
分布式深度学习依赖于 NVIDIA 集合通信库(NCCL) 实现快速可靠的 GPU 间通信。当训练速度变慢时,往往难以判断问题根源及后续应对措施。性能瓶颈可能来自计算、通信、特定节点或底层硬件。
NVIDIA NCCL Inspector 通过提供轻量级且持续的 NCCL 通信性能报告来加速分流。它跟踪每个秩的操作类型、大小和带宽,并且借助这一最新增强功能,可以尽可能减少开销来促进实时分析。
它还有助于确定最优的训练方法。上一篇文章介绍了 NCCL Inspector 的离线模式。尽管细粒度分析仍是深入研究数据的常用手段,本文将重点介绍一项新功能——实时监控。通过将 NCCL Inspector 与 Prometheus Exporter 集成,现在用户可以直接在其基础设施的控制面板中实现实时、基于时间序列的可视化监控。
NCCL Inspector 部署架构
NCCL 2.30 引入了 Prometheus 模式,显著增强了 AI 工作负载中 NCCL 的实时性能监控能力。NCCL Inspector 提供两种工作模式,如图 1 和图 2 所示。
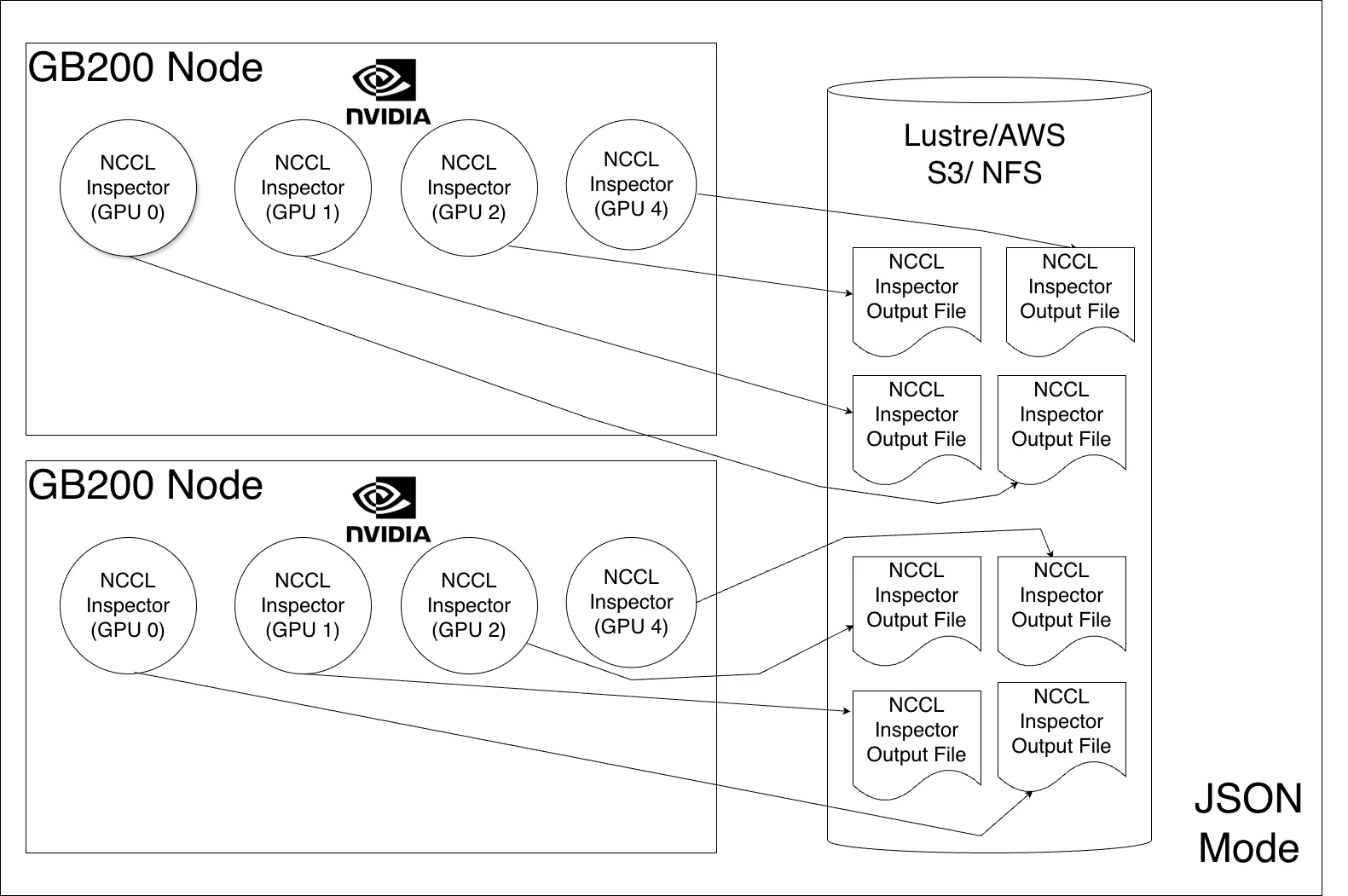
