
单轮聊天机器人正在演变为长时间运行的智能体,这些智能体可以进行推理、维护上下文、使用工具,并在多轮中高效运行,从而完成复杂的工作流程。
但是,这些多智能体工作流程会导致词元数量快速增长。智能体计划、调用工具、调用子智能体、接收信息,然后将历史记录、输出和推理步骤持续返回到模型中。随着任务运行时间的延长,这种持续的通信会增加成本和目标漂移的风险。
开发者可以使用模型系统解决这一问题:前沿推理模型用于编排和复杂规划,以及用于大规模执行、验证和工具调用的高效模型。
NVIDIA 将发布 NVIDIA Nemotron 3 Ultra,这是一种开放模型,旨在帮助长时间运行的智能体更快地完成任务,同时降低成本。
用于智能体编排的 Nemotron 3 Ultra
Nemotron 3 Ultra 是一个具有 550B 活跃参数的 550B 参数混合专家模型,专为代理式系统中的前沿推理和编排而构建。
在任何智能体工作流中,大多数调用都是常规调用,但关键子集需要更深入的推理。Nemotron 3 Ultra 专为应对这些棘手的挑战而打造:在编码会话中维持架构决策,综合数百个研究来源中的矛盾证据,或在数千种限制条件下验证芯片设计。
| Nemotron 3 Ultra ( 550B) | GLM 5.1 ( 744B) | Kimi K2.6 ( 1T) | Qwen3.5 ( 397B) | |
| 智能体生产力 PinchBench | 91% | 84% | 91% | 89% |
| 长远规划企业运筹 | 33% | 40% | 29% | 30% |
| CodingTerminal-Bench 2.0 | 54% | 64% | 67% | 53% |
| 以下说明 IFBench | 82% | 77% | 74% | 78% |
| 知识工作 GDPVal-AA | 1,448 | 1,594 | 1,508 | 1,192 |
| 专业工作任务 ProfBench (搜索) | 56% | 46% | 56% | 53% |
| 长上下文标尺 = 1M | 95% | 不适用 (最大 256K) | 不适用 (最大 256K) | 90% |
Nemotron 3 Ultra 速度也非常快。与同类中的其他开放模型相比,它的吞吐量提高了 5 倍,使长时间运行的智能体能够更快、更高效地完成任务。
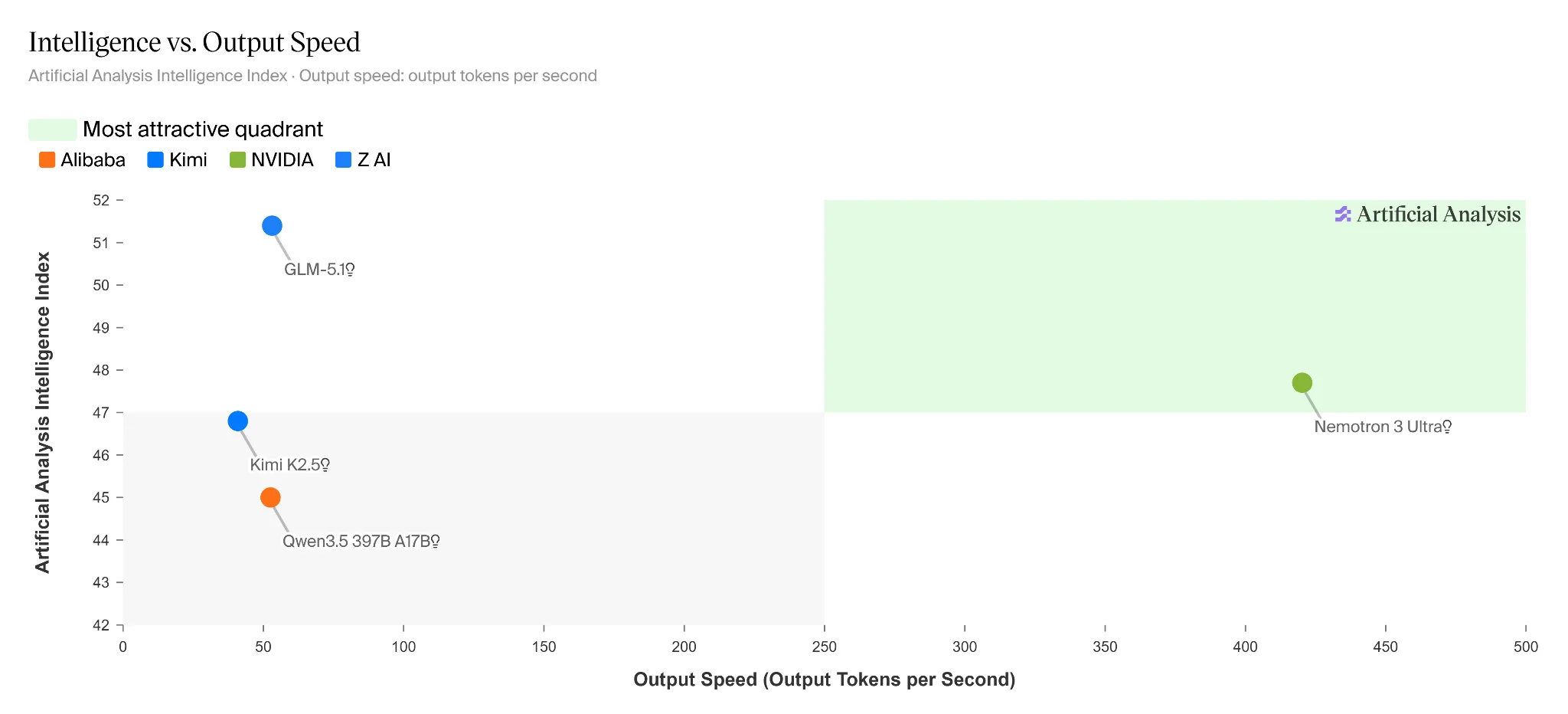
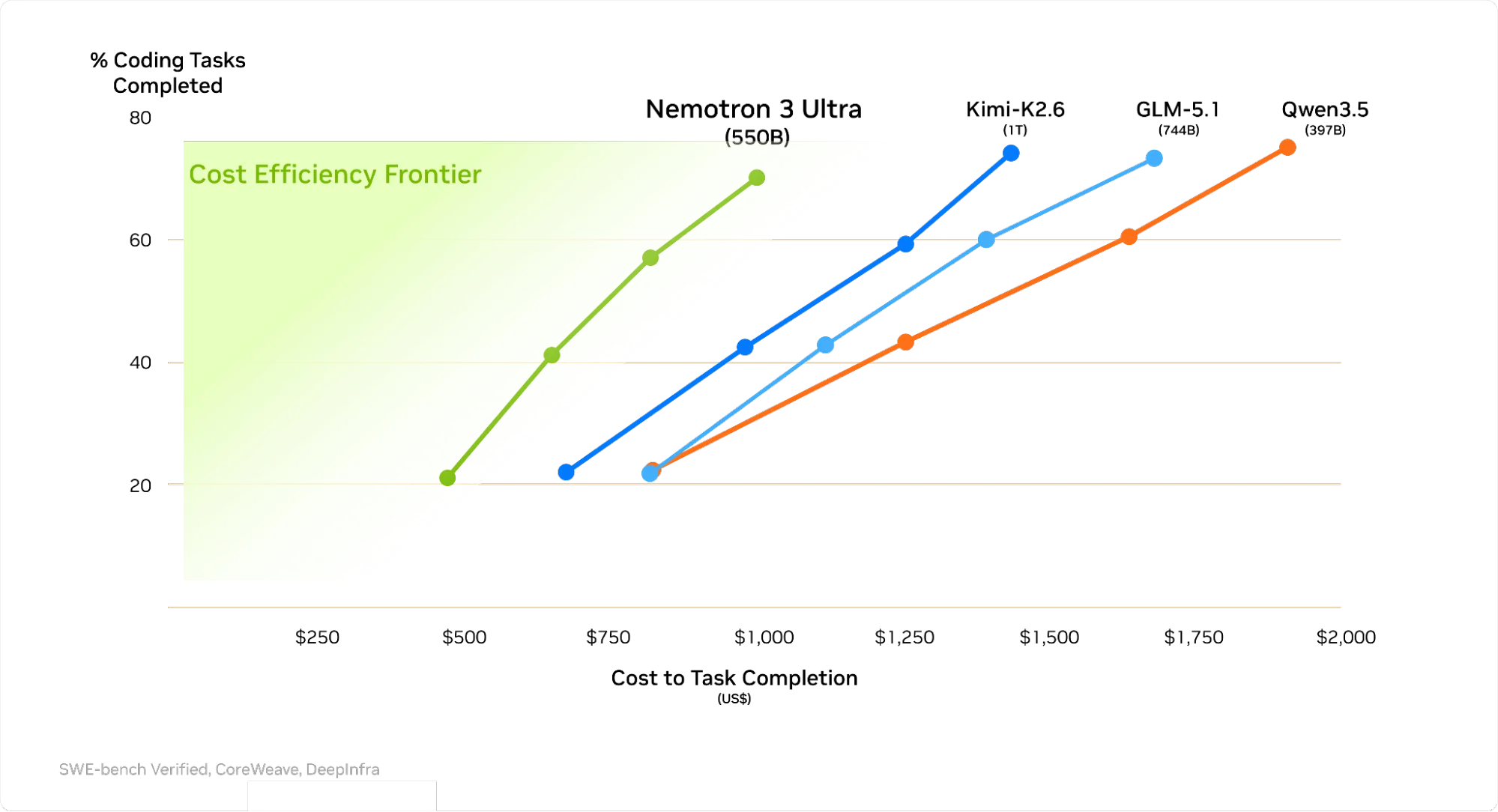
