
AI 智能体从根本上改变了推理工作负载的复杂性。到目前为止,业界一直在努力定义用于衡量推理系统在这些条件下的性能的标准。Artificial Analysis AgentPerf (AA-AgentPerf) 提供了业界首个多供应商开放基准分析轨迹,这些轨迹代表了现实世界的 AI 智能体 编码任务。
本文将介绍 AA-AgentPerf 如何为衡量代理式工作负载性能设定新标准,以及 NVIDIA extreme 协同设计如何帮助提供比上一代高 20 倍的代理式编码性能。
什么是 AA-AgentPerf?
AA-AgentPerf 是由 Artificial Analysis 创建的硬件基准测试,用于测量推理系统可以支持的并发 AI 智能体数量,同时满足预定义的模型特定性能服务水平目标 (SLO) 层。SLO 定义为输出令牌速度和第一个令牌时间 (TTFT) 的特定值。对每个加速器和每兆瓦的基准测试结果进行归一化,以便跨硬件配置进行比较。
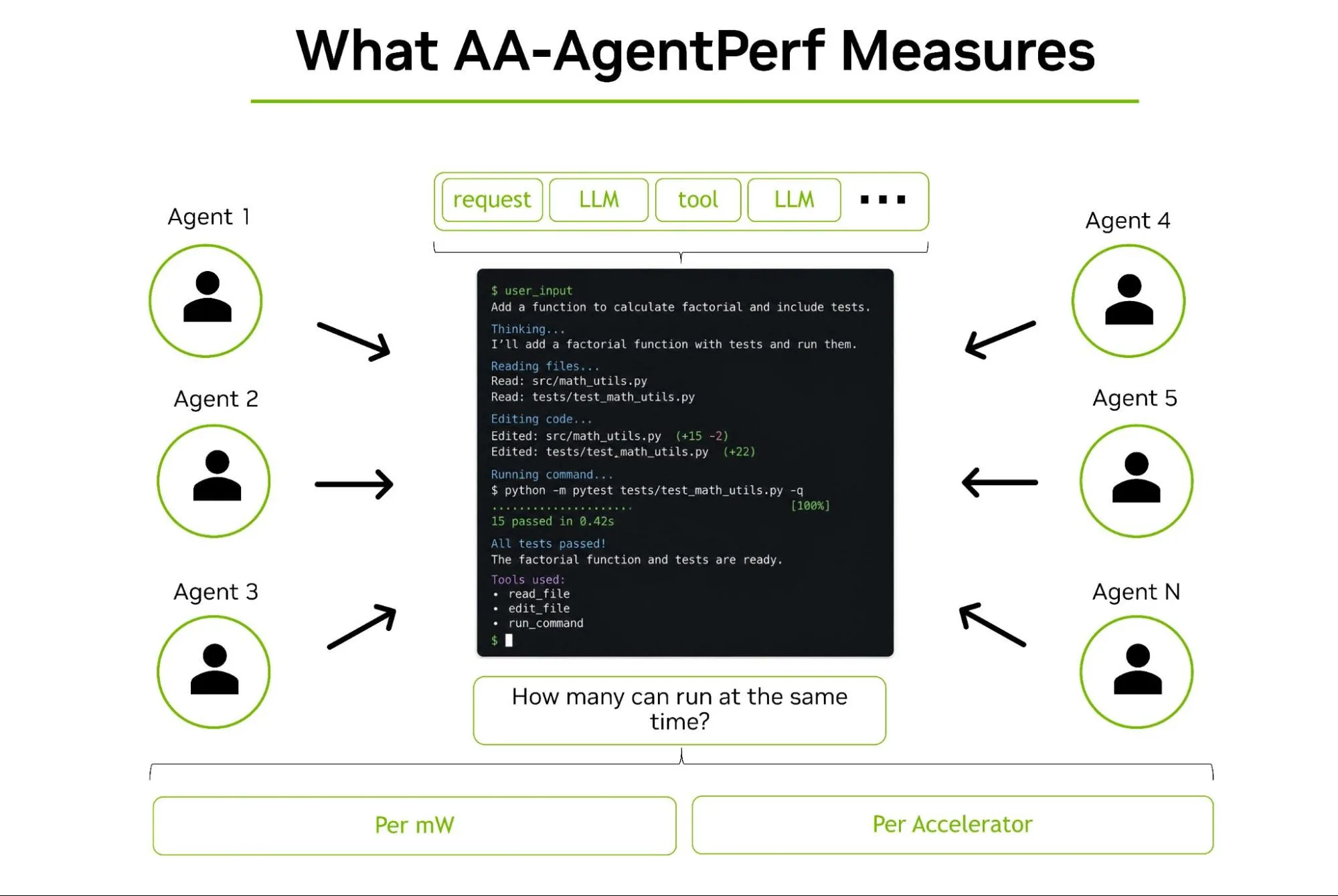
测量具有代表性的代理式编码性能
