
全球各地的电信公司正基于主权AI工厂基于NVIDIA云合作伙伴(NCP)参考架构,建设,使政府、企业和初创公司能够以适当的控制力、信任度和性能,访问本国或本地区的AI基础设施。然而,仅有基础设施还不足以提供高利润、可投入生产的商用AI服务。
模型规模和推理工作负载持续增长,推动了每个请求的词元数量不断增加,而新一代加速计算技术则持续降低每个词元的处理成本。综合这些趋势,将AI经济提升到更高层次——从销售GPU小时转向按词元计量和计费的AI服务——变得愈发有价值,特别是推动 AI经济 更高层次的发展。
同时,企业不想管理集群、运行时或模型权重。他们希望生产就绪型应用和模型 API 具有可预测的性能,按词元消耗量衡量,并由与 AI 原生指标相关联的服务级别协议 (SLA) 提供支持,例如每秒词元、从“第一”到“第一”词元 (TTFT) 的时间以及端到端查询延迟。
本文回顾了从每小时 GPU 计算的基础设施到词元计量 AI 服务的过程,并概述了电信公司从基础设施所有者发展为“词元工厂”所需的技术构建块,这些工厂具有透明、基于词元* 的经济性,企业可以轻松采用,而无需自行运行底层基础设施。
构建电信 AI 云堆栈
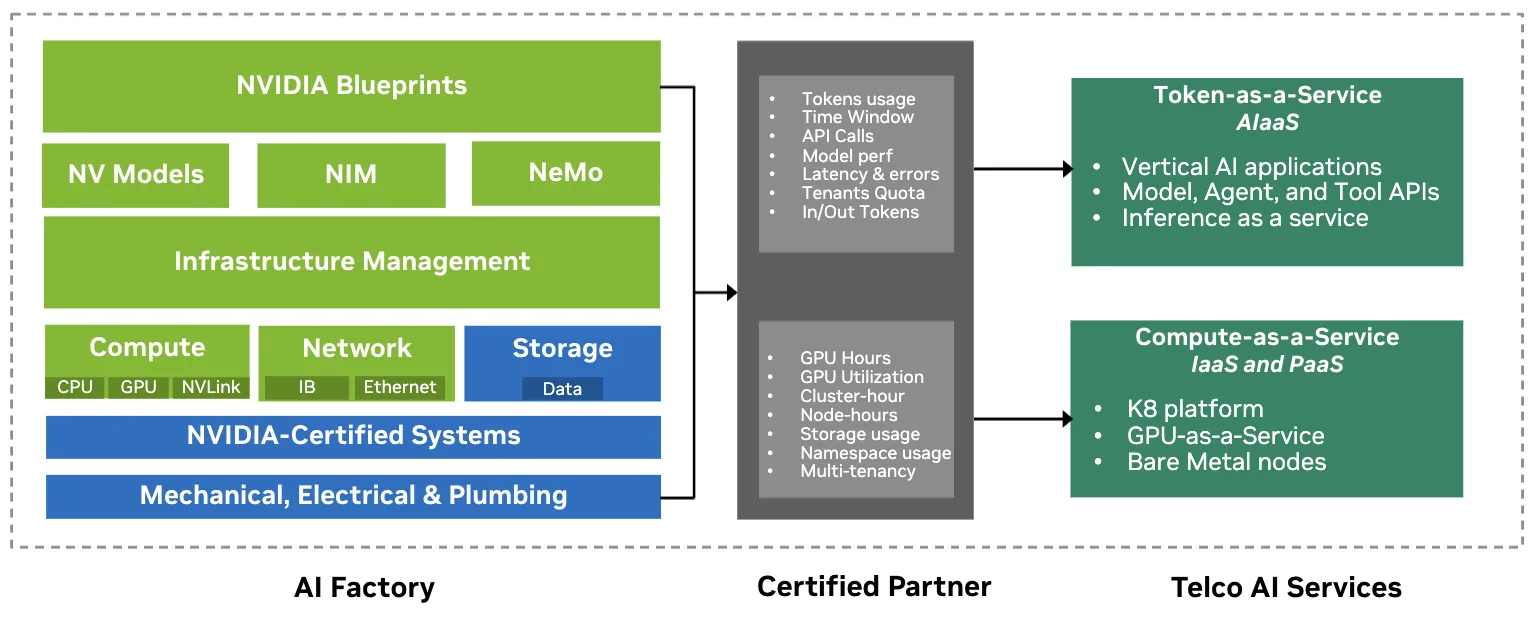
AI 可以比作一个五层蛋糕——能源、芯片、基础设施、模型和应用。电信主权 AI 工厂建立在能源层和芯片层之上,并锚定于基础设施层,提供 NVIDIA® 加速计算、网络和存储能力,可安全托管模型与应用。如同 5 层蛋糕 一样,电信主权 AI 工厂为基础设施层提供了锚点,并在其上搭建了模型和应用层。
电信 AI 工厂从 NVIDIA® 认证基础设施和软件合作伙伴选择开始,这些合作伙伴定义了平台的经济和监管态势。此基础层将计算成本设置为“一项”服务,强制实施数据的驻留位置,并控制哪些租户可以在共享环境中运行哪些工作负载。
在实践中,它将原始 GPU 容量转化为可作为服务公开的安全、多租户计算,并且随着电信公司在堆栈中向上移动 (从计算作为一项服务到词元作为一项服务) ,其成本结构和足迹为每个词元的成本设定了基准,其中大部分长期经济优势位于其中。