Nemotron 3 Ultra 也专为提高效率而打造。在 SWE-bench 和 Terminal bench 2.0 上的实验中,与同类模型相比,它在完成基准测试时使用的词元总量更少,而且每回合词元数量更少。这可将代理式任务的成本降低高达 30%。
为 Nemotron 3 Ultra 提供动力支持的突破性技术
为了缓解高容量推理模型在效率 – 准确性方面的典型权衡,Nemotron 模型引入了架构创新:
针对智能体线束进行后训练
Nemotron Ultra 经过后训练,可在顶级线束上提供一致的准确性。该模型使用 NVIDIA NeMo RL 和 Gym 开放库进行训练,其中包含全球最大的长期运行、任务解决、使用工具的数据集之一。
Ultra 针对智能体主导的开放式工具 (而不仅仅是单轮聊天) 进行了优化,旨在在智能体规划、调用工具、读取观察结果、委托给子智能体、验证输出以及从多个回合的错误中恢复的工作流中工作。
混合式 Mamba transformer
Mamba 层可提高长上下文工作负载的序列效率,而 Transformer 层可在智能体需要从大型上下文窗口中检索特定事实时保留精确的召回率。
NVFP4 精度
NVFP4 检查点在 NVIDIA Hopper、NVIDIA Blackwell 和 Ampere GPU 上运行相同。得益于专用的 NVFP4 量化内核,开发者可以在所有 NVIDIA GPU 架构中使用一个检查点。NVFP4 也在相同的交互性下提供高达 5 倍的每个 GPU 吞吐量,相比之下基于 Blackwell 的 BF16。
LatentMoE
LatentMoE 支持更高效的专家路由,使模型能够处理涵盖推理、代码生成、工具调用和领域特定逻辑的工作流。
Multi-词元 prediction
Multi-词元 prediction (MTP) 通过在单个前向传递中预测多个未来词元,帮助缩短生成时间,从而提高长输出和多轮工作流程的吞吐量。
Nemotron 3 Ultra 增加了多教师策略蒸馏功能
多教师策略训练方法蒸馏 (MOPD) 是一种训练方法,其中 Ultra 会从多个专业教师模型中学习,同时在训练期间生成自己的尝试。我们训练了 10 多个专业教师模型,每个模型都有自己的特定领域训练流程。每个教师都会在其专业领域对模型进行评分,帮助 Ultra 更高效地改进跨领域推理。
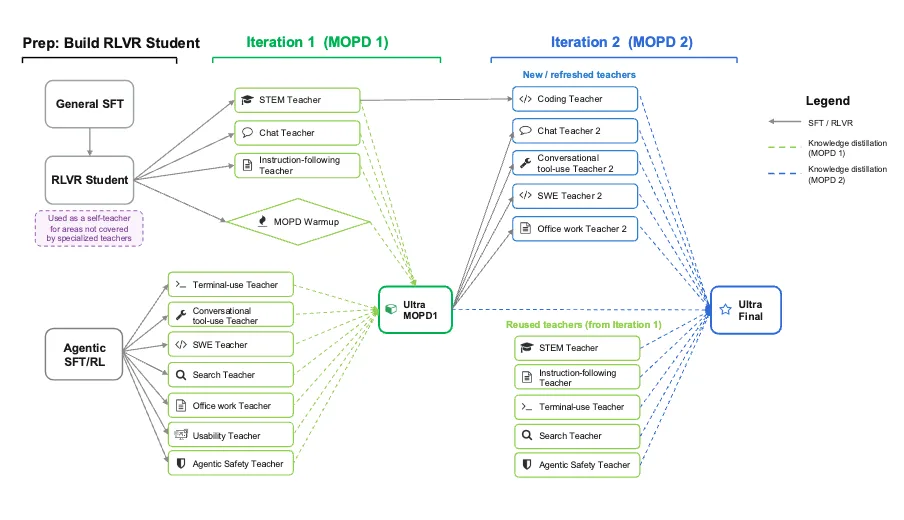
在 MOPD 期间,学生模型会跨领域生成部署结果,并从相应的教师模型接收密集奖励信号。为更大限度地提高效率,MOPD 异步运行,学生发布生成、教师评分和学生优化完全流水线化。
MOPD 也是迭代的。生成经 MOPD 训练的检查点后,从更新的学生模型初始化新一轮教师训练,并将改进合并到下一个 MOPD 阶段。