JSON 模式在数据采集和数据分析阶段运行。首先,数据收集阶段根据每个秩生成性能指标,并将其单独存储在 JSON 文件中,通常存储在共享存储上。然后,在数据分析阶段处理数据。由于处理并非实时完成,因此此方法被视为离线。
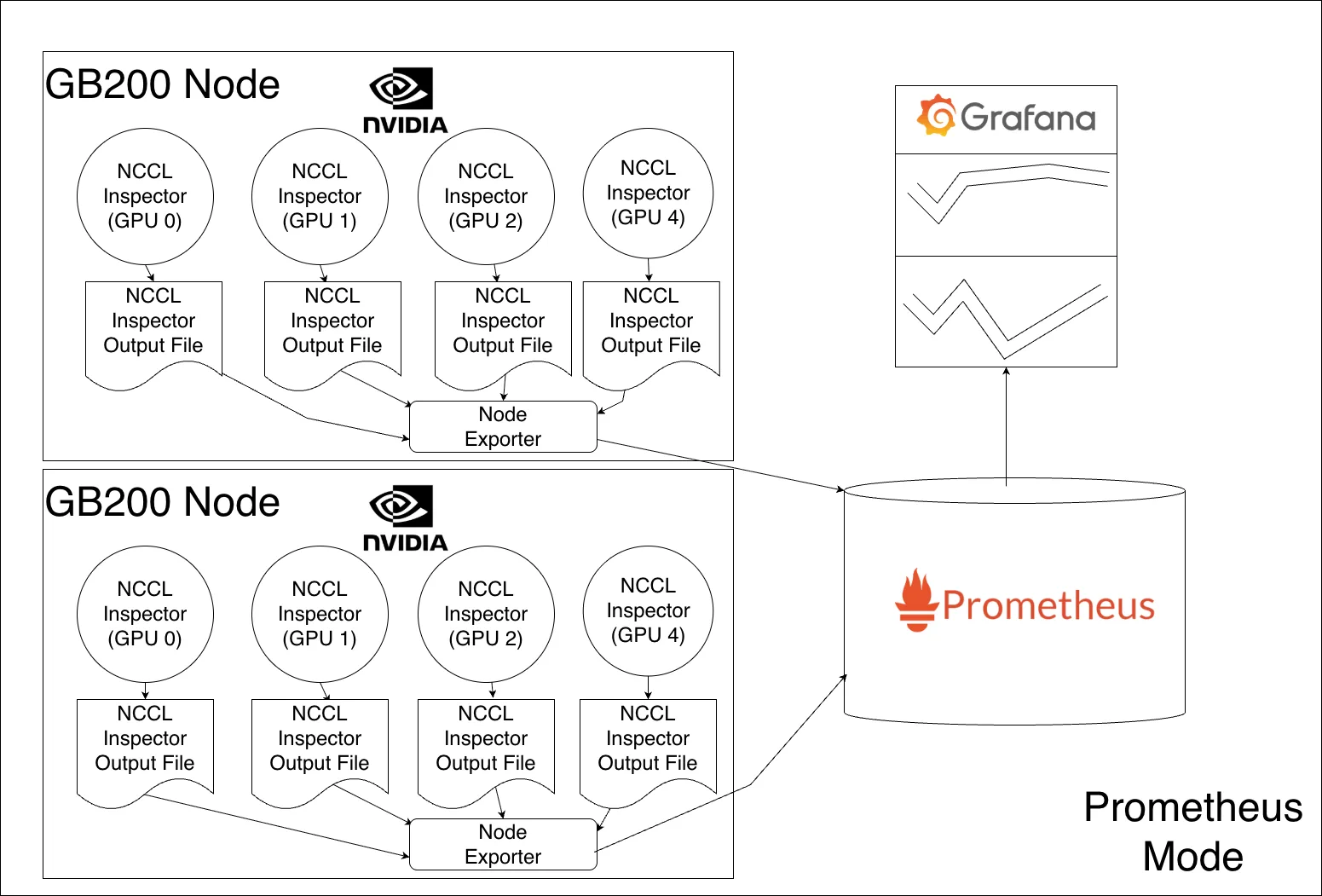
这项新功能将 NCCL Inspector 指标与 Prometheus 集成在一起,将其转换为适合在 Grafana 控制面板中可视化的时间序列数据。Prometheus 模式消除了之前 JSON 模式所需的大量存储需求。节点导出器将这些指标数据移至可扩展的云原生平台 Prometheus。NCCL 作业输出文件被设计为可持续覆盖。节点导出器收集指标后,磁盘上就不再需要这些指标了。
Prometheus Mode 的实验性设置
设置 NCCL Inspector Profiler 插件需要构建插件并设置以下必需的环境变量:
NCCL_PROFILER_PLUGIN=/path/to/nccl/plugins/profiler/inspector/libnccl-profiler-inspector.soNCCL_INSPECTOR_ENABLE=1NCCL_INSPECTOR_DUMP_THREAD_INTERVAL_MICROSECONDS=3000000NCCL_INSPECTOR_PROM_DUMP=1NCCL_INSPECTOR_DUMP_DIR=/path/to/node/exporter/log/location |