计算即服务:基础架构和平台
计算即服务 (CaaS) 是电信公司通过 5 层以上的能源、芯片和基础设施层获利的方式,提供 NVIDIA® 认证系统、CPU、GPU、NVLink、高速 InfiniBand 或以太网,以及客户按小时租用的 GPU/ 基础设施存储即服务 (IaaS) ,这与传统云实例类似。
最重要的是,基于 Kubernetes™ 的平台层将此原始容量转换为具有多租户集群、命名空间和 GPU 调度的托管环境,因此开发者可以部署容器和推理运行时,同时主要按 GPU = 小时、节点 = 小时和存储计费。
此等级对于灵活性、可控性和主权至关重要,但它能使业务始终以 GPU* 每小时运行一次的模型为基础。当电信公司在其上添加词元™ 计量模型和应用,并开始销售 AI 输出 (而不仅仅是基础设施时间) 时,就会发生真正的经济转变。
词元服务:创建和使用词元计量服务
词元™ 即“服务” (TaaS) 可将电信公司提升至 5 层以上的模型和应用层,其中的价值以词元、API 调用和工作流 (而非 GPU 时间) 衡量。在这一层中,AI 工厂的 GPU 容量被打包到以这些相同的单位进行测量、计费和管理的产品中,收入不再受 GPU 可以租用的时间限制,而是受堆栈可以在给定价格和 SLA 下提供服务的词元数量的限制。
电信公司通常从集中式词元计量服务组合开始,这些服务由 NVIDIA Nemotron、NVIDIA NIM 等开源模型和蓝图提供支持,例如:
- 垂直 AI 应用 (例如,根据当地语言和法规定制的客户服务助手或知识助手)
- 适用于文本、视觉、语音和智能体的模型和工具 API
- 推理作为服务端点,适用于微调和领域特定的模型
客户通过 API 集成这些服务,并按照与其业务使用 AI ( 词元、请求或工作流) 的方式 (而非不透明的基础设施指标) 进行支付。服务水平协议 (SLA) 也随之改变:企业不再关注特定服务器的正常运行时间,而是关注模型或应用程序级别的延迟、可靠性和响应质量。
为了简化此层的服务创建和使用,许多电信公司与 NVIDIA 认证软件合作伙伴合作开发 AI 开发者工作室和 AI 市场。