学生和教师之间的这种共同进化能够持续提高能力,并逐步加强跨领域的专业化。用户可以通过训练 Ultra 模型的 NeMo-RL 库来尝试 MOPD recipe。
训练数据以增强智能体推理
与所有 Nemotron 开放模型的启动一样,大部分训练数据工作流都尽可能以宽松的方式发布。对于企业和主权 AI 开发合作伙伴而言,训练数据透明度和来源与能力一样重要。
特定领域的预训练数据
Nemotron 3 Ultra 基于 10T 词元预训练基础构建,新增 212B 个词元,目标是三个高价值领域差距:
- 4B 词元合成法律数据,将代理 LegalBench 平均值从 64.6% 提高到 74.7%
- 350 亿词元基于 Wiki 的合成数据,将代理 SimpleQA 从 40.2% 提升至 50.2%
- 173B 已更新 GitHub 词元至 2025 年 9 月 30 日
后训练数据和 RL 环境
此次发布还发布了 1000 万个新 SFT 样本、跨多个领域的 100 万个新 RL 任务和 15 个全新 RL 环境,使 Nemotron 累积开放数据总数达到 5000 万个 SFT 样本、200 万个 RL 任务和 55 个 RL 环境。
结果,SWEBench 在 Pi、OpenHands、Hermes、OpenCode 和 Mini SWE Agent 上的验证得分在 65% 到 70.4% 之间,无论您部署哪种框架,性能都保持一致。
针对您的域进行微调
Nemotron 3 Ultra 可以使用 LoRA、SFT 和使用 NVIDIA NeMo 库的强化学习进行微调。开发者可以从以下方法着手。
Nemotron 3 Ultra 技术诀窍:
- SFT LoRA:NeMo Automodel (H100 Recipe、GB200 Recipe)
- 完整 SFT:NeMo Megatron 桥接器方案 方案
- 强化学习:NeMo RL GRPO recipe、GRPO LoRA recipe、MOPD recipe
部署
使用 Dynamo Recipe 部署 Nemotron Ultra,以实现 KV 感知路由、多词元预测 (MTP) 以及解预填充/ 解码。
查看实际应用
本演示展示了如何在 NVIDIA 官网 ( www.nvidia.cn) 上使用由 Nemotron 3 Ultra 提供支持的 Hermes Agent 启动和运行自动研究流程。
借助 NVIDIA NemoClaw 和 NVIDIA OpenShell,更安全地运行智能体
