
AI 智能体正在改变您与 PC 的交互方式。创作者、开发者和 AI 爱好者已经在广泛使用这些智能体来协助完成编码、视频编辑和内容管理等日常任务。
NVIDIA 和 Microsoft 正在合作,使新一代开发者能够在 Windows 平台上构建设备端智能体,并提供更简单的设置、原生安全性以及与开发者已使用的应用和工具的集成。
本文详细介绍了 NVIDIA 和 Microsoft 在 NVIDIA GTC 台北大会和 COMPUTEX 2026 和 Microsoft Build 2026 上推出的新工具,以满足对智能体的激增需求。这些工具包括原生 Windows 上的一站式智能体沙盒、速度提高 2 倍的智能体推理、Nous Research 和 H Company 推出的全新智能体应用和工具,以及跨 llama.cpp 和 ComfyUI 的增强型多 GPU 支持。本地 AI 开发堆栈现已准备好与用户一起运行复杂的代理式 AI 工作流。
如何使用 Microsoft eXecution Containers 和 NVIDIA OpenShell 保护本地智能体
在 Microsoft Build 上,Microsoft 发布了一套安全基元,允许智能体通过内置标识和策略执行跨系统执行代码、操作文件和编排任务。Microsoft eXecution Containers (MXC) 构成了策略层,用于定义和分析隔离和遏制,同时依靠本地 Windows 操作系统结构来应用这些策略。
对于开发者而言,这降低了一个关键障碍:代理与个人文件和应用交互会带来真正的提示注入风险,而 MXC 则确保他们无法访问整个系统。
NVIDIA 还与微软合作,将基于 MXC 构建的 NVIDIA OpenShell 运行时引入 Windows。通过 OpenShell 集成 MXC 为开发者提供了一个易于集成的软件包,使其能够安全地部署始终开启的自主智能体,同时还提供了其他功能,例如策略创建和管理、推理路由和个人身份信息 (PII) 混淆。
热门代理式应用希望利用 MXC 和 OpenShell 来增强其在 Windows 中的安全性,其中包括热门的开源代理 OpenClaw 和 Hermes Agent。
NVIDIA RTX Spark 如何为个人 AI 智能体提供支持?
在本周早些时候的 GTC 台北大会上,NVIDIA 发布了 NVIDIA RTX Spark 产品系列,包括专为个人助理时代打造的小型台式机和笔记本电脑。这些台式机和笔记本电脑提供 1 petaflop 的 AI 性能、高达 128 GB 的显存,以及 CUDA 加速的 AI 框架,可在日常工作的同时运行大型模型。
Microsoft 正在打造 RTX Spark 开发者特别版 Surface RTX Spark 开发者套件,该套件预装了专为开发者配置的 Windows 修改版以及入门所需的热门开发者工具。如需了解详情,请参阅为开发者构建新一代设备:Surface RTX Spark Dev Box。
NVIDIA NemoClaw、Hermes Agent 和 H Company 如何扩展智能体功能?
NVIDIA NemoClaw 用于构建 自主 AI 智能体,现在通过 Linux 和适用于 Linux 的 Windows 子系统 (WSL) 支持所有 NVIDIA 客户端系统,包括 GeForce RTX、NVIDIA RTX PRO、NVIDIA DGX Spark 和 适用于 Windows 的 NVIDIA DGX Station。这使您能够轻松设置和沙盒智能体,并为您的硬件精心挑选经过优化的本地模型。此次更新还包括对安装程序的增强功能,使其更轻松、更顺畅。NemoClaw 现在还支持作为选项运行 Hermes Agent。
本周,Hermes Agent 还发布了原生 Windows 支持,包括命令行界面以及时尚的全新桌面应用程序。这简化了用户体验,同时使智能体能够更轻松地与本地 Windows 应用、API 和文件进行交互以及使用这些应用、API 和文件。
此外,AI 研究和产品公司 H Company 还发布了全新 Holo 3.1 系列模型。这些模型针对“计算机使用”进行了调整,这种模式使智能体能够通过查看屏幕并单击来采取行动,从而将智能体功能扩展到更广泛的应用范围。其中包括量化检查点,与 FP8 相比,内存减少了 35%。该公司还宣布即将推出一款支持本地模型的新型计算机线束。NVIDIA 已帮助 H Company 优化其新模型,并在 NVIDIA GPU 上提供超过 2 倍的性能。
NVIDIA 和 OSS 社区如何为本地代理式 AI 加速推理?
