
现代金融网络上的每一次刷卡、转账和付款都会对人类行为模式进行编码。事务数据是企业掌握的最丰富的信号之一。然而,此类表格数据的大多数生产用例仍然依赖于手动设计的特征和规则集,这些特征和规则集很脆弱,维护费用高昂,并且对客户历史中的顺序结构视而不见。
在大量未标记的交易序列上进行预训练的基础模型,通过生成跨各种下游任务传输的金融行为的通用表征来改变这一方程。单个主干涵盖欺诈检测、信用评分、生命周期价值预测、细分、个性化推荐、循环交易检测等。
行业信号强劲且不断加速。创新型金融公司正在针对数十亿笔交易训练基于 Transformer 的模型,在简化运营的同时,报告生产规模任务的相对提升达到两位数。了解 Stripe 的 支付基础模型、Nubank 的 NuFormer、Visa 的 TransactionGPT、Mastercard 的 大型表格模型、Revolut 的 PRAGMA、Plaid 的 交易基础模型 等。
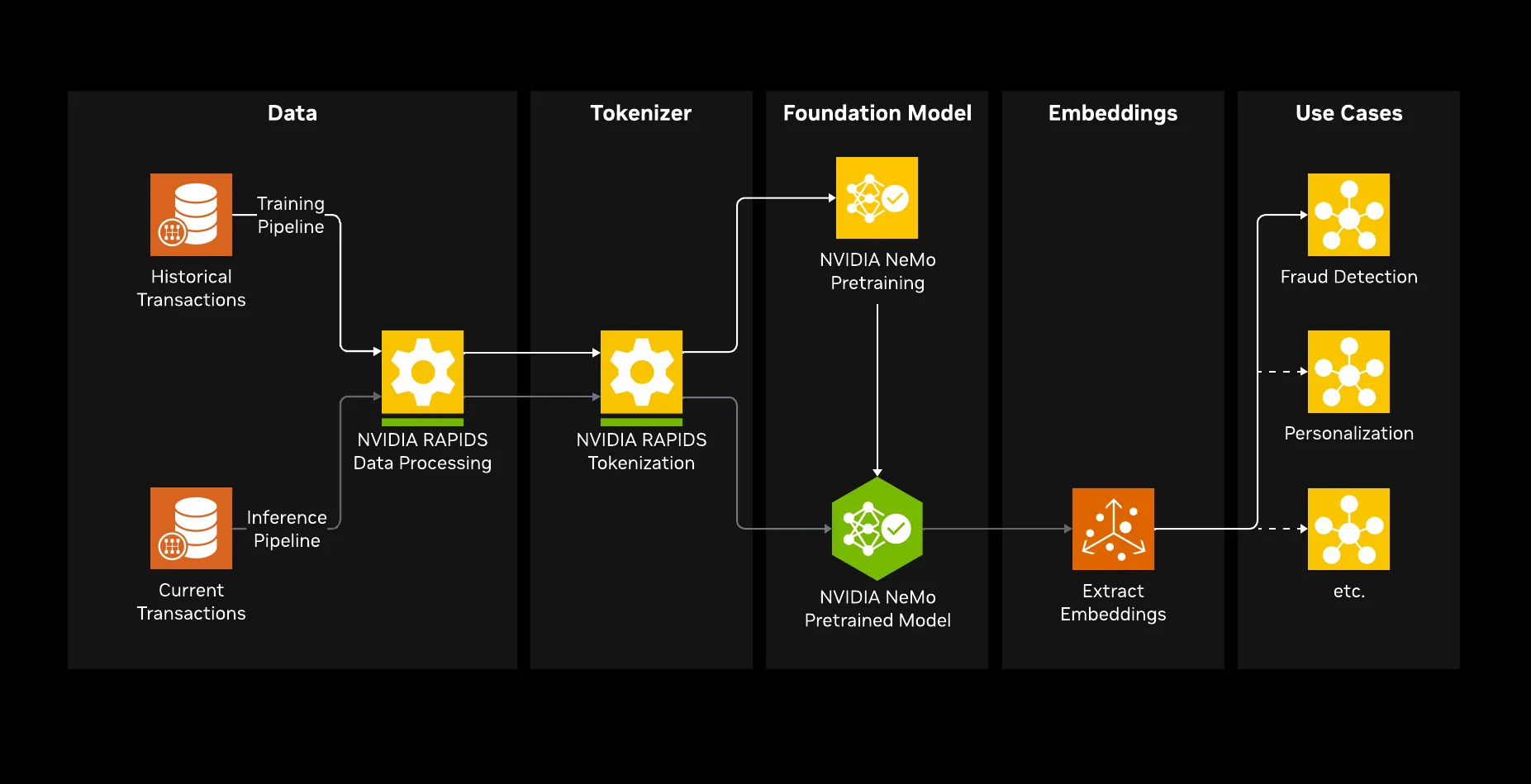
NVIDIA 构建您自己的事务模型 开发者示例将介绍如何使用加速计算端到端构建事务基础模型。
您将在此工作流程中完成五个步骤:
- 使用 NVIDIA CUDA-X 库 cuDF 进行 GPU 加速数据处理
- 使用 NVIDIA CUDA-X 库 cuDF 和 cuML 实现自定义标记化
- 使用 NVIDIA NeMo AutoModel 开放库 ( NVIDIA NeMo 框架的一部分) 从头开始进行 Transformer 解码器模型预训练
- 提取学习到的嵌入
- 通过嵌入增强下游欺诈分类器
最后,在 IBM TabFormer 欺诈数据集上的强 XGBoost 基准上,平均精度 (“AP”) (精度召回曲线下的区域,即捕捉模型在所有操作值中对欺诈进行排名的程度) 将提升近 50%。下图 1 显示了端到端工作流,基于 IBM TabFormer 欺诈数据集。
为何 Transformer 符合事务历史记录
大语言模型从单词序列中学习。在预训练期间,模型会查看文本,并学习单词、短语和句子通过顺序和上下文具有意义。事务基础模型也将同样的原则应用于财务行为。“工资押金、杂货店购买、中转费用、定期订阅、持卡餐厅付款”等序列包含任何交易行都无法单独表达的信息。