Nemotron 模型与领先的开放智能体框架集成。要构建始终在线的安全代理式系统,必须了解参考堆栈:
- Hermes Agent 和 OpenClaw:这些是热门的智能体工具,可为多轮工作流提供编排循环、内存和工具。Hermes Agent 现已正式发布,完全支持与 Nemotron 一起使用。
- NVIDIA OpenShell: OpenShell 现已提供早期预览版,是自主代理及其生成的代码执行的安全运行时环境 ( NVIDIA Agent Toolkit 的一部分) 。
- NVIDIA NemoClaw:这是一个将环境联系在一起的开源蓝图。只需一条命令,NemoClaw 就能安装 OpenShell 运行时,从而提供一个安全的环境,以便更安全地运行自主代理 (例如,Hermes Agent) 以及 Nemotron 等开源模型。
构建更安全的语音智能体
两个新的 Nemotron 模型也将推出:
Nemotron 3.5 内容安全
对于团队构建更安全的企业 AI 而言,Nemotron 3.5 内容安全是一个开放、高效的 4B 护栏模型,用于对文本、图像和组合输入中的不安全、不允许或违反策略的内容进行分类。
它涵盖 23 个安全类别和 12 种语言,可用作推理时的护栏、LLM 安全测试和评估的判断工具,或与随附的训练数据集一起用于对模型进行后训练,以实现更安全的行为。自定义策略支持和推理追踪可帮助企业根据特定领域的规则调整安全决策、审核分类,并在全球 AI 工作流中部署安全控制。阅读 Hugging Face 博文 了解详情。
Nemotron 3.5 ASR
对于语音原生代理,Nemotron 3.5 ASR 使用与其英文前代 Nemotron 3 ASR 相同的缓存感知流架构,可即时处理音频增量。消除冗余缓冲计算,可确保延迟低于 100 毫秒,从而为代理式集群实现自然、实时的语音编排。
英语模型已得到开发者的广泛采用,包括为 Microsoft GitHub Copilot CLI 中的语音输入功能提供支持,该功能已被超过 2000 万开发者使用。一项包含 50 多种本地 ASR 配置的独立基准测试将 Nemotron 3 ASR 确定为在资源受限的硬件上进行实时英语串流的最强候选项。现在,该架构支持多种语言,可在单个检查点中支持 40 多种语言。
更新了开放许可,以实现更广泛的采用
Nemotron 模型版本将转移到 OpenMDW-1.1,这是 Linux 基金会专为开放 AI 模型发行版打造的宽松许可证。OpenMDW 旨在涵盖单个框架下的全套模型材质,包括架构、参数、文档、软件和其他相关构件。