随着智能体每周 7 天、每天 24 小时运行日益复杂的任务,高效的本地计算变得更加重要。NVIDIA 与开源社区合作,增强智能体、llama.cpp 和 vLLM 的顶级推理后端。
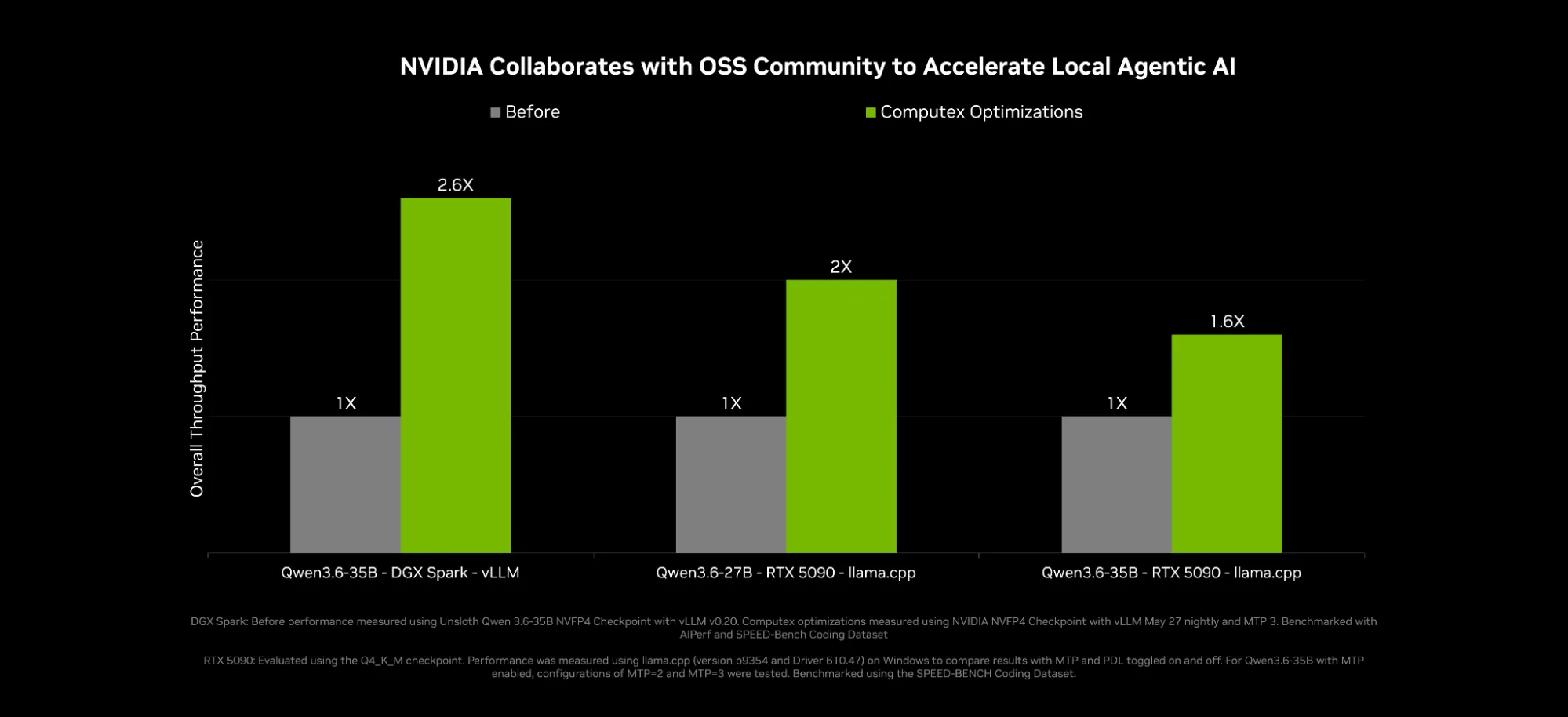
llama.cpp 现在可在 Qwen 3.5 和 3.6 27B 密集型模型上提供 2 倍的性能,在 Qwen 3.5 和 3.6 35B 多专家模型 (MoE) 上提供 1.6 倍的性能。以下两种技术可实现这一点:
- Multi-词元 Prediction (MTP):一种先进的预测解码技术,较小的草稿模型提前提出多个词元,以便目标模型在单次正向传递中进行验证,在相同的输出质量下提供更快的吞吐量。MTP 对开发者来说是最实用的,因为它不需要对已经支持它的模型进行额外的训练。
- 编程依赖启动 (PDL):此更新可提供更快的解码性能。可在同一 CUDA 流上同时执行相关内核。在此之前,单个 CUDA 流中的相关内核必须是顺序的。
vLLM 已采用 MTP,但还将获得额外的优化,推理性能将提升 2.6 倍。其中包括为 MoE 模型选择更好的 BF16 内核,以及通过改进 CUDA 计算图降低运行时开销。
您现在可以通过 LM Studio、llama.cpp 和 vLLM 开始探索这些更新。
多 GPU 如何支持 RTX PC 的大规模 AI 性能?