AI 开发者工作室是设计、调整和运行这些词元® 计量服务的地方。数据科学家和开发者使用 NVIDIA NeMo 微调基础模型,将其部署为基于 NIM™ 的安全端点,并将其连接到检索工作流或智能体工作流。在 AI 工作室中,他们可以从精选目录中选择模型,使用自己的企业数据对其进行微调,以提高准确性和相关性,并将其作为可重复使用的 AI 资产 (模型、智能体和蓝图) 发布,供开发者在不接触底层基础设施的情况下重复使用。
然后,AI 市场成为将这些资产转化为产品的店面。企业和应用程序所有者浏览 copilot、检索增强生成 (RAG) 应用程序、模型 SKU 和独立软件供应商 (ISV) 解决方案的目录,然后只需单击几下即可订阅和部署它们。
该平台在后台提供输入和输出词元、API 调用或工作流执行中的推理端点和仪表使用,自动执行配额、速率限制和 SLA。
AI 开发者工作室和 AI Marketplace 共同助力的 TaaS 将电信 AI 工厂从 GPU 池转变为企业可以开箱即用的主权词元™ 计量 AI 产品组合。
词元级计量和计费
为了将这些功能转化为产品,电信公司需要一个计量和计费层,将词元视为第一信号,并将其与性能、治理和基础设施效率相连接。
| KPI 组 | 示例 |
|---|---|
| 词元用法 | 每个租户、模型和端点的词元;输入与输出;每小时/ 每天/ 每月总计 |
| 性能 | QPS、请求数量、p50 – p99 延迟、吞吐量 (以词元 s 为单位) |
| 可靠性 | 与词元体积相关的错误率 |
| 治理 | 每租户配额、速率限制、访问/ 审核、策略信号 |
| 经济学 | 每个 GPU 的词元 = 小时,每个 GPU 类型,词元每美元 |
借助这些指标,电信公司可以提供按百万词元定价的套餐,在租户之间强制使用,并根据实际每词元成本数据选择合适的 NVIDIA 平台 SKU 和服务价格点。
随着时间的推移,这种词元+ 级别的可见性将 AI 工厂转变为真正的词元工厂,其中堆栈中的每一次改进都以更低的词元成本和更高、更可预测的毛利率来衡量。
