
NVIDIA 对 MLPerf Training v6.0 进行了彻底的测试,这是 MLCommons 联盟开发的最新版行业标准 AI 训练基准测试。NVIDIA 实现了最快的大规模训练速度,并且在每个基准测试中基于每个加速器进行标准化时,也提供了更高的性能。它也是唯一一个提交每次测试的平台。
MLCommons 在本轮测试中引入了新的预训练基准测试,旨在反映 AI 模型的最新趋势,包括 DeepSeek-V3 和 GPT-OSS-20B,前者是一个包含 671B 参数的大规模专家混合 (MoE) 模型,也是热门 DeepSeek-R1 推理模型的基础。
NVIDIA 平台是唯一针对这两种新工作负载提交结果的平台,NVIDIA GB300 NVL72 系统通过优化的 NVIDIA 软件堆栈设定了性能标准,并且采用了使用 NVIDIA NVLink 和 NVIDIA NVLink Switch 将 72 个 NVIDIA Blackwell Ultra GPU 和 36 个 NVIDIA Grace CPU 作为一个整体连接的设计。
在整个横向扩展网络中实现前所未有的规模和吞吐量
训练先进的模型需要大规模的基础设施,并且能够跨数千个互联处理器高效执行工作负载。在本轮的几个参赛作品中,NVIDIA 云服务提供商合作伙伴扩展到了 8192 个 Blackwell GPU,它们在不同的云数据中心协同工作。这些提交的结果证明了 Blackwell 平台在生产级超大规模数据中心机群中的现实世界鲁棒性,表明了在这些不同的集群环境中的强大扩展趋势。
要从每次训练迭代中提取这种规模的最大效率,需要依靠 NVIDIA Spectrum-X 以太网和 NVIDIA Quantum InfiniBand 等横向扩展网络平台,而不仅仅是单个 NVLink 域。MoE 模型中的专家并行会生成低的突发流,当大型流在共享链路上发生碰撞时,这种模式通常会降低静态等价多路径 (ECMP) 哈希下的有效带宽。
为了解决这个问题,Spectrum-X 以太网的高级自适应路由根据实时链路负载在所有可用路径上逐个数据包分发流量数据包,使有效带宽保持在接近网络理论容量的水平,同时接收端 ConnectX SuperNIC 处理乱序配送。
此外,当热门专家同时从多个发送者中提取流量时,Spectrum-X 拥塞控制会使用实时遥测技术尽早检测到生成的 incast,并在缓冲区溢出之前调整发送者的速度。这样可以平衡尾部延迟,因此 all-to-all 通信始终隐藏在计算背后,而不是出现在主执行路径上。
通过将集群编排与网络结构效率相结合,在最具挑战性的基准测试中创造了新的训练时间记录,总结如下:
| 基准测试工作负载 | GPU 平台 | 集群规模 | 训练时间 |