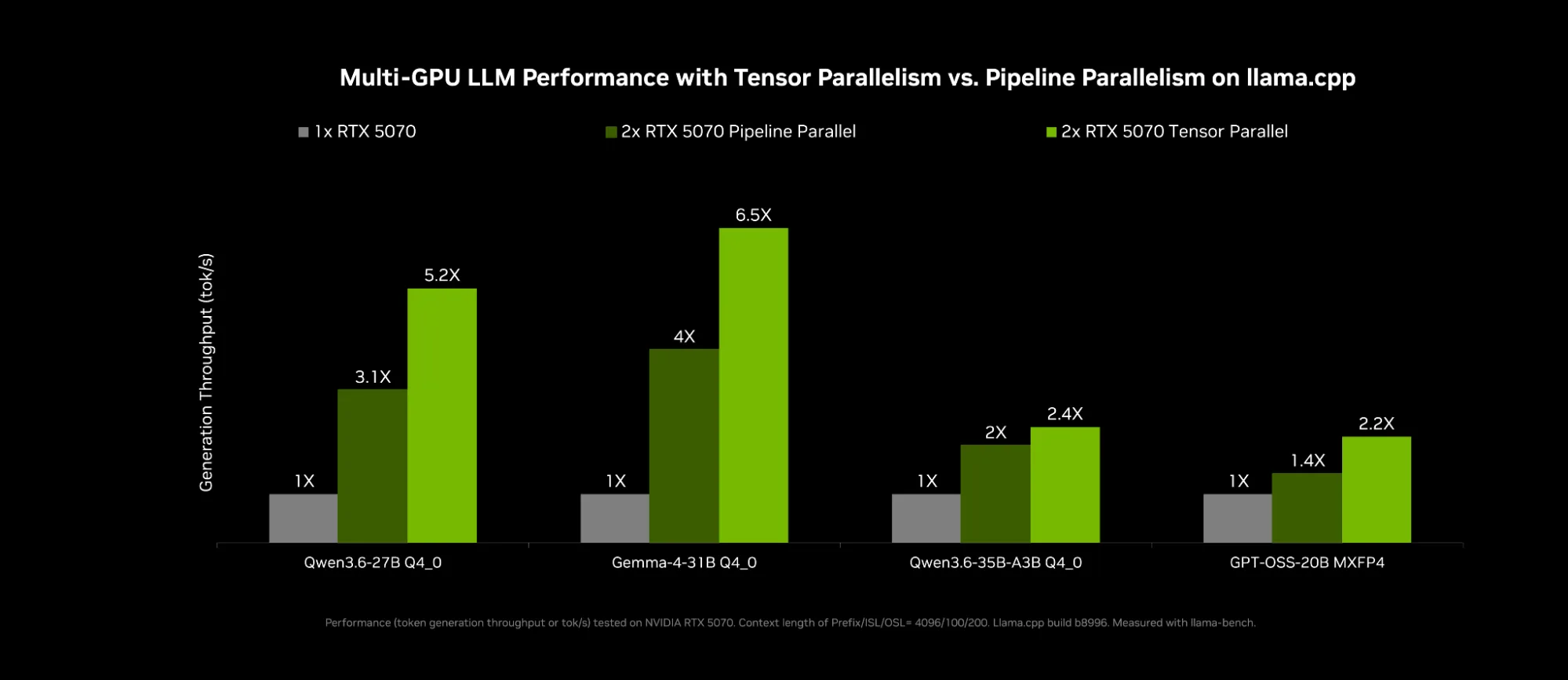
本地运行 AI 的一种常用方法是使用多个 GPU 来访问更多内存和计算。虽然 vLLM 等云框架因其在数据中心的使用而针对多个 GPU 进行了良好的优化,但 llama.cpp 和 PyTorch 中的 ComfyUI 实现等 PC 框架并没有针对它进行优化。
为了应对这一挑战,NVIDIA 与 llama.cpp 和 ComfyUI 合作,使用两个同等 GPU 提升 RTX PC 的性能。这使您能够运行更大的模型,并使用两个 GPU 的计算来获得更好的性能。
llama.cpp 现在支持张量并行 (TP) ,可充分利用这两个 GPU,实现高达约 2 倍的显存容量和约 1.8 倍的计算性能。LM Studio 已将这些更改提供给更广泛的应用。要开始使用 LM Studio,请打开 LM Studio 应用,选择“Settings” (设置) ,然后选择“Runtime” (运行时) 以启用 TP。
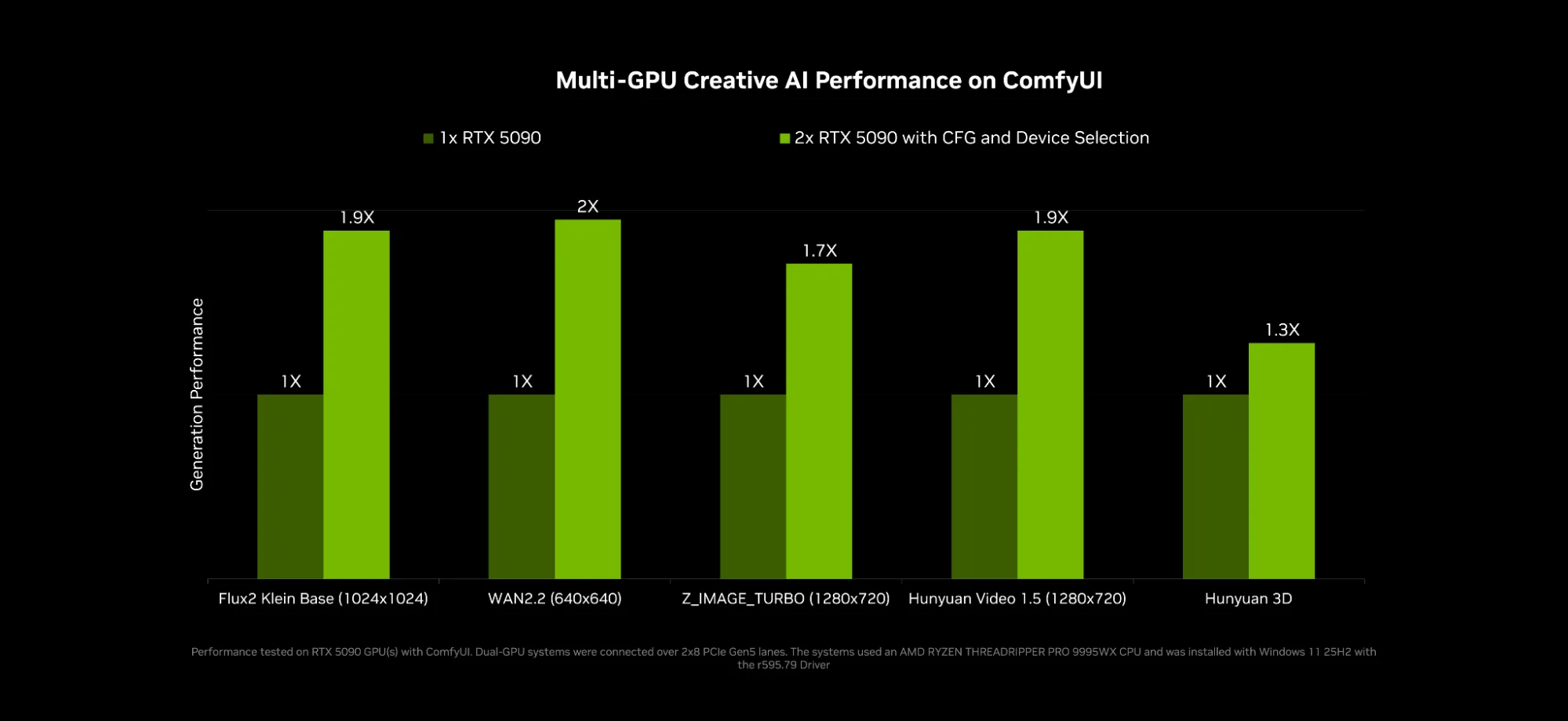
ComfyUI 集成了无分类器引导 (CFG) 方法,可跨两个 GPU 实现高达 2 倍的计算。用户还可以在 GPU 上分割模型链,将其完全加载到内存中,从而运行高显存模式。这消除了低显存模式的显存交换开销,进一步提升了性能。
要开始使用多 GPU 推理,请查看 llama.cpp GitHub 资源库和 如何构建多 GPU AI PC。