由于 LLM 驱动的决策通常会产生请求和工具调用的非确定性序列,因此代理式工作负载是独一无二的。衡量智能体表现最困难的部分是在具有代表性的智能体轨迹中准确捕捉这种非确定性,即智能体从头到尾遍历任务时的完整动作、决策和观察序列 (图 2) 。
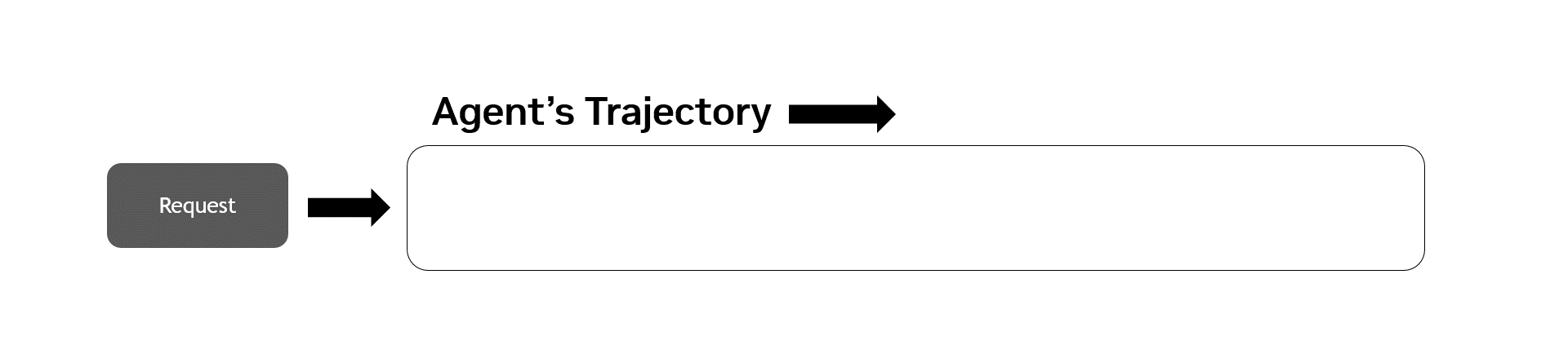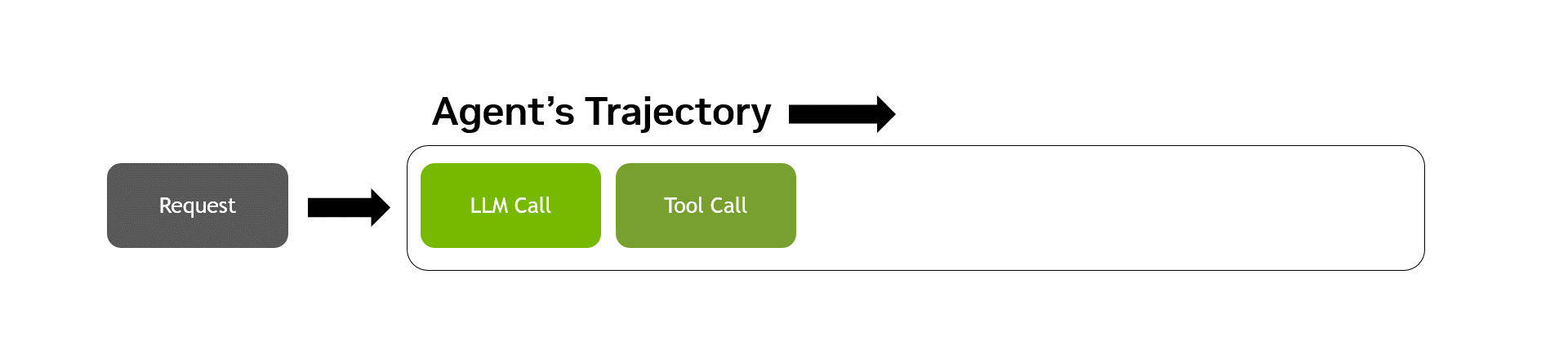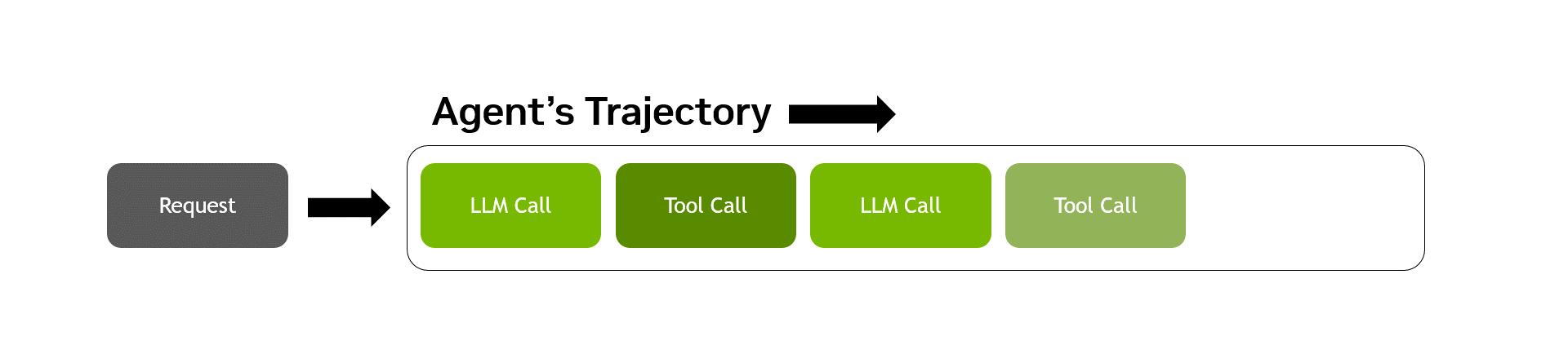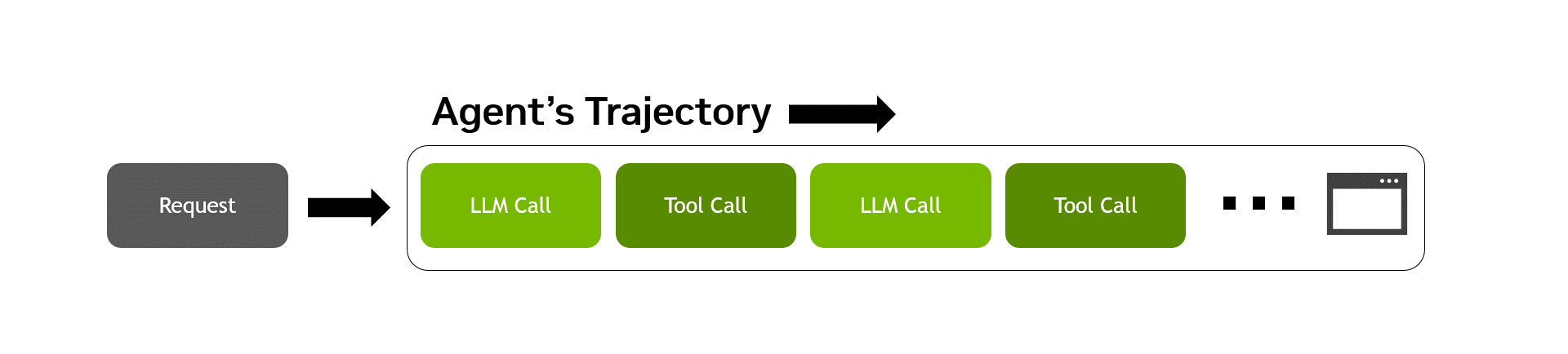
AA-AgentPerf 通过交错推理和工具使用来测量预先录制的代理式编码轨迹中的 GPU 性能,同时使用具有代表性的 CPU 工具调用性能基准来模拟间延迟,从而实现了这一点。这些轨迹围绕解决公共代码库中的问题而构建,涵盖多个用例、12 余种编程语言以及前沿模型的响应。除了严格定义轨迹之外,人工分析团队还:
- 利用具有代表性的缓存、输入和输出序列长度处理请求,范围从 5K 到 131K 不等,均值约为 27K。