应根据所使用的节点导出工具,合理设置和调整转储线程的间隔时间及转储目录。配置完成后,NCCL Inspector 将启动该过程,并将集合性能数据保存至 NCCL_INSPECTOR_DUMP_DIR 目录中。随后,Prometheus Node Exporter 会将这些指标发送至 Prometheus 时间序列数据库。最后,通过 Grafana 将这些时间序列指标渲染为仪表板图表。
运行作业时,这些指标会保存到名为 nccl_inspector_metrics_<uuid_of_the_gpu>.prom 的文件中,文件名包含 GPU 的 UUID,因为 CUDA 设备 ID 在多用户环境中可能存在重复。
NCCL 作业输出文件采用 Prometheus 展示格式。每个指标都使用上下文进行标记,包括 NCCL 版本、Slurm 作业 ID、节点、GPU、通信者名称、节点数、秩数和消息大小。以下是一个示例:
nccl_p2p_bus_bandwidth_gbs{version="v5.1",slurm_job_id="1670760",node="nvl72033-T01",gpu="GPU0",comm_name="unknown",n_nodes="1",nranks="64",p2p_operation="Send",message_size="1-2MB"} 19.1634nccl_p2p_exec_time_microseconds{version="v5.1",slurm_job_id="1670760",node="nvl72033-T01",gpu="GPU0",comm_name="unknown",n_nodes="1",nranks="64",p2p_operation="Send",message_size="1-2MB"} 92.8984nccl_p2p_bus_bandwidth_gbs{version="v5.1",slurm_job_id="1670760",node="nvl72033-T01",gpu="GPU0",comm_name="unknown",n_nodes="1",nranks="64",p2p_operation="Recv",message_size="1-2MB"} 19.2396nccl_p2p_exec_time_microseconds{version="v5.1",slurm_job_id="1670760",node="nvl72033-T01",gpu="GPU0",comm_name="unknown",n_nodes="1",nranks="64",p2p_operation="Recv",message_size="1-2MB"} 