| DeepSeek-V3 671B ( MoE) | GB300 NVL72 | 8192 个 GPU | 2.02 分钟 |
| GPT-OSS 20B ( MoE) | GB300 NVL72 | 512 个 GPU | 7.43 分钟 |
| Llama 3.1 405B | GB200 NVL72 | 8192 个 GPU | 7.07 分钟 |
| Llama 3.1 8B | GB200 NVL72 | 1024 个 GPU | 4.46 分钟 |
| Llama 2 70B LoRA | GB300 NVL72 | 512 个 GPU | 0.4 分钟 |
| FLUX.1 | GB300 NVL72 | 512 个 GPU | 17.1 分钟 |
| DLRM-dcnv2 | GB300 NVL72 | 64 块 GPU | 0.67 分钟 |
MLPerf Training v6.0 结果于 2026 年 6 月 16 日从 www.mlcommons.org 的以下条目中检索到:6.0-0005、6.0-0102、6.0-0001、6.0-0015、6.0-0102、6.0-0101 和 6.0-0062。MLPerf 名称和徽标均为 MLCommons 协会在美国和其他国家 地区的商标。保留所有权利。严禁未经授权使用。详情请参见 www.mlcommons.org。
软件创新引擎
硬件功能取决于驱动它们的软件。为了更大限度地提高 DeepSeek-V3 等复杂 MoE 模型的性能,NVIDIA 在本轮 MLPerf 训练中部署了几项前沿软件优化:
1. 用于无 token-drop 的 MoE 的全迭代 CUDA 计算图
从历史上看,由于动态路由行为强制进行连续的 CPU-GPU 同步,无标记的 MoE 架构很难在 CUDA 计算图中完全运行。在 MLPerf Training 6.0 中,NVIDIA 首次为这些 MoE 实现了全迭代 CUDA 计算图。为此,我们克服了两个主要障碍。首先,量化器、分组 GEMM 和 token 分配器等专家模块运算符过渡到无同步模式。在此配置中,输入形状直接衍生自 GPU 值,无需主机端协调。其次,通过 分页存储 在没有主机参与的情况下管理设备内存。该技术可对预先分配的 GPU 显存进行精细管理,确保进程与 CUDA 计算图完全兼容。同时,NVIDIA 实现了 全迭代 CUDA 计算图,这是为这些 MoE 首次实现的。
通过重写关键执行路径以消除所有 CPU-GPU 同步接触点,整个迭代工作负载完全卸载到 GPU。这可将 CPU 从关键路径中移除,并消除因主机执行差异而产生的开销,否则,在扩展到包含 2000 多个 GPU 的集群时,可能会造成级联式开销延迟。