Transformer 非常适合这种结构,因为自注意力可以连接历史上相隔遥远的事件。只有当与最近的旅行模式或突然爆发的少量授权搭配使用时,欺诈性交易才会显得可疑。传统的表格特征可以近似呈现这些模式,但工程师必须决定预先构建哪些窗口、聚合内容和规则。预训练的 Transformer 会直接从序列中学习这些关系。
这种方法是对其他 NVIDIA 金融 AI 工作流的补充,包括使用图形神经网络 (GNN) 检测金融欺诈的 NVIDIA AI Blueprint。GNN 捕获帐户、商家、设备和交易等关联实体之间的关系。事务基础模型专注于客户或帐户序列中的行为历史记录。在实践中,这两种方法都会生成具有自然配对的互补信息的丰富嵌入。
加载数据并设置基准
Notebook 01_dataset_baseline.ipynb 使用 IBM TabFormer 数据集,大约 24.4M 合成卡事务,~0.12% 欺诈率,直接加载到 GPU 显存中以 cuDF。
数据集拆分按累积事务计数进行时间划分:按日期划分的前 80% 的事务用于训练;下一个 10% 用于验证;最后 10% 用于测试。因此,这些拆分会占用不相交且有序的时间窗口,从而防止数据泄露并反映现实世界的生产环境。
拆分完成后,Notebook 会在一个 100 万行的平衡训练样本上利用原生 GPU 加速以及 tree_method="hist" 和 device="cuda" 来训练 XGBoost 分类器。评估基于 10 万个分层的阻碍因素运行,从而保持实际的+ 0.1% 欺诈流行率。
基准数字为教程的其余部分设定了标准:
- 测试 ROC-AUC:0.9885
- 测试 AP:0.1238
注意 AP 而不是 ROC-AUC。在 0.1% 的等级不平衡情况下,ROC-AUC 会迅速饱和,并隐藏高评分区域中有意义的差异。AP 测量整个召回曲线,并在重要的运营领域对改进做出响应。本教程中的每个后续模型都先由 AP 进行评判。
在 GPU 上标记化事务
