
随着AI模型的规模和复杂性持续提升,要充分发挥现代加速基础设施的性能,关键在于如何合理分配工作负载以及硬件的部署方式。 NVIDIA GB200 NVL72 能在单个机架内提供百亿亿次级计算能力,支持实时运行万亿参数模型。但在共享集群中实现这一性能,需要调度器充分理解系统架构,并将任务与底层网络拓扑结构相匹配。
本文将介绍 Slurm 的拓扑感知作业调度在 NVIDIA GB200 NVL72 上的运行方式,并提供调度建议,以优化 GPU 利用率。
NVIDIA GB200 NVL72 如何提供百亿亿次级计算?
NVIDIA GB200 NVL72 是一款集成于单个机架中的百万兆级计算机。通过目前规模最大的量产纵向扩展架构互联技术 NVIDIA NVLink,72 个 NVIDIA Blackwell GPU 实现互联,为人工智能(AI)和高性能计算(HPC)工作负载提供高达每秒 130 TB(TB/s)的低延迟 GPU 通信带宽。多个 GB200 NVL72 系统在集群中组合,可构建出具备极高网络带宽的大型分层网络拓扑结构。
GB200 NVL72 凭借充足的网络带宽,使 AI 训练任务在调度时能更充分地利用 NVLink 网络。最新结果显示,GB200 NVL72 能显著提升各类 AI 工作负载的性能,包括训练(在最近的 MLPerf 训练中性能提升超过 2.6 倍)、多种推理场景(如 万亿参数模型的实时推理、OAI gpt-oss 模型每秒处理超过 1.5 万个词元、以及 先进的分解服务)和 推理。
在运行多个训练作业的共享集群中,资源高效型调度程序必须考虑到不同的网络带宽要求。
什么是拓扑感知型作业调度?
拓扑感知型作业调度使 Slurm 等作业调度程序能够根据集群的物理网络结构(如交换机和机架的层级)进行资源分配决策。调度程序应尽量保持局部性,优先将工作负载安排在同一 NVLink 域内。此外,由于一组 NVL72 机架可同时运行多个训练或推理任务,调度程序还需具备高效的装箱(Bin-Packing)能力,以避免资源碎片化。
由来已久的 Slurm 拓扑/ 树插件可为大型集群提供拓扑感知型调度,但其尽力而为的方法通常会在 Leaf 交换机中分割作业,以减少队列时间。虽然对于传统的 InfiniBand 网络而言,在启动时间和性能之间实现这种折衷是可以接受的,但 GB200 NVL72 和 GB300 NVL72 等机架级系统的出现必然会带来一些变化。为此,NVIDIA 和 SchedMD 合作,在 Slurm 23.11 中推出了专为这些现代架构设计的新拓扑/ 块插件。
此拓扑插件配置提供了属于同一 NVL72 域的节点组信息,从而支持启用可将 Slurm 作业与 NVL72 域边界对齐的调度算法。有关块拓扑插件及段大小调度的更多详情,请参阅 借助 Slurm 块调度在 NVIDIA GB200 NVL72 上实现系统和工作负载峰值效率。
集群分割和作业调度如何在 GB200 NVL72 上进行?
随着集群的规模和复杂性不断增加,管理 GPU 资源对于实现高利用率和可预测的性能至关重要。GB200 NVL72 系统引入了更大的 AI 作业细分规模和精细的调度控制,使运营商能够根据工作负载需求调整细分配置。结合 Slurm 工作负载管理器中可感知 GB200 NVL72 的调度扩展,这种方法能够平衡大小作业,即使在发生硬件故障时也能更大限度地提高效率。
GB200 NVL72 如何支持更大的段大小?