2. CuTe DSL 和内核融合
为了实现内存带宽受限层与分组 GEMM 运算的融合,以及 CUDA 计算图所需的无同步执行,NVIDIA 利用 CuTe DSL 实现了高级内核融合。这使开发者能够直接在硬件层结合数学运算和内存处理运算,将数据保持在寄存器的本地,并避免昂贵的全局内存往返行程。此外,对动态图块调度的支持隐藏了 GEMM 运算背后未融合的读取和写入,从而实现了与通信内核的高效重叠。
CuTe DSL 还支持实现内核,这些内核可以直接从 GPU 显存中使用形状参数,而这些参数事先由另一个 GPU 内核计算。这种能力消除了对 CPU-GPU 同步的需求,即使是在运行时之前还不知道的动态形状也是如此,从而使 CPU 完全摆脱了无标记 MoE 的关键路径。与启用 CUDA 计算图同时,这些 高级融合技术 可在 Deepseek-v3 上提供超过 8% 的端到端优势,并在 GPT-OSS 上实现 93% 的端到端加速。
3. MXFP8 注意力块
传统上,MoE 训练工作负载使用 16 位精度进行注意力计算。本轮开发的 MXFP8 注意力方案旨在提高性能,而不会影响模型质量。这为 DeepSeekv3 基准测试提供了端到端加速,同时保留了注意力运算所需的标准数学运算。此方法将注意力块中所有批量矩阵乘法运算的输入张量保持在 8 位精度,与 16 位浮点数据路径相比,可在硬件上更快地执行 FP8 数学运算。此内核可通过 Transformer 引擎库在 cuDNN 中获取。
4. 路由器和混合 EP 优化
MoE 路由器用于将 token 动态分配给专门的专家层,使其性能成为集群范围内训练瓶颈的重要因素。多个元素级内核在路由器中融合,包括 top-k 和分数计算,以提高性能。为了更大限度地提高硬件利用率,这些内核从 FP64 过渡到 FP32 数学运算。这一优化将内核速度提高了 5 倍。此外,在 HybridEP 中融合了多个元素级元数据处理内核,并对关键的置换/ 非置换内核进行了专门的性能调优。总体而言,这些优化带来了 5% 的端到端性能提升。
5. 1F1B 多对多重叠优化
之前,我们已在 Megatron-Core 中引入专用的 1F1B ( One Forward,One Backward) all-to-all (A2A) 重叠方案,以将 MoE 通信隐藏在批量级别的计算背后。在本轮 MLPerf 测试中,该方案的执行效率得到了显著提高。虽然 1F1B 调度最初引入了显著的 CPU 开销,但在 CUDA Graph 中捕获完整迭代成功地消除了主机侧的这一瓶颈。通过优先处理通信流、采用动态调度的 CuTe DSL 内核以及为新的 cuteDSL GEMM 启用延迟权重梯度 (wgrad) 支持,性能得到进一步提升。在稳定状态下,这些调整实现了近 100% 的 A2A 通信重叠,总体上实现了 8% 的性能提升。