媒体和视频开发者有哪些新功能?
NVIDIA AI for Media SDK (AI4M) 现可供构建 AI 赋能的视频和广播工作流的开发者进行私密访问。它包含以下功能:
- LipSync 已正式发布: 经过语言优化的模型现已支持法语、德语和西班牙语,与基础模型相比,LipSync 可实现更高质量的配音和内容本地化,并且清晰度更高。
- 主动扬声器检测 (ASD) GA: 增强的多摄像头和多麦克风支持以及跨视频扬声器 ID 关联解锁了自动化工作流程(口型同步配音、视频编辑和高级日志记录),这些工作以前需要手动完成。
更多用于在 Windows 上进行 GPU 加速 AI 开发和部署的工具
采用 Windows ML 的更广泛的 Windows AI 平台继续成熟,由 NVIDIA TensorRT for RTX 在 NVIDIA GPU 上提供支持。开发者现在可以通过多种途径在 Windows 应用中提供 GPU 加速的 AI。
Windows AI Foundry 和 Windows AI API 现已支持 GPU 加速。当您在 RTX 硬件上调用受支持的 API 时,系统会路由工作负载,以在 NVIDIA GPU 上实现更高性能的本地推理。第一个受支持的模型是 Phi-Silica,这是一个 33 亿的小语言模型 (SLM) ,用于摘要、重写、代码生成和其他设备端 AI 任务。