- 在代理式编码工作流中对具有代表性的 CPU 端任务进行映射工具调用,并在整个分布中进行模拟工具调用,中间延迟时间为 1 秒。然后,在所有测试系统中应用相同的 CPU 工具调用基准。
- 保持测试集的私密性,以防止出现针对基准的优化。
AA-AgentPerf 测试和测量方法
AA-AgentPerf 线束可测量推理系统在满足 SLO 要求的同时可支持的并发智能体数量 (图 3) 。在启动时,此基准测试专注于跨多个 SLO 层测试 DeepSeek-V4-Pro,这些 SLO 层来自于人工分析无服务器 API 基准测试数据。这可确保基准测试反映当今生产提供商中观察到的服务质量水平。
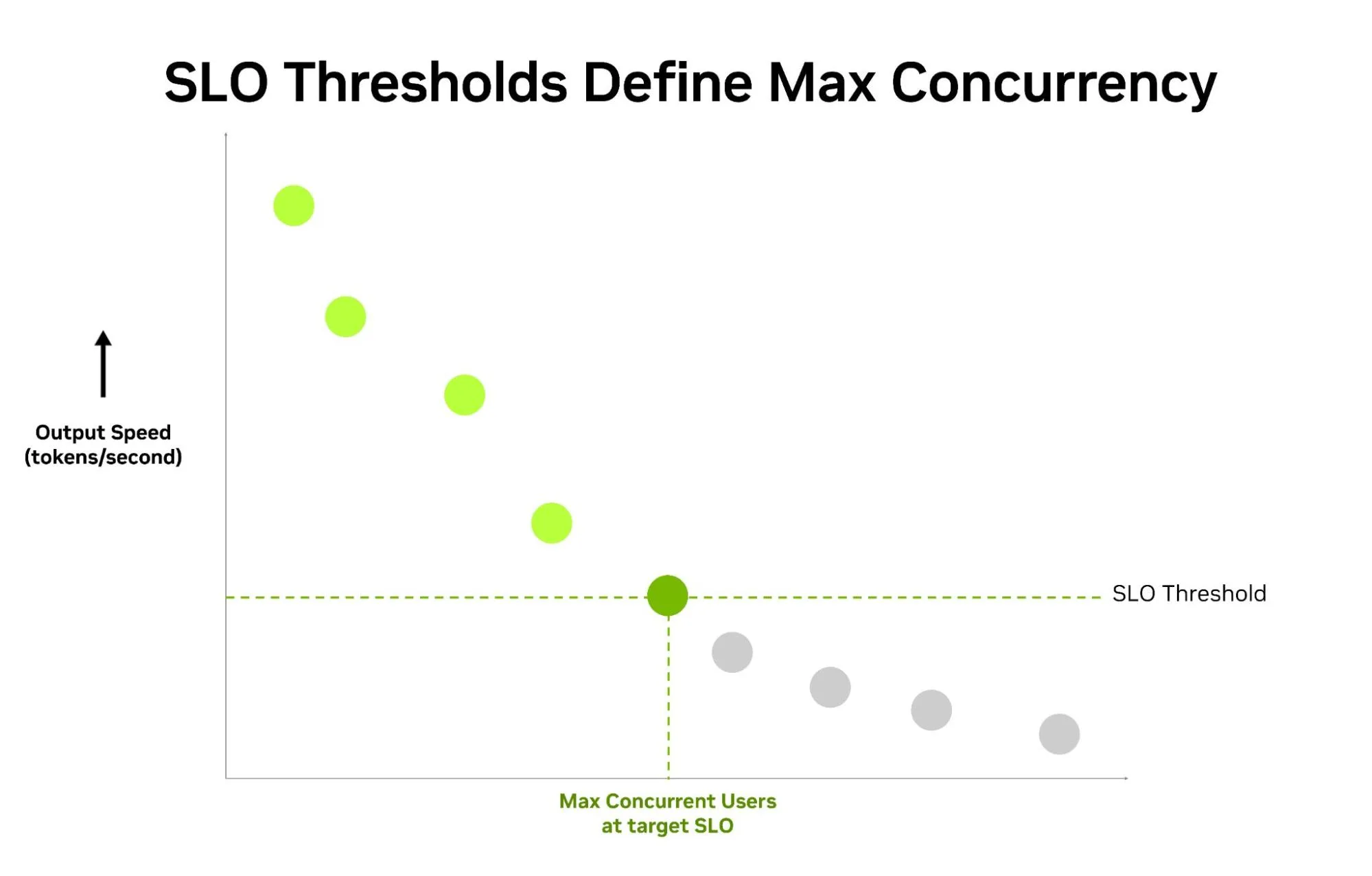
在基准测试运行期间,AA-AgentPerf 会向 GPU 发送从其预先录制的智能体轨迹数据集中提取的数千个并发请求。为确保每次运行获得独立结果,我们会在每个轨迹阶段开始时添加动态前缀。在整个轨迹中强制执行严格的 SLO 值,并将满足这些要求的最高并发级别记录为给定 SLO 的官方基准测试结果 (图 3) 。然后,在多个 SLO 层中重复此过程,以捕获不同的用户体验目标 (表 1) 。