通用型 LLM 分词器浪费表格财务数据的能力。例如,字节对编码 (BPE) 分词器将单笔交易拆分成大约 39 个子词令牌,其中大多数编码是逗号和美元符号,而不是行为。Notebook 02_seq_preproc_tokenization.ipynb 引入了一个自定义域分词器,可将每个事务转换为大约 12 个词汇量更小的语义令牌 ( 6251 个符号与 BPE 的 50257 个符号相比) 。
除了 token 信息密度之外,这种效率还可以使设置的 token 预算的事务数量增加 3 倍以上。实际上,上下文窗口值为 4092 的模型可以拟合域分词器中大约 315 笔交易的历史记录,而 BPE 分词器中只有大约 102 笔交易的历史记录。
下方图 2 比较了相同记录上两种标记化方法之间每笔交易的标记数量。
域分词器在 src/分词器/financial_pipeline.py 中实现。这种灵活的工作流可处理金额合并、商家哈希、一天中的时间和一周中的日期、月份、卡片身份、芯片类型、ZIP3 和状态以及客户身份。每个步骤都通过 cuDF 在 GPU 上运行。
通过添加或替换模块化流程中的各个步骤,分词器可以轻松适应不同的事务模式。每个步骤都实现了一个小型 BaseTokenizer 接口,因此将覆盖范围扩展到设备 ID 或受益国家 地区等新字段只需要一个简短的子类。
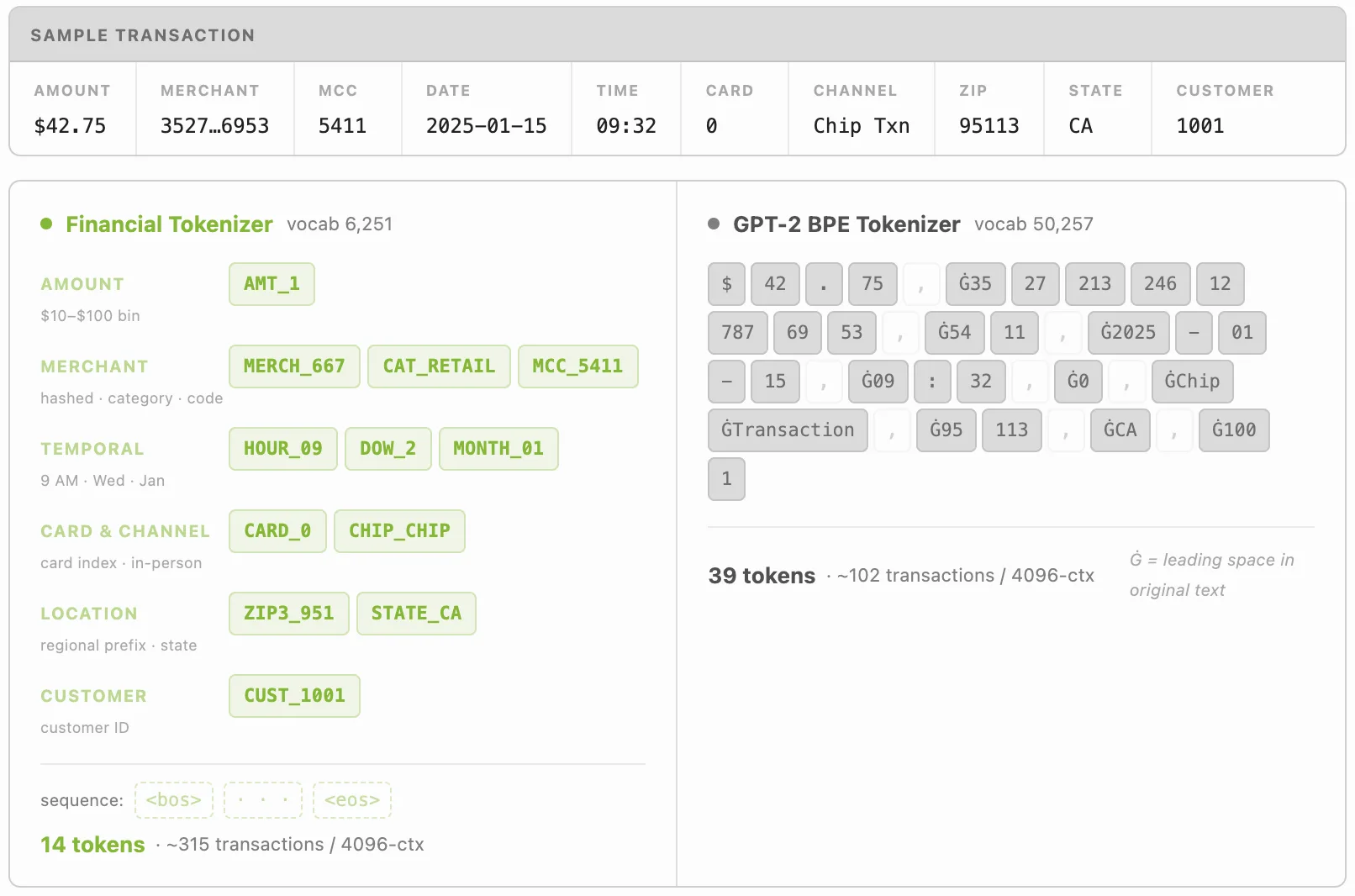
图 2. 域分词器 (约每笔交易 12 个令牌,6251 个符号词汇) 和 GPT-2 BPE (约每笔交易 39 个令牌,50257 个符号词汇) 在同一 TabFormer 记录中的令牌效率比较
使用 NeMo AutoModel 进行预训练
NeMo AutoModel 是 NVIDIA NeMo 框架下的 Pytorch 原生开源训练库,旨在简化和扩展 LLM 和 VLM 的训练和微调。
Notebook 03_foundation_model_training.ipynb 使用因果语言建模在标记化语料库上预训练仅解码器的基础模型。目标很简单,即根据之前的每个 token 预测下一个 token,但监督信号是密集的。序列中的每个位置都会提供一个梯度,因此单个打包的事务序列会生成数千个下一个事件预测。
该模型是在 configs/pretrain_financial_decoder.yaml 中定义的紧凑型 Llama 解码器:
- 约 2900 万个参数
- 隐藏大小 512,8 个 Transformer 层
- 具有 8 个查询头和 2 个 KV 头的 Grouped-Query Attention
- 8192 令牌 RoPE 上下文窗口
- SwiGLU 激活,RMSNorm,6251 个令牌的领域词汇
NeMo AutoModel 会处理堆栈的其余部分。启动单 GPU 正常运行。
python scripts/train_decoder_model.py \
--config configs/pretrain_financial_decoder.yaml \
--step_scheduler.max_steps 30
30 步演示将训练损失从 ln(6251)≈8.74 (此词汇表的随机猜测基准) 降低到 6.0 左右。要将相同的运行规模扩展到 8 个 GPU,只需使用 torchrun --nproc-per-node=8 作为命令的前缀,无需更改脚本或分布式样板。多节点扩展也很简单。NeMo AutoModel 与 YAML 连接了 FSDP2 分片、混合精度、梯度累积和检查点整合。
Checkpoints 以标准 safetensors 文件的形式登陆,这意味着经过训练的主干网络会在安装 HuggingFace Transformer 的任意位置加载单行代码:
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("models/decoder-foundation-model")
存储库发布了一个经过 3000 步训练的完整检查点,并加载 Notebook 04 和 05;30 步测试用于演示和验证目的。
如要交换架构,请在 YAML 中编辑 model._target_ 和 model.config._target_。任何兼容 HuggingFace 的解码器均可插入,无需更改训练代码。
大规模提取嵌入
Notebook 04_inference_embedding_extraction.ipynb 可将预训练的主干转换为特征提取器。它使用 AutoModelForCausalLM 加载检查点,请求 output_hidden_states=True,并将最终隐藏层池化为每个用户历史记录中 512 个维度的向量。