92.5781 |
nccl_bus_bandwidth_gbs{version="v5.1",slurm_job_id="1670760",node="nvl72033-T01",gpu="GPU0",comm_name="unknown",n_nodes="4",nranks="32",collective="ReduceScatter",message_size="134-135MB",algo_proto="RING_SIMPLE"} 44.1181nccl_collective_exec_time_microseconds{version="v5.1",slurm_job_id="1670760",node="nvl72033-T01",gpu="GPU0",comm_name="unknown",n_nodes="4",nranks="32",collective="ReduceScatter",message_size="134-135MB",algo_proto="RING_SIMPLE"} 104164 |
将这些指标载入 Prometheus DB 后,下一步是在 Grafana 中进行渲染。
基于时间序列的 Grafana 控制面板
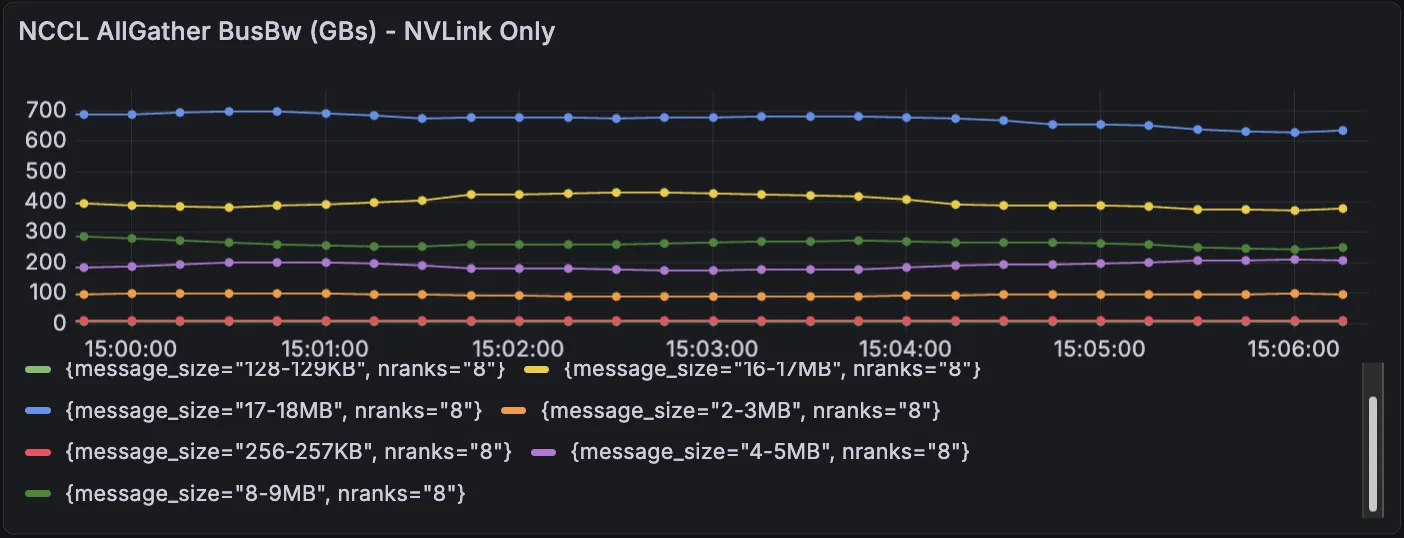
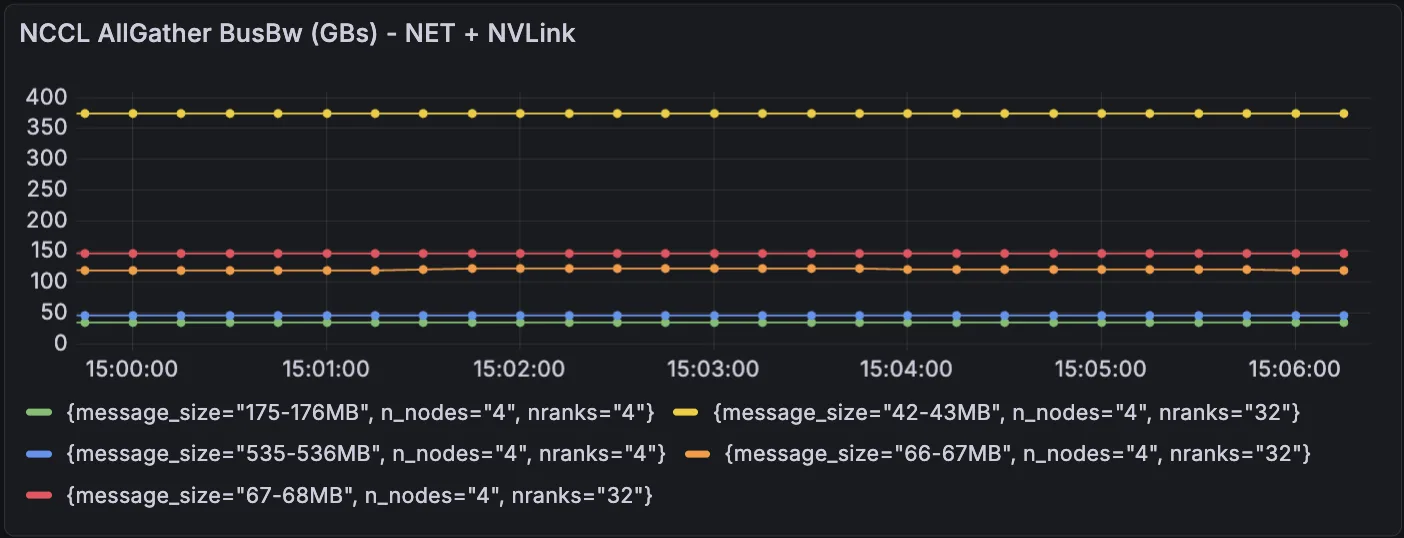
图 3 展示了时间序列仪表板的外观示例,其中使用了 Prometheus 标签,这些标签分为 NVLink 集合仪表板和混合仪表板,即网络+ NVLink 集合:
NCCL 检查器用例
为演示分诊工作流程,这两个用例重点介绍了仪表板如何加速根本原因识别。
实时可观测性
使用实时控制面板,找出长时间运行的 AI 工作负载性能下降的根本原因。通过观察仪表板上的变化,并将作业级别的性能下降与底层 NCCL 或网络层指标关联起来,可以根据异常的来源进行有针对性的分类。该团队开展了一项大型 LLM 预训练工作,以展示这一策略。
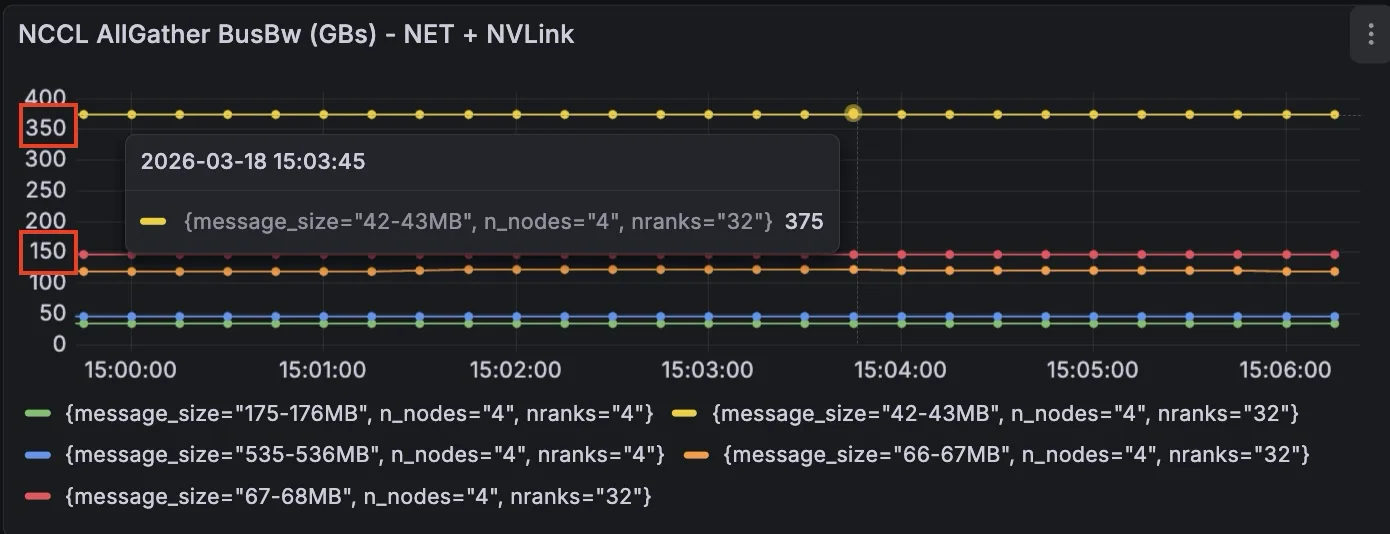
时间轴 A:正常工作流程
图5展示了其中一个实验中混合网络+NVLink集群的AllGather总线带宽。该AI预训练工作负载的计算性能约为310 TFLOPS/GPU。
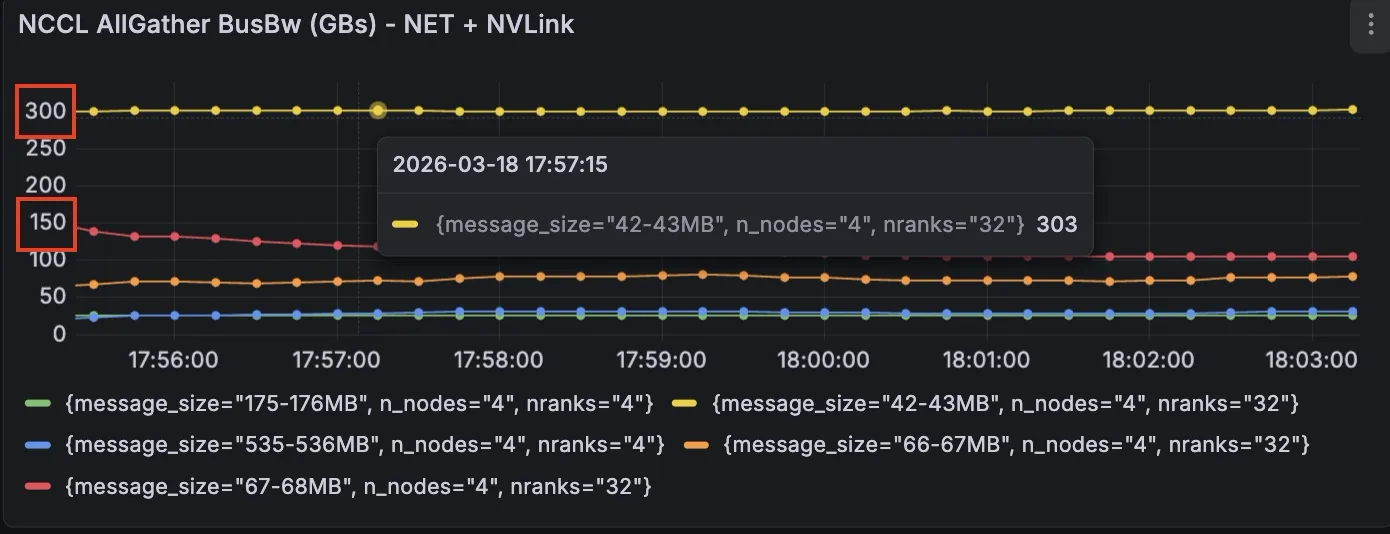
时间轴 B:网络引起的减速
