度、车道保持、避撞、越野率、舒适性,以及与参考轨迹的距离。
一个实用的首个奖励是有意设计得很简单:将进度与安全关键故障的惩罚结合起来。在 AlpaGym 中,这可以表示为若干项的一个小和,并在可能的情况下使用 AlpaSim 指标:
# reward/progress_safety.yamlterms: - kind: metric metric_name: progress scale: 1.0 - kind: metric metric_name: collision_any scale: -10.0 - kind: metric metric_name: offroad scale: -5.0 |
管道稳定后,为在 AlpaSim 视频和指标中观察到的故障模式添加更多有针对性的术语。
步骤 3:启动闭环后训练
从你的模型检查点开始 AlpaGym 训练。这里以 Alpamayo 作为示例模型。
uv run -m alpagym_host.cli \ policy=alpamayo \ policy.model.kind=alpamayo_r1 \ policy.model.path=/path/to/checkpoint \ reward=progress_safety |
这将会在单个 GPU 上启动带有 AlpaSim 的 AlpaGym。关于如何使用你自己的 AV 模型的详细说明,敬请期待。
训练期间,AlpaGym 向 AlpaSim 请求场景回放,收集每个回合的产物,计算奖励,并更新策略。有效的训练信号包括平均奖励、奖励方差、失败率、策略损失、回放吞吐量,以及生成的回放与最新策略权重之间的差距。
在此配方中,这些 rollout 工件和训练信号是后训练运行的主要输出。它们可帮助你确认闭环学习是否正常运行,并为你自己的保留 AlpaSim 场景套件选择用于下游评估的检查点。
步骤 4:导出后训练检查点
训练完成后,将 AlpaGym 生成的 checkpoint 和 config 文件放入一个 AlpaSim 驱动程序可以访问的文件夹中(例如你的 Hugging Face 模型缓存)。然后使用该文件夹路径创建一个新的 driver config(这里称为 alpamayo1_CLRL)。有关如何在 driver yaml config 中编辑以指定自定义路径,请参见下面的代码。这使得经过 AlpaGym 后训练的策略可以在 AlpaSim 中运行,用于闭环 rollout。
...model: model_type: alpamayo1 checkpoint_path: "/root/.cache/huggingface/alpasim_models/alpamayo1_CLRL/step_NNNNNN" device: "cuda"... |
接下来,在一个具有代表性的场景上运行导出的模型,以验证策略、驱动程序和仿真循环是否正确连接。在这一阶段,你可以检查当策略自身的动作会影响环境的下一状态时,它的行为表现。
uv run alpasim_wizard deploy=local topology=1gpu driver=alpamayo1_CLRL wizard.log_dir=$PWD/tutorial_alpamayo_CLRL scenes.scene_ids=[clipgt-9ea70552-6dcb-4ee8-a368-9a906a333f6e] |
闭环 rollout 提供有用的定性信号:模型是否生成稳定的轨迹并保持在可行驶区域内、它如何对附近的交通参与者作出反应,以及在后训练阶段应重点针对哪些失效模式。
有了这个检查点,团队可以检查训练过程中收集的 rollout 视频、逐集指标、奖励轨迹和失败案例。这些工件有助于调试奖励设计、检查 rollout 的稳定性,并为后续在 AlpaSim 中进行留出评估时选择检查点。
开始进行音频和视频模型的后训练
闭环后训练为迭代端到端驾驶策略提供了一条实用路径。在这种情况下,AlpaGym 使用闭环滚动在仿真中对自动驾驶车辆策略进行后训练,使其能够从其动作的后果中学习。
你可以将这些工具与 NVIDIA Alpamayo 开放平台的其他组件结合使用,开发可在闭环仿真工作流中运行、检查和后训练的推理模型。将同样的方案更广泛地扩展到你自己的奖励、场景和评估套件中。
准备开始了吗?查看 NVlabs/alpamayo-recipes 的 GitHub 仓库,将本文中的配方改造成适合你自己用例的版本。
要在公共排行榜上评估您的模型,请查看 NVIDIA 在 CVPR 2026 发布的两个开放式 AV 挑战:
欲了解更多信息,请参阅:扩展 Alpamayo 开放平台,以跨模型、数据和仿真开发推理型自动驾驶汽车。
与 NVIDIA 创始人兼首席执行官黄仁勋一起参加 NVIDIA GTC 台北 2026 主题演讲,并通过相关 会议 深入了解相关内容。