将 AI 基础设施变现为词元工厂
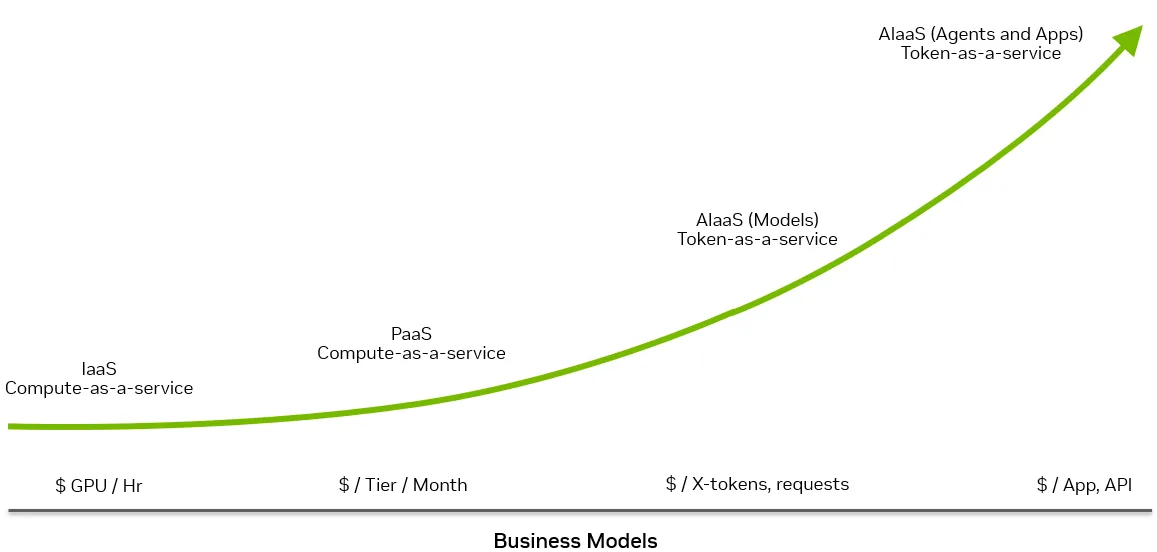
在 GPU 每小时租用数模型中,收入上限取决于可以租用 GPU 的小时数和租用费率。您可以调整利用率和定价,但价值单位仍然是“每 GPU 每小时的美元数”,因此硬件和软件的改进主要表现为降低每小时价格的压力,而不是提高利润。
在词元作为服务模型中,相同的 GPU 通过优化的堆栈可以生成多少高质量的词元来获利,定价为每百万词元和 SLA。
从这个角度来看,AI 工厂变成了词元工厂。堆栈的每项改进 (更好的批处理、更智能的路由和调度、更高效的模型、更快的网络和消除 I/ O 瓶颈的存储) 都可以提高每秒词元的速度,或降低% 词元的成本。
收入随着词元吞吐量和每词元的价格增长而增长,而利润会随着 NVIDIA 平台的每一代更新和软件的每一次优化而提高,而不仅仅是提高每小时的租用费率。
实际示例:每小时 GPU 数与 TaaS 的对比
下面图 3 中的示例使用简化的假设来展示当您从 GPU 每小时转变为 TaaS 时,经济性会发生怎样的变化。这些数字只是说明性数据,并非规范性定价。
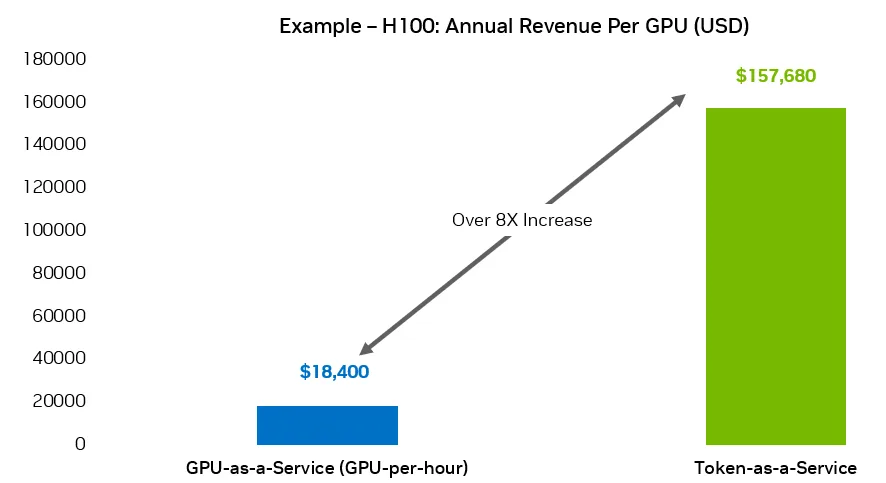
GPU小时计费模型:假设租用H100+级别实例的价格约为每小时3美元。在年均70%利用率的情况下,每块GPU的年收入约为18,400美元。在此模型中,您主要调整的是利用率和每小时费率——本质上仍是销售GPU的使用时间,而非AI输出结果。
TaaS 模型:假设你运行的是一个经过吞吐量优化的中等规模模型,在单个 H100 上每小时可稳定处理 3000 万个可计费词元。若每百万词元收费 1 美元,则该 GPU 每小时的词元收入潜力为 30 美元。当“词元 = active”利用率达到 60% 时,每小时实际词元收入约为 18 美元,相当于每个 GPU 每年收入约 157680 美元。
新一代GPU进一步提升了这一效果。与上一代产品相比,NVIDIA GB200 NVL72在每秒处理的词元数以及每百万词元成本方面实现了数量级的改进。领先的推理服务提供商报告称,当将Blackwell与优化的堆栈结合使用时,实际工作负载的成本比按词元计费低10倍。