对于仅解码器且具有因果注意力的模型,只有最终位置观察到了整个序列,而先前的位置对后来的标记视而不见。因此,最后令牌池化会在序列中选择信息量最大的位置。src/decoder_inference.py 中的实现使用注意力遮罩来查找每行的最后一个非衬垫标记,并收集其隐藏状态。
提取循环是一次调用:
embeddings = inference.extract_embeddings_batched(
padded_ids, batch_size=1024, show_progress=True
)
Notebook 会提取训练、验证和测试嵌入,并将其保存为 .npy 文件。此外,系统会保存描述形状和行对齐的 metadata.json,稍后 Notebook 05 会使用该文件将嵌入连接回关联的原始表格特征。
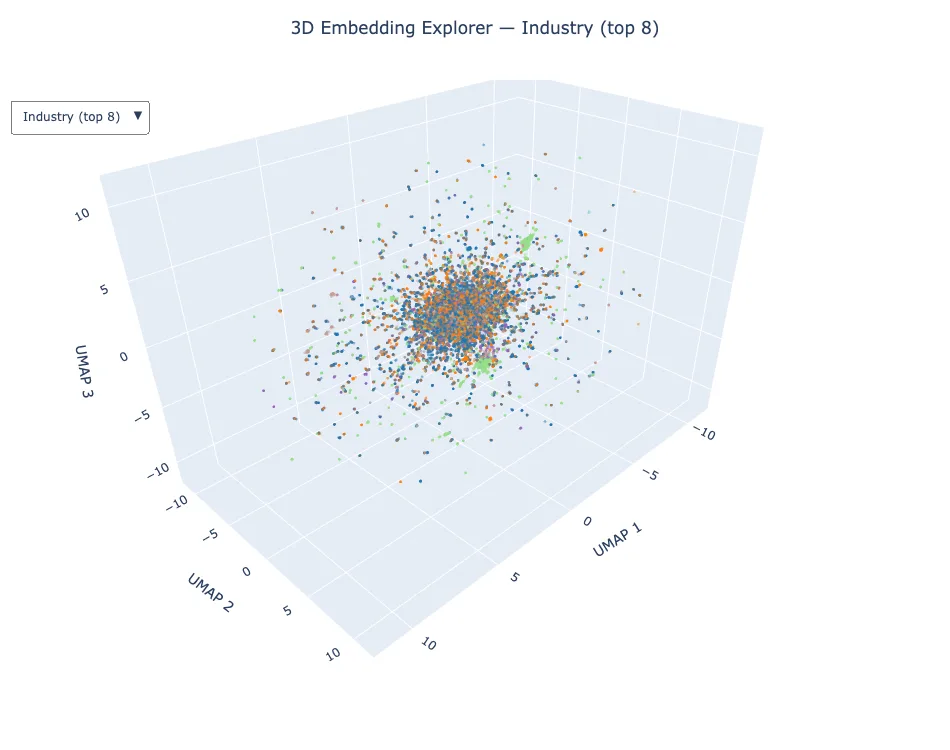
下图 3 显示了 5 万个验证嵌入的 3D UMAP 投影,按商业行业类别和邮政编码着色。每个字段中的可见集群确认,主干已学习语义一致性表示,而在预训练期间从未看到任何目标标签。
测量下游任务的提升
Notebook 05_xgboost_fraud_detection.ipynb 回答了数十亿美元的问题:事务基础模型嵌入能否移动下游指标?
它训练三个 GPU XGBoost 分类器,并在同一个 10 万个分层测试集上对所有分类器进行评估:
- 原始数据 – 13 个手动设计的表格特征 (第 1 步中的基准)
- 嵌入 – 使用 PCA 将 512 维基础模型向量压缩为 64 维 (保留约 78% 的方差)
- 组合 – 原始特征与 64d 嵌入相连接,总计 77d 个
下表 1 总结了测试结果。
| 模型 | 特征维度 | 测试 ROC-AUC | 测试 AP |
|---|---|---|---|
| Raw (基准) | 13 | 0.9885 | 0.1238 |
| 仅限嵌入 | 64 | 0.8775 | 0.0123 |
| 组合 | 77 | 0.9925 | 0.1755 |