在引入人工网络限制后,用于混合网络+ NVLink 群集的 AllGather BusBw 显示每个 GPU 的计算性能已降低至约 268 TFLOPS (与基准性能相比降低了 13%) 。
此示例显示,实时仪表板提高了混合传输通信器 (network+ NVLink) 之间集合性能的可观察性,从而实现更快的根本原因识别,并缩短平均解决问题的时间。
性能属性
另一个用例是 NCCL Inspector,它可以帮助分析特定时间段内的性能下降。例如,在一项实验中,性能会暂时降低,如下所示:
[2026-03-19 14:39:47.098640] -> throughput per GPU: ~314 TFLOP/s/GPU[2026-03-19 14:40:48.696103] -> throughput per GPU: ~295 TFLOP/s/GPU[2026-03-19 14:42:00.816450] -> throughput per GPU: ~289 TFLOP/s/GPU[2026-03-19 14:44:02.304347] -> throughput per GPU: ~311 TFLOP/s/GPU |
接下来,检查观察到的性能下降,以确定其是否与这一期间的网络异常相关。
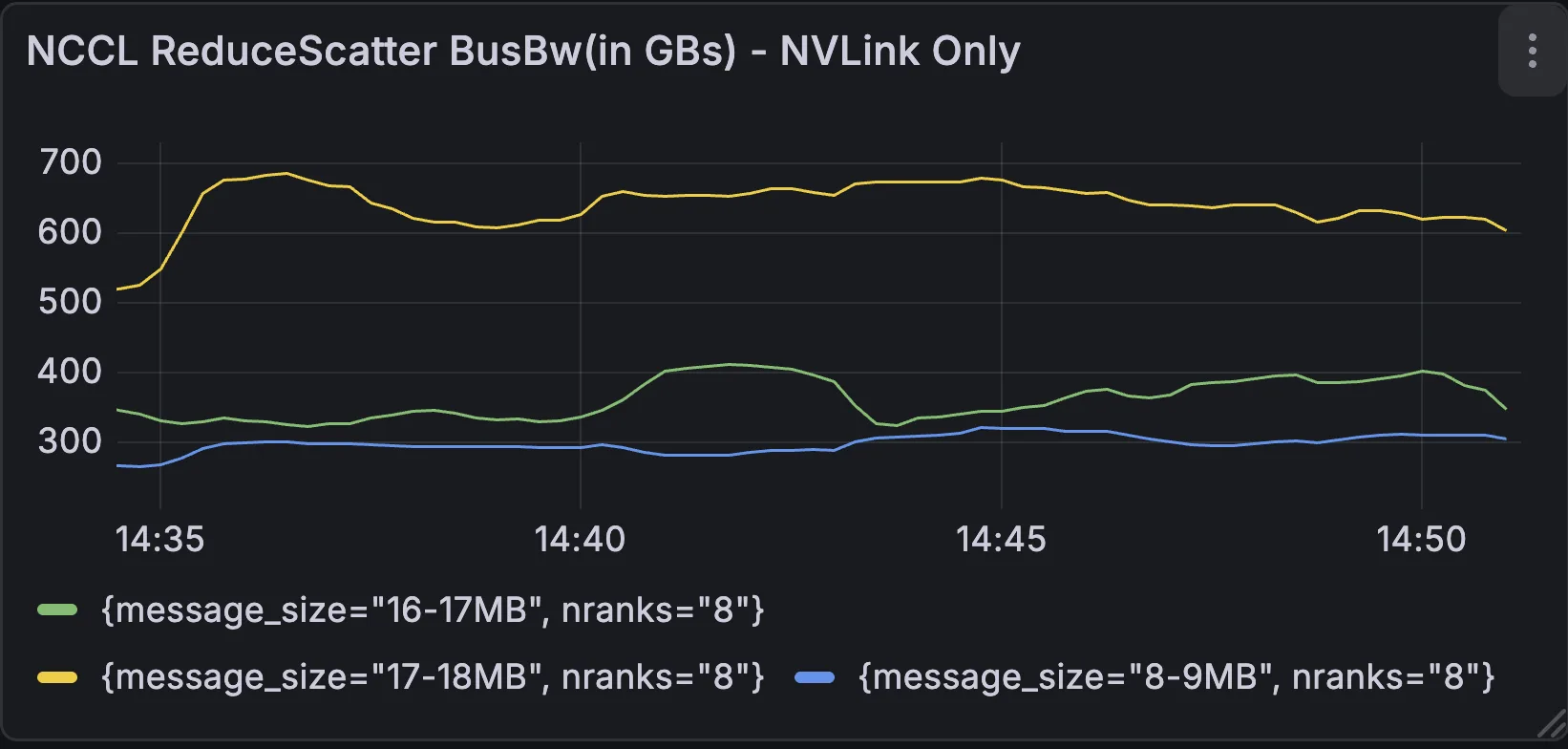
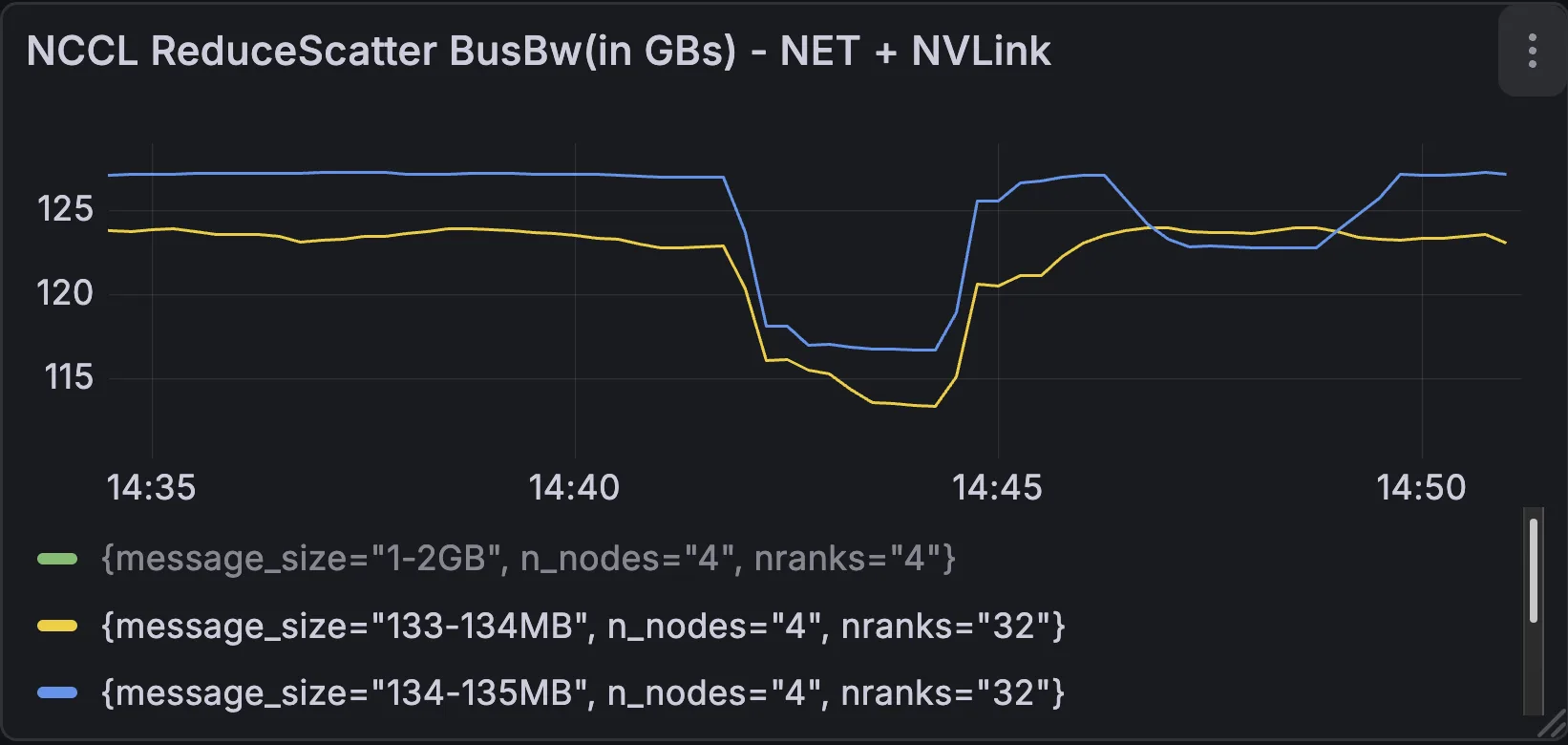
仪表板显示了混合传输通信 (网络+ 基于 NVLink 的群集) 中的性能下降。这种相关性表明,根本原因是网络中断/ 拥塞。这使得我们能够深入研究每个主机和网络计数器,以隔离出现减速的位置。
实现实时可观测性的后续步骤
集成 Prometheus 的 NCCL Inspector 旨在增强 AI 工作负载性能分析的网络可观测性。这种强大的组合有助于采用更科学的性能分析方法。用户可以调试和理解正在运行的工作负载的实时性能特征、分类减速、微调参数,并使用详细的指标测量由此产生的性能变化。
开始使用
请参阅 GitHub README.md以获取:
- 在 Prometheus 模式下构建和部署 NCCL Inspector 插件。
- 配置 Prometheus 导出工具,以显示集群/ 环境的指标。
使用 Grafana 模板 设置 grafana 控制面板。
致谢
我们还要感谢来自加州大学河滨分校的 NVIDIA 同事 Nikhithkumar Kotagari、Giuseppe Congi 和 Nishank Chandawala 以及 Jia Ziyang,感谢他们在设计过程中提供的宝贵投入和评审。