在多 GPU 工作负载中,作业段大小定义了由节点组成的子单元,这些节点可以完全通过 NVLink 相互通信。图 1 说明了如何使用段数 (Y) 和段长 (S) 来定义分配给特定作业的 GPU。对于 GB200 和 GB300,每个节点的 GPU 数量 (G) 始终为 4。
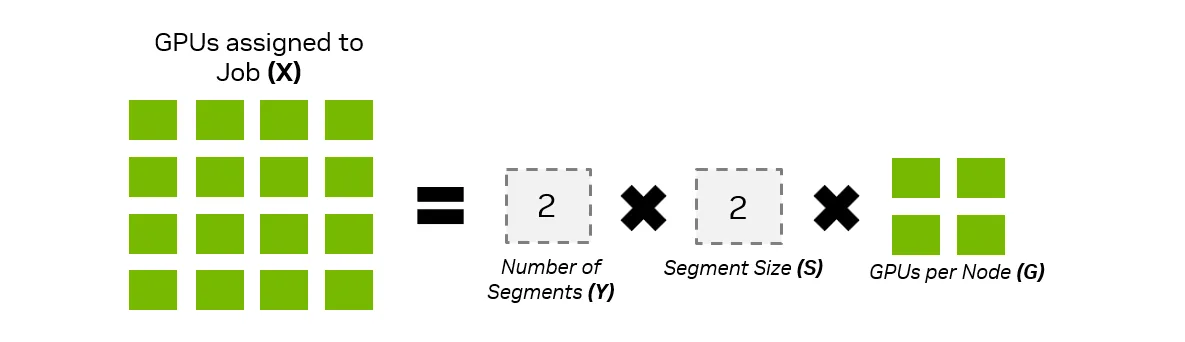
在以前的系统 (例如 NVIDIA HGX H100) 中,作业仅限于一个节点的段大小。GB200 NVL72 系统支持更大的段大小 (最多 18 个节点) ,同时还能高效地将段作为单节点提供支持。
给定应用程序的最佳分割大小取决于模型类型和用于训练的并行类型组合等因素。通常,规模较大的作业 (使用更多 GPU 的作业) 和 I/ O 带宽要求较高的作业 (例如混合专家 (MoE) 训练) 会受益于更大的细分规模。相反,较小的作业通常具有较低的 I/ O 带宽需求,并且应使用较小的段大小,以防止过度限制集群调度程序。如果不确定,用户应针对其特定工作负载验证此指南,因为性能影响可能因工作负载而异。
GB200 NVL72 段大小调整的最佳实践是什么?
在建模方面,我们的团队发现了一些最大化 GB200 NVL72 集群利用率的一般准则。经验法则是选择使用 16 个节点的“大”段大小的关键作业大小,以便这些作业在集群中的 GPU 小时百分比 < 90%。这将为调度程序提供灵活性,使其能够充分利用具有良好分段大小组合的集群。表 1 总结了一些推荐的最佳配置。
| 职位规模 | 片段大小 | 工作负载示例 |
| 128 | 16 | MoE 模型训练 |
| 32 – 64 | 4 | 大型密集模型训练 |
| 32 岁以下 | 1 | 小型模型训练 |
请注意,就本文而言,我们假设用户作业更倾向于使用两种 GPU 细分大小 (例如,4 个节点+ 16 个 GPU) 来运行。您还可以选择其他分段大小 (例如,每个分段 12、36 或 72 个 GPU) 。要确定替代方法是否有意义,请研究在非“两”段大小中映射作业的效率,以及不同规模作业对集群整体利用率的影响。
如何在 GB200 NVL72 系统上调度作业
NVIDIA 和 SchedMD 开发了基于 Slurm 的块调度扩展,可实现 GB200 NVL72 感知的作业放置,从而实现高利用率。
凭借双段功率大小,GB200 NVL72 集群可以并行运行大小不一的作业,例如使用 16 个节点段的 512 个 GPU 作业和使用单节点段的多个 16 个 GPU 作业。这些调度策略可最大限度地减少碎片化,同时在整个集群中保持高效率。
什么是 GB200 NVL72 调度仿真框架?