6. 尽可能减少工作流阶段之间的不平衡
随着单个计算内核的运行速度加快,工作流并行阶段之间的底层失衡变得更加明显。NVIDIA 优化了这些工作流并行阶段的布局和平衡,最大限度地减少了结构空闲 (“气泡时间”)。
工作流失衡是工作流并行 (PP) 效率的主要瓶颈。对于 DeepSeek-V3,该模型使用混合层设置,其中前端有三个密集层,最后是多令牌预测 (MTP) 加 logits GEMM,并带有交叉。为解决此问题,我们利用 Megatron-Core 灵活的工作流布局支持仔细平衡各个阶段,同时对 logit 投影 GEMM 采用了 MXFP8 精度,以减少其在关键路径上的执行时间。将 MXFP8 用于 logit 投影 GEMM 不会影响基准测试的数值稳定性。这些调整成功地将工作流失衡降低到 1% 以下,转化为 4% 的 E2E 性能节省。
连续全栈协同设计:所有部分的总和
虽然标准化基准测试会捕获时间点性能指标,但开发者实际价值的一个主要驱动因素是软件优化的持续轨迹。在过去三个月中,硬件和软件工程团队之间的密切合作为 NVIDIA 平台开启了重要的优化里程碑。
这种快速的创新步伐覆盖了整个 NVIDIA 软件栈。上述创新成果展示了多个基础 CUDA-X 库、框架和 API (包括 cuDNN、Transformer 引擎、CuTe DSL、Megatron Core 和 cuBLAS) 如何设计并行性能增强功能,而不是依赖单个孤立层中的优化。Megatron Bridge 是集成这些跨栈改进的中心封装层,可在统一的生态系统中立即提供给开发者。
为了使用最新的 NVIDIA NeMo 容器 26.06 版本证明这一点,NVIDIA Blackwell Ultra GB300 在 DeepSeek-V3 上的训练性能提高了 1.3 倍,从 1298 TFLOPS/ GPU 提升到 1648 TFLOPS/ GPU ( 6338 token/ 秒/ GPU) 。这种在短短三个月内实现的性能提升是全栈协同设计的直接成果,并且无需更改底层芯片,即可系统地消除跨通信协议、路由层和计算内核的微瓶颈。其中,训练性能的提升是关键。
这种持续优化轨迹可以减少系统开销,并更大限度地提高 GPU 用于完成有用工作的时间百分比,从而直接提升 NVIDIA Goodput 的性能。因此,基础设施运营商不仅获得了较高的理论峰值能力,还获得了一个成熟的平台,可将这些原始 FLOPS 转换为持续、高效的训练过程。这使得现有的基础设施部署能够随着软件生态系统的成熟而立即获得训练效率方面的好处。
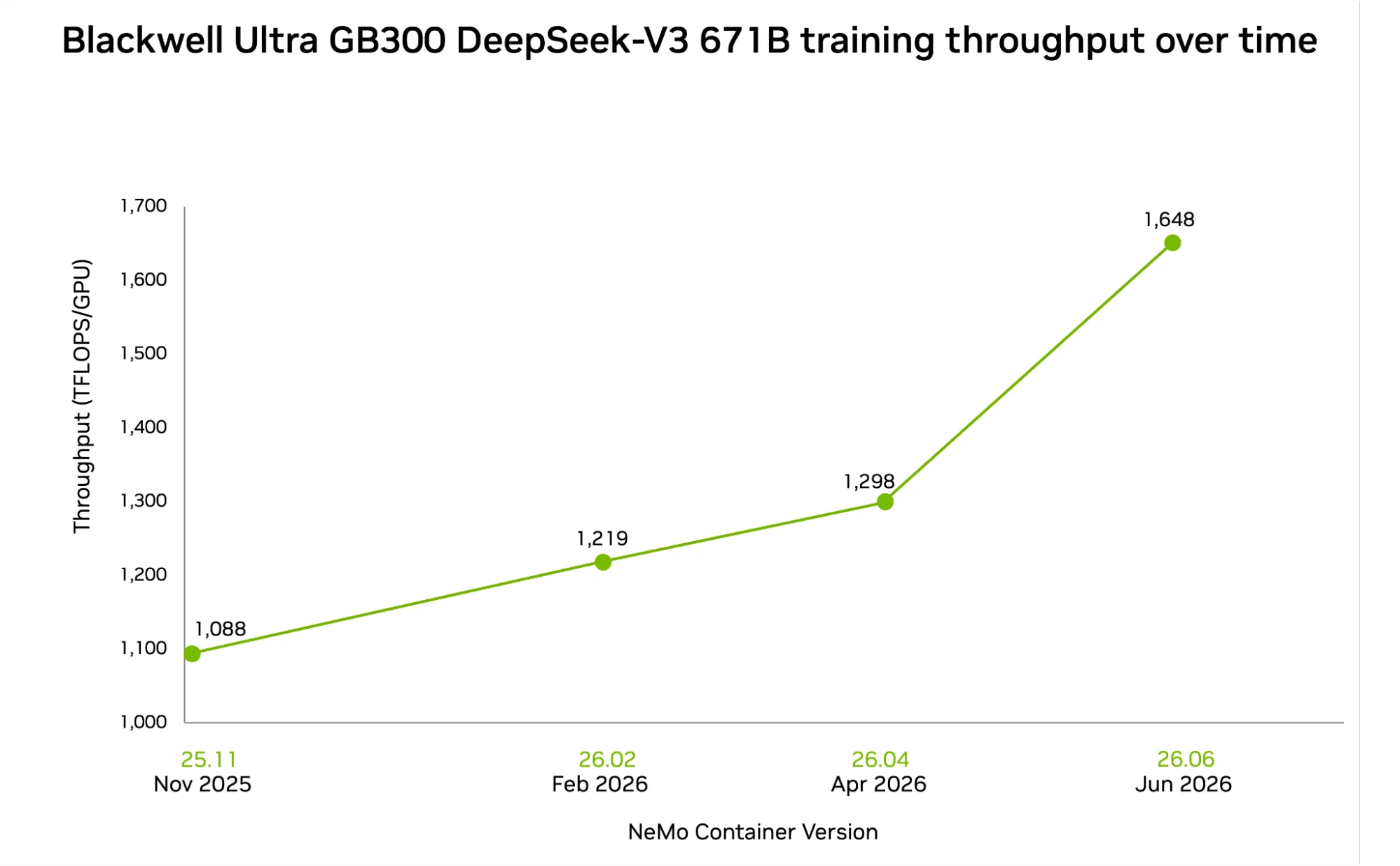