适用于 RTX 的 Windows ML 和 TensorRT 继续获得发展势头。最近,四家合作伙伴从 DirectML 进行了升级:
- Voicemod 将实时 AI 语音转换速度提高 42%
- Topaz 可将 1080p 到 4K 的图像放大速度提高 20%,同时将引擎存储空间减少 3-4 倍
- DxO PhotoLab 9.7 提供更快的 AI 照片处理速度
- Camo Streamlight AI 自动调整功能可实时智能调整光照水平
对于有兴趣在 Windows 中运行 Linux 应用程序的用户而言,适用于 Linux 容器的新 Windows 子系统 (WSL-C) 是一种内置方式,可用于创建、运行本地 Windows 应用程序中的 Linux AI 容器并与之交互。应用程序用户无需自行安装和管理 WSL 系统资源,开发者可以使用 C/ C++ 库将此功能构建到其应用程序中。WSL-C 可直接在 Windows PC 上解锁复杂的专业级开发环境,使您能够更快完成工作、在本地进行迭代,并与生产工作流保持一致。
开始在 Windows PC 上构建个人 AI 智能体
AI 智能体正在重塑软件的构建、使用和部署方式,NVIDIA RTX 上的本地 AI 堆栈已准备就绪。借助安全智能体沙盒、更快的推理、多 GPU 扩展和成熟的 Windows AI 平台,在全球超过 1 亿台 NVIDIA RTX PC 上构建的开发者拥有了发布新一代 AI 应用的基础设施。
了解详情并 开始针对 NVIDIA RTX AI PC 进行开发。