与基准相比,合并后的模型将 ROC-AUC 提高了 0.41%,AP 提高了 41.76%。这种 AP 增量是运营上的制胜法:具有固定日常工作能力的审查团队在相同的工作负载下捕获大量欺诈行为。
嵌入对用户的交易历史记录进行编码并提供预测能力,但作为单独的特征,其性能却低于基准。组合模型利用了来自原始表格行的事件级信息,以及来自预训练期间学习的嵌入的序列级历史上下文。下方的图 4 直观地显示了对比结果。
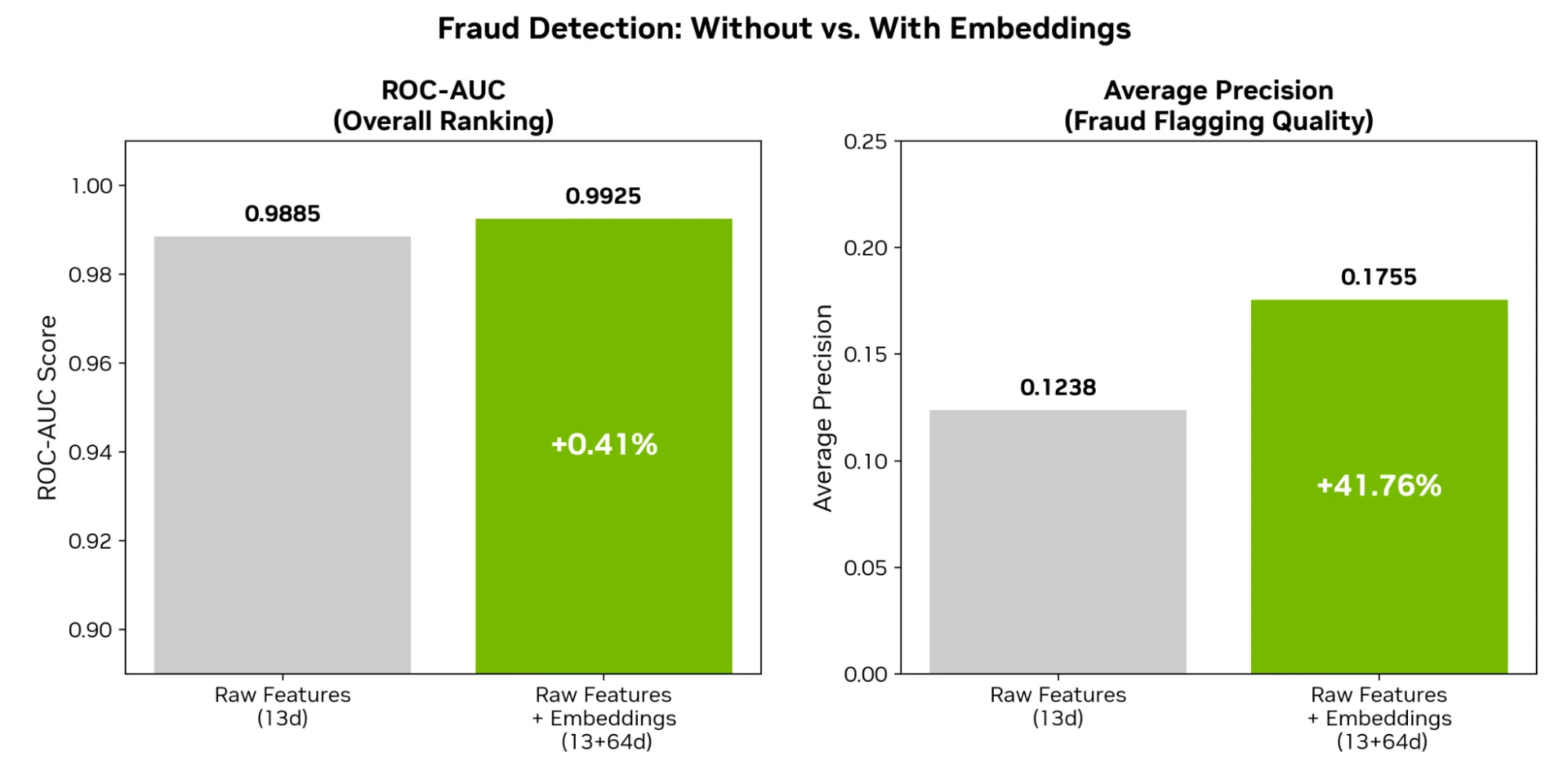
图 4. 三种下游模型的测试 ROC-AUC 和测试 AP 并排对比。组合模型 (原始特征+ 基础模型嵌入) 在这两个指标中均获胜
自定义开发者示例
存储库的结构使每个组件都可独立交换:
—分词器: 通过添加或替换步骤,使 src/tokenizer/ 中的工作流适应任何事务模式。每个步骤都是 BaseTokenizer 的一个小子类,因此支持设备指纹、受益国家地区和商家国家地区等新字段只是一个简短的补充。
—模型架构: 在训练 YAML 中编辑 model._target_ 和 model.config._target_,使其指向任何兼容 HuggingFace 的解码器。使用 NeMo 训练工作流的其余部分 (数据加载器、FSDP2、检查点、评估) 保持不变。
—下游任务: 将 XGBoost 替换为任何使用固定长度特征向量的模型。客户流失预测、客户细分、生命周期价值回归、次优行动排名和信用评分都符合相同的嵌入加头模式。
开发者示例旨在扩展到欺诈以外的标签,展示基础功能。将上述第 5 步中的 Is Fraud? 替换为与主干编码的用户历史记录保持一致的任何事件标签。
开始使用
您现在拥有了从原始事务日志到预训练基础模型的参考路径,该路径可增强下游分类器,并借助 NVIDIA 实现端到端加速。这三个组件 (自定义分词器、Transformer 解码器主干和嵌入驱动的 XGBoost 头) 共同提供了接近 TabFormer 欺诈基准行业标准基准 50% 的 AP 提升。
访问 build.nvidia.com,通过 NVIDIA Launchable 在 GPU 加速环境中部署 Notebook,或通过 GitHub 资源库 在您自己的环境中部署 Notebook。