| 模型 | SLO 层 | P25 输出速度 (Token/ 秒) | P95 TTFT (秒) |
| DeepSeek-V4-Pro | SLO 1 | 30 | 10 |
| SLO 2 | 100 | 5 | |
| SLO 3 | 300 | 3 |
如何解读 AA-AgentPerf 结果
核心 AA-AgentPerf 指标是每兆瓦运行时功率,这是表示数据中心规模性能的实际标准化。表 2 概述了如何利用报告的性能来估算给定功耗预算下可支持的代理会话数量。
| 基准测试 | 指标值 | NVIDIA GB300 NVL72 | NVIDIA H200 |
| 每兆瓦并发代理数 | 能效:给定功耗预算下,系统可以支持的活动代理数量 | 61.4 K | 2.6 K |
| 每个 GPU 的并发代理数量 | 硬件效率:每个 GPU 实现的服务容量 | 57.5 | 1.4 |
在发布当天,与上一代 NVIDIA H200 相比,NVIDIA GB300 NVL72 每兆瓦可提供多达 20 倍的并发代理 (图 4) 。
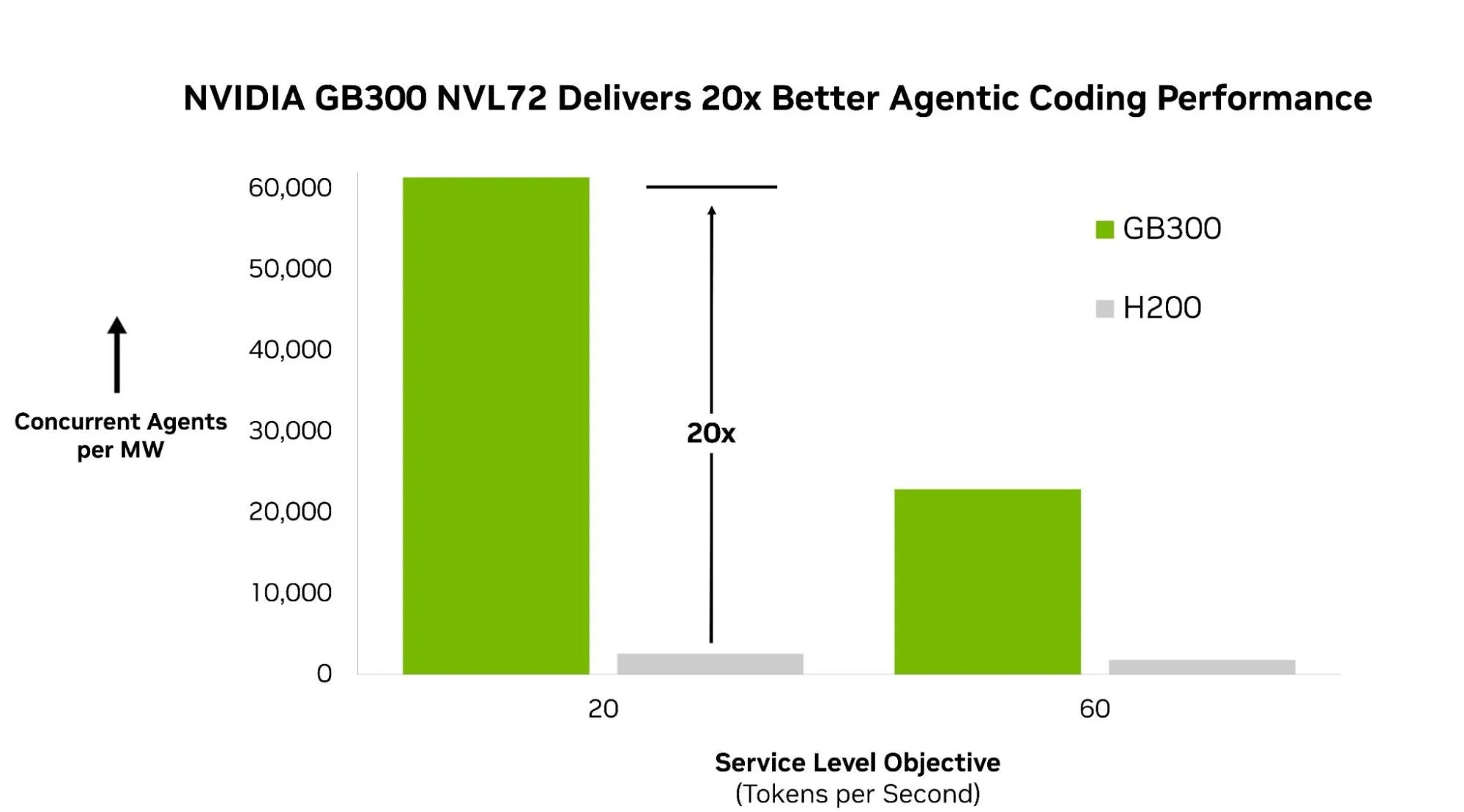
此性能凸显了 GB300 NVL72 能够在大规模代理式编码工作负载中提供支持,从高效路由长生命周期会话到在许多并发智能体会话中充分利用混合专家 (MoE)和 GPU。
- SGLang、TensorRT LLM或 vLLM: 智能体运行时应用 WideEP 和 DeepEP 等优化,将 MoE 专家执行扩展到整个 NVL72 域,从而更大限度地提高有效批量大小,并有效扩展到数千个智能体。
- DeepGEMM 和 Mega MoE 优化: MXFP4/ MXFP8 内核和融合的 MoE 将 NVLink 通信与 Tensor Core 计算重叠,以提高用于推理和代码生成的 token 吞吐量。
- NVIDIA NVLink 纵向扩展域: GB300 NVL72 将 72 个 GPU 连接至单一高带宽 NVLink 网络,使每个 GPU 都能快速共享参数、KV 缓存和中间结果——这对代理编码系统的快速、协调执行至关重要。
展望未来:NVIDIA Vera Rubin 平台
AA-AgentPerf 建立了评估代理式推理的标准,其结果凸显了紧密集成的硬件和软件如何在并发性和效率方面实现跨步功能提升。NVIDIA GB300 NVL72 展现出高达 20 倍的代理式编码性能。
NVIDIA Vera Rubin 平台预计将利用 50 PFLOPS 的 NVFP4 计算能力,并利用 Vera CPU 加速 LLM 工具调用,并提高智能体工作流的端到端性能、经济效益和效率,从而扩展这些收益。
如需详细了解代理式工作负载对推理基础设施提出独特要求的原因,以及 NVIDIA Vera Rubin 平台 如何优化性能,请参阅 借助极致协同设计构建日益复杂的代理系统。
致谢
这项工作得益于 Jatin Gangani、Iman Tabrizian、Xiaoming Chen、Peiheng Hu、Tai Zhong Wu、Shichen Li、Manu Maheswari 以及许多其他才华横溢的 NVIDIA 工程师的专业知识和工程贡献。