为了大规模评估调度策略,我们开发了一个独立的 Slurm 模拟器,该模拟器在虚拟机上运行,并实现了时间加速的工作负载模拟。如图 2 所示,此模拟器通过以下方式提供准确且可重复的结果:
- 运行 Slurm 代码
- 回放生产工作负载或生成合成工作负载
- 模拟真实条件,包括节点故障和恢复
- 与指标系统集成,直接比较结果
在将新调度策略部署到生产环境中之前,此设置可提供重要的优势来测试、比较和自信地推出这些策略。
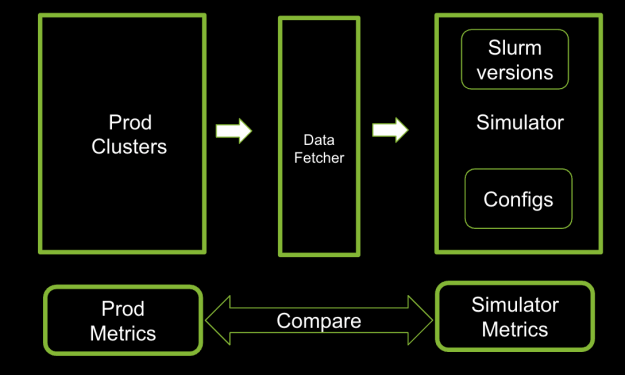
仿真参数
该团队建模的仿真环境参数包括:
- 集群容量: 5000 个 GB200 NVL72 节点 ( 20000 个 GPU)
- 工作负载: 7 天内完成 15000 项作业
- 可靠性: 在任何给定时间内平均降低 2.5%的节点
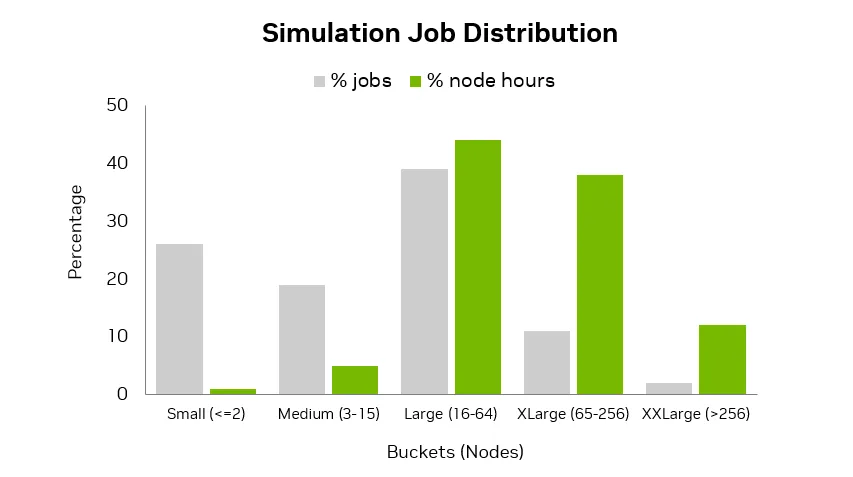
该团队使用 Large_Perf_Custom 策略评估性能,该策略旨在平衡利用率和大型作业性能:
- 包含 32 个或更多节点的作业运行时的段大小为 16
- 以段大小为 2 运行较小的作业
仿真结果显示了什么?