当您在词元层 (而非 GPU+ 小时) 获利时,这些节省是最容易实现的,因为更高的每秒词元% 和更低的每词元成本* 直接转化为词元+ 计量服务更好的单位经济效益。
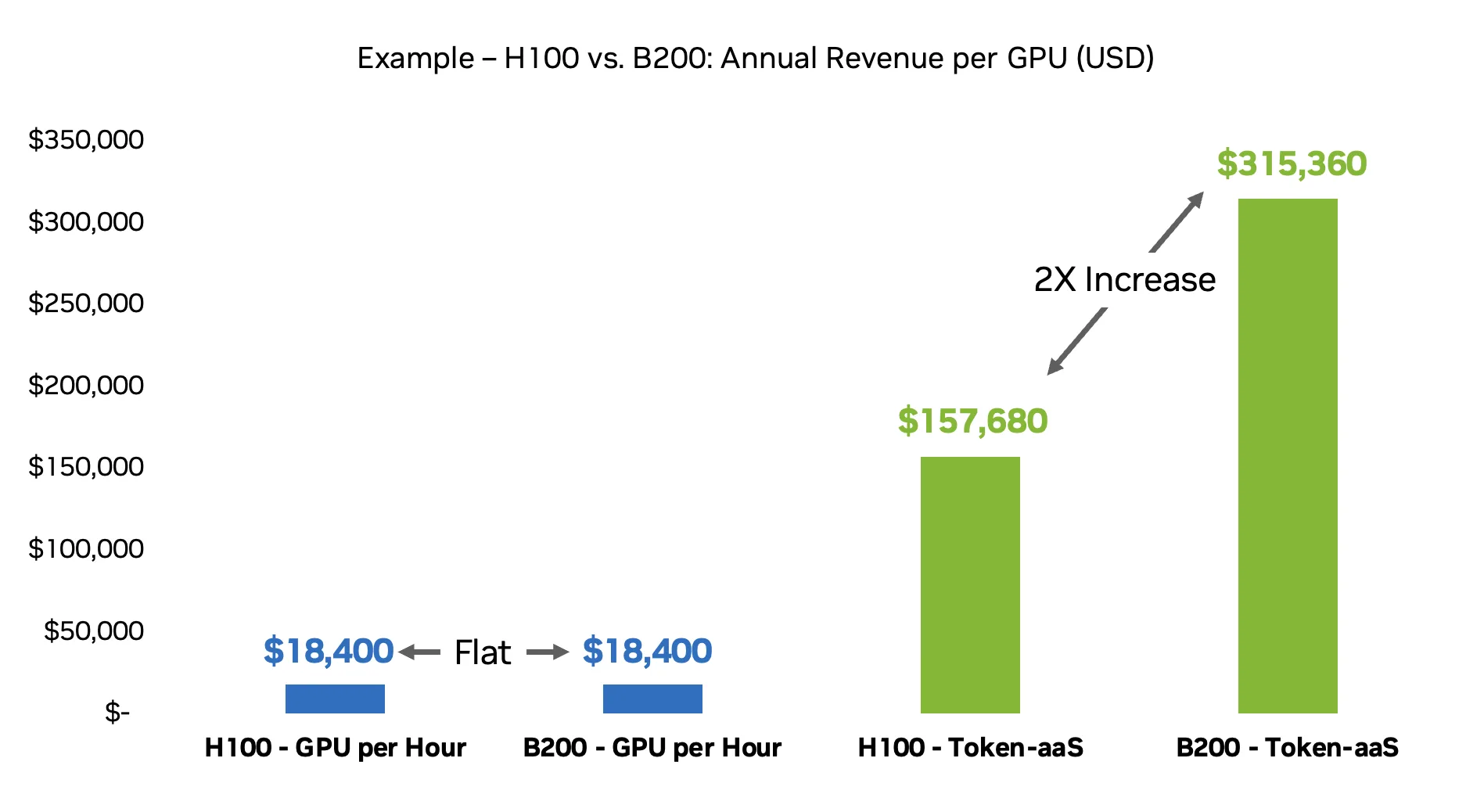
例如,如果 B200+ 级 GPU 将有效的词元吞吐量提高一倍,从每小时 3000 万到 6000 万计费词元,价格与每 100 万词元 1 美元和 60% 词元* 活跃利用率相同,则每个 GPU 的年度词元服务收入将从 157680 美元增加到大约 315360 美元。
在 GPU 每小时模型中,这种额外的吞吐量不会显示为额外收入,但在词元中作为服务模型,它直接转化为更高的收入,在 GPU 占用相同的情况下,随着词元成本的提高,利润也会增加。
电信公司的发展方向
对于已投资 NVIDIA® 驱动的主权 AI 工厂的电信公司而言,下一步是快速提升堆栈 (从 AI 基础设施到 AI 服务) ,并使其业务模式与 AI 词元经济保持一致。
这意味着不仅要超越GPU集群,还需与NVIDIA®认证的软件供应商合作,构建AI云堆栈,能够编排GPU资源、实施多租户策略,并将词元™级别的使用情况与计费、SLA及治理机制相连接。例如,像 Rafay 这样的合作伙伴已协助电信公司在主权基础设施上推出基于词元+计量的AI服务,初步证明了该方法能够切实满足企业实际需求和应用场景。
此后,电信公司可以推出词元™ 计量 AI 服务:团队使用 NVIDIA NIM 和 NeMo 构建和调整模型的 AI 工作室、以 SKU 形式提供这些模型和应用的市场,以及企业可按% 词元或% 工作流使用的 API。
通过将词元视为核心经济单位,并以 NVIDIA 在词元 = 每秒、词元 = 每瓦和词元成本方面的进步为后盾,电信公司可以从连接和基础设施提供商发展为主权 AI 服务提供商,其收入和利润会随着词元工厂的发展而增长。
了解电信运营商如何将主权 AI 基础设施转化为实际收入,并对其所在国家 地区产生影响。