平台比较:Blackwell Ultra GB300 与 GB200
除了软件方面的提升外,Blackwell 系列的配置对比还说明了细微的硬件调整如何补充全栈优化。如下图 2 所示,在密集基础模型和复杂 MoE 系统中,Blackwell Ultra GB300 的训练性能比基准 Blackwell GB200 显著提升。
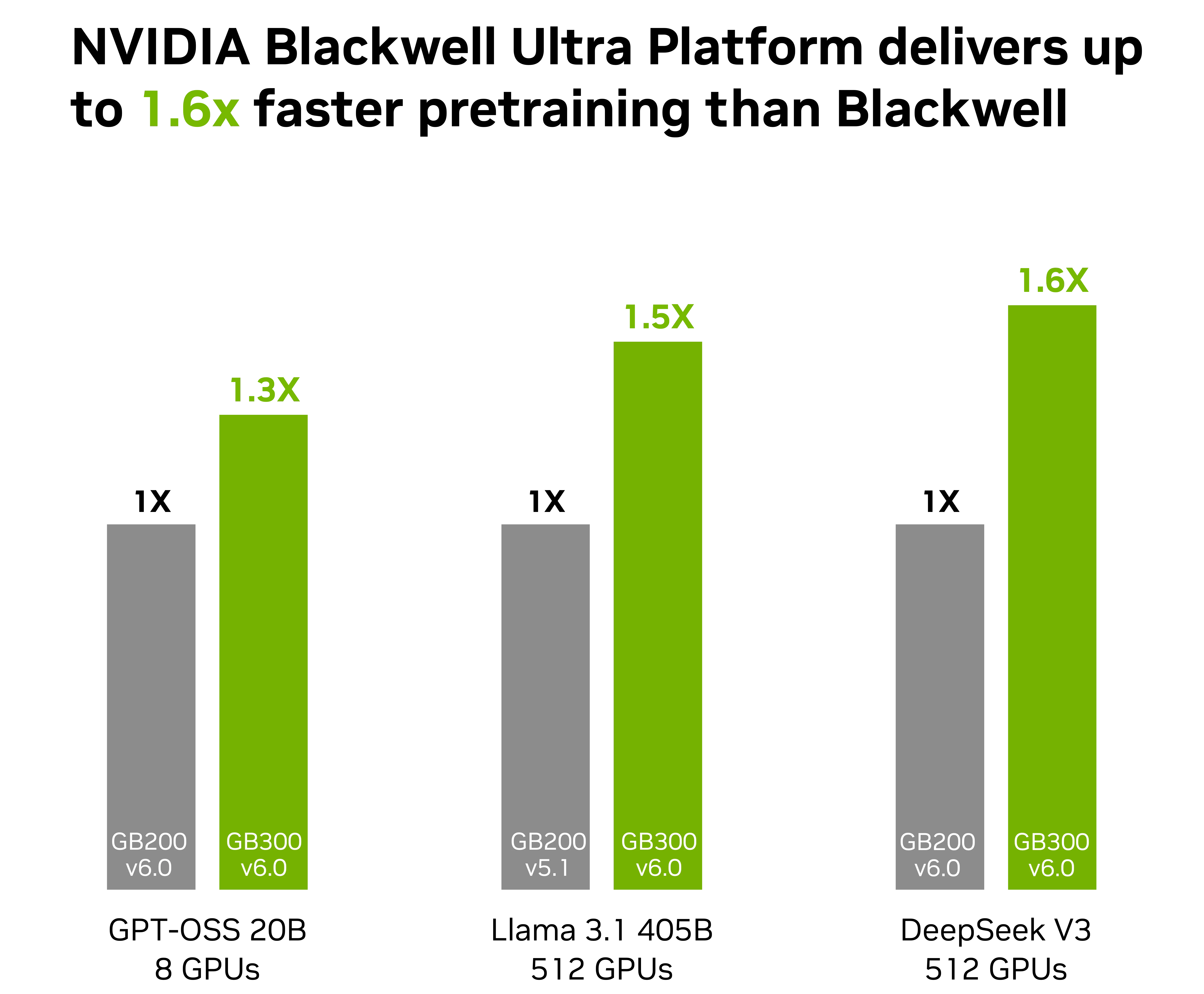
MLPerf Training v5.1 和 v6.0,封闭组。条目结果:6.0-0022、6.0-0102、6.0-0017、6.0-0078、5.1-0072、6.0-0013、5.1-0067 和 6.0-0031。MLPerf 名称和徽标均为 MLCommons 协会在美国和其他国家 地区的注册商标和非注册商标。保留所有权利。严禁未经授权使用。详情请参见www.mlcommons.org。
这种加速得益于两个主要优势:更大的内存容量和更大的功耗预算。在大规模训练期间,深度 MoE 架构受内存限制很大。
GB300 的扩展显存可容纳全迭代 CUDA 计算图带来的额外显存开销,而无需进行次优配置或层重新计算。此外,内存容量的增加使开发者能够利用较小的模型并行通信组。通过将模型的较大部分保留在芯片本地,该系统可减少跨 GPU 通信的等待时间,从而直接转化为更高的操作吞吐量。
MLPerf Training 6.0 中的全栈创新和规模
MLPerf Training 6.0 的结果稳固地将 NVIDIA 的全栈方法确立为加速整个行业复杂生成式 AI 工作负载的权威标准。该平台在本轮测试中横扫并赢得每项基准测试,在训练时间指标方面展现出无与伦比的执行速度。无论是训练超密集的基础模型,还是处理大规模 MoE 架构中复杂的 token 路由机制,NVIDIA 都能全面提供出色的性能。
快速的软件创新、持续的极致协同设计以及 NVIDIA Goodput 的更大限度效率推动了这些基准测试的成功。通过在 Megatron Bridge、cuDNN 和 Transformer 引擎中实施的工程突破,包括全迭代 CUDA 计算图、CuTe DSL 内核融合以及通信和工作流优化,NVIDIA 客户定期直接从软件层获得巨大的性能提升。这种快速的优化速度使开发者能够随着软件生态系统的成熟,从其现有基础设施投资中立即获得训练效率红利。
最终,企业就绪程度的真正指标是在最大部署规模下提供的性能。NVIDIA 平台成功展示了可在生产就绪型云架构上同时运行的 8192 个活动 GPU 的强大可扩展性。这种经过验证的编排大规模训练集群的能力可确保企业能够可靠地将标准的数月训练周期压缩到几分钟或几小时内,从而大幅缩短新一代 AI 突破的上市时间。