为评估新调度策略的性能,我们重点关注两个关键的主要集群指标:块的碎片化和整体 GPU 占用率。
碎片分析
GB200 NVL72 调度的一个关键指标是小型作业如何影响大型作业的 NVLink 域可用性。该模拟器跟踪了小型作业 ( 1-18 个节点) 在每个 NVLink 域中的放置方式。
关键发现是,拓扑插件有效地将小作业放置在每个域的最后两个节点上,从而最大限度地减少碎片化,并为更大的作业保留容量。
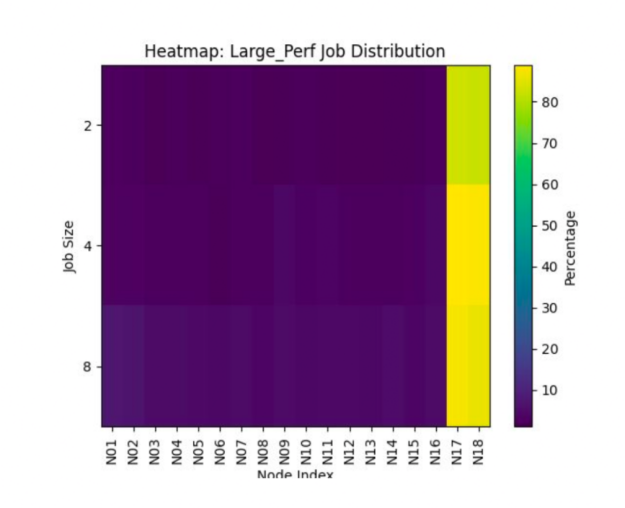
占用率指标
虽然拓扑感知型调度引入了限制条件,但我们的结果表明,通过优化拓扑感知型调度实现,几乎可以完全消除其对整体占用率的影响。图 5 仅显示 Large_Perf_Custom 与 NoTopo 之间约 1% 的差异。可以用更多的小型作业进一步填补空白。
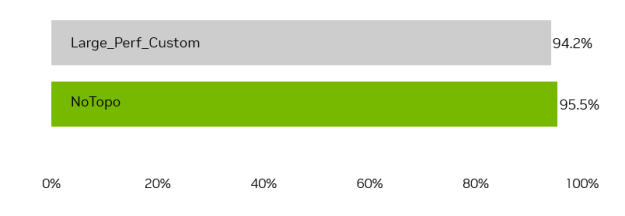
我们将开发的 Large_Perf_Custom 算法下的占用率与无 Topo 策略进行了比较,后者的无 Topo 配置表示给定作业大小分布下的最佳理论占用率,而忽略了因在无 Topo 算法中放置不当而导致的大量运行时损失。实际目标是尽可能接近无拓扑占用率,同时避免拓扑朴素调度带来的性能损失。
结果表明,我们的仿真实现的占用率约为 noTopo 的 1%,这表明拓扑感知调度可以在不牺牲性能的情况下实现高利用率。
GB200 NVL72 的最佳作业调度方法是什么?
根据我们的模拟结果和性能测试,我们建议 NVIDIA GB200 NVL72 集群采用调度方法,在保持高利用率的同时,优先考虑大型作业的性能。对于 64 个或更多 GPU 的大型作业,应允许其访问 NVLink 域的最大数量,并使用分段大小来确保跨域的 GPU 分配比例。基于段的调度对于根据工作负载模式调整资源至关重要。对于包含 32 个或更多节点的作业,如果应用能够从中受益,建议将段大小设为 16,而较小的作业更适合 2 到 8 的段大小,具体取决于工作负载特性。
为了不断提高效率,必须不断进行监控和优化。跟踪碎片化指标,随着工作负载模式的演变调整分段大小,并在生产部署之前使用仿真工具验证更改,这有助于在不牺牲性能的情况下保持高利用率。虽然块拓扑可能会引入降低占用率的约束条件,但应用战略调度策略可以减轻这种影响并保持性能优势。
开始使用 NVIDIA GB200 NVL72
NVIDIA GB200 NVL72 系统标志着 AI 与高性能计算领域的重要突破。要充分释放其潜力,必须具备拓扑感知的调度能力。我们的建模结果显示,通过简单的配置和基于拓扑段的调度策略,可在维持高集群利用率的同时实现最优性能。通过模拟多种调度场景,我们能够更有信心地部署新策略,而无需承担影响生产工作负载的风险。 深入了解 NVIDIA GB200 NVL72。