这为开发者和企业使用、修改、重新分发和部署 Nemotron 模型提供了更明确的条款,同时减少了许可模糊性,这可能会拖慢开放模型的评估和采用。
立即开始构建
Nemotron 3 Ultra 是完全开放的,包括权重、数据和配方,因此开发者可以根据特定领域的工作流程调整模型,并将其部署到任何地方。它可在领先的推理平台上使用,并被打包成 NVIDIA NIM 微服务,可以在任何地方运行。
使用专业版订阅在 Perplexity 上试用,或通过 API、OpenRouter、Anaconda 或 build.nvidia.com 试用。
从 Hugging Face,魔搭社区下载权重,通过 NVIDIA NIM 启动优化实例,或从指南开始,只需几分钟即可运行。
Nemotron 3 Ultra 通过合作伙伴生态系统提供:
- 模型定制服务:应用计算、Prime Intellect、Unsloth
- 推理软件:SGLang、TRT-LLM、vLLM
- 云服务提供商: Amazon SageMaker JumpStart、Google Cloud、Microsoft Foundry、Oracle Cloud
- 推理服务提供商:Baseten、DeepInfra、 Eigen AI、fal (ASR) 、 Fireworks AI、FriendliAI、Modal、Ollama Cloud、Simplismart
- AI 云和服务:BitDeer AI、CoreWeave、Dell Enterprise Hub、Crusoe、DigitalOcean、GMI Cloud、Lightning AI、Nebius 词元 Factory、Together AI、Vultr
请查看 GitHub 资源库,了解智能体的入门说明,包括 BlackBox AI、Cline、CrewAI、Factory AI、Hermes Agent、Kilo Code、LangChain Deep Agents、OpenClaw、OpenCode、OpenHands 和 Pi。
如需了解完整的技术细节,请参阅 Nemotron 3 Ultra 技术报告。
通过订阅NVIDIA Nemotron并在LinkedIn、X、Discord和YouTube上关注 NVIDIA AI,及时了解 NVIDIA 新闻。
访问 Nemotron 开发者页面 获取入门资源。在 NVIDIA 官网 ( www.nvidia.cn) 上探索 Hugging Face 上的开放 Nemotron 模型和数据集以及 Blueprints 在 build.nvidia.com。
在 Nemotron 直播、教程,以及在 NVIDIA 论坛 和 Discord上